Trajectory Editing for SFT/DPO
Annotators rewrite the steps of an agent trace to fix a wrong reasoning step, correct a tool call, or strengthen the final answer, and Potato exports each original/corrected pair as supervised fine-tuning targets and DPO preference pairs.
The trajectory_edit schema lets annotators rewrite the steps of an agent trace, and exports each correction as training data. Fix a wrong reasoning step, correct a typo'd tool call, or strengthen the final answer, and Potato saves the corrected trajectory next to the original. The trajectory_correction exporter then turns each (original, corrected) pair into supervised fine-tuning (SFT) targets and direct preference optimization (DPO) preference pairs.
This makes Potato a training-data production tool, not only an evaluation tool. It is the editing counterpart to step-level scoring: instead of rating a trajectory, annotators repair it, and the repair becomes a learning signal.
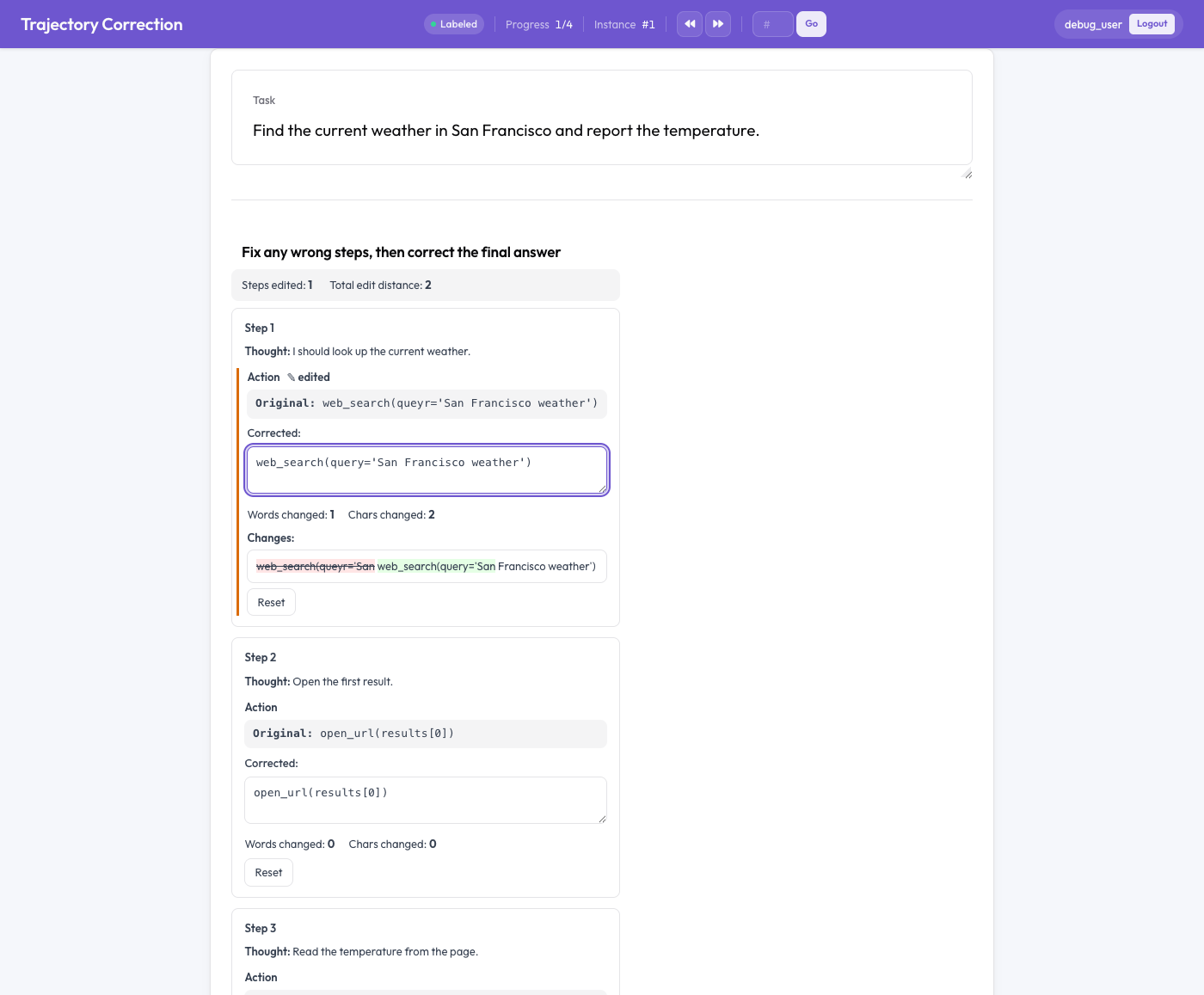 An agent step shown with a read-only original and an editable corrected box with a word-level diff
An agent step shown with a read-only original and an editable corrected box with a word-level diff
Quick start
Run the included example from the repository root:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000How it works
Each agent step renders as a card showing the original text (read-only) and an editable corrected box pre-filled with the original. As the annotator types:
- a live word-level diff highlights insertions (green) and deletions (red strikethrough),
- the words and characters changed are counted, and
- an "edited" flag appears on changed fields.
A "Reset" button restores the original per field. With edit_final_answer: true the final answer gets its own editor. Nothing is required: an unedited trace simply produces no training pair.
Configuration
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer| Option | Default | Description |
|---|---|---|
steps_key | steps | Instance field holding the step list. |
step_text_key | action | Default editable field per step. |
editable_fields | [step_text_key] | Which step fields get an editor, e.g. [action, thought]. |
show_diff | true | Show the live word-level diff. |
show_edit_distance | true | Show words and characters changed. |
allow_reset | true | Per-field "Reset to original" button. |
require_reason_on_edit | false | Per-field "reason for edit" input. |
edit_final_answer | false | Add an editor for the final answer. |
final_answer_key | final_answer | Instance field holding the final answer. |
Data format
The schema reads steps from the instance under steps_key. Each step is an object whose fields (action, thought, and so on) can be edited; bare-string steps are edited as the step_text_key field.
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}Export
Run the trajectory_correction exporter. It writes three files:
trajectory_corrections.json— every record: theoriginal_trace, the reconstructedcorrected_trace, and per-fieldeditswith edit distances and reasons.trajectory_sft.jsonl— one line per edited trace:{"prompt": <task>, "completion": <corrected_trace>}.trajectory_dpo.jsonl— one line per edited trace:{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}.
Unedited traces are counted but excluded from SFT/DPO, since training on an unchanged trajectory adds nothing; the skipped count appears in the export stats. With multiple annotators, each annotator who edited a trace yields one SFT/DPO record.
Notes and limitations
- The diff is word-level. For code-like tool calls with no spaces, a single token may show as wholly changed even for a one-character fix; the character-distance counter is the precise signal.
- Pair with step-level scoring if you also want per-step correctness or an error taxonomy on the same trace.
Related
- Three-Pane Trace Evaluation — read-only reasoning, calls, and answer view
- Agentic Annotation — agent-trace display and evaluation patterns
- Export Formats — the full exporter reference
For implementation details, see the source documentation.