Judge ↔ Human Alignment
Measure how well an LLM judge agrees with your human gold labels. Potato runs the judge over annotated instances, computes Cohen's kappa, a confusion matrix, and a disagreement list, and tracks agreement as you refine the rubric.
Judge Alignment measures and tunes how well an LLM judge agrees with your human gold labels. Potato runs a configurable LLM-as-a-judge over instances your annotators have already labeled, computes Cohen's κ, a confusion matrix, and a disagreement list, and tracks κ as you edit the judge rubric. With inline mode on, the judge's verdict appears beside the human label during annotation, with a running κ.
This is the standard "align your judge to roughly 100–200 gold labels" loop used by tools like LangSmith Align Evals and Evidently: collect human labels, run the judge, inspect disagreements, refine the rubric, and re-run until agreement is high.
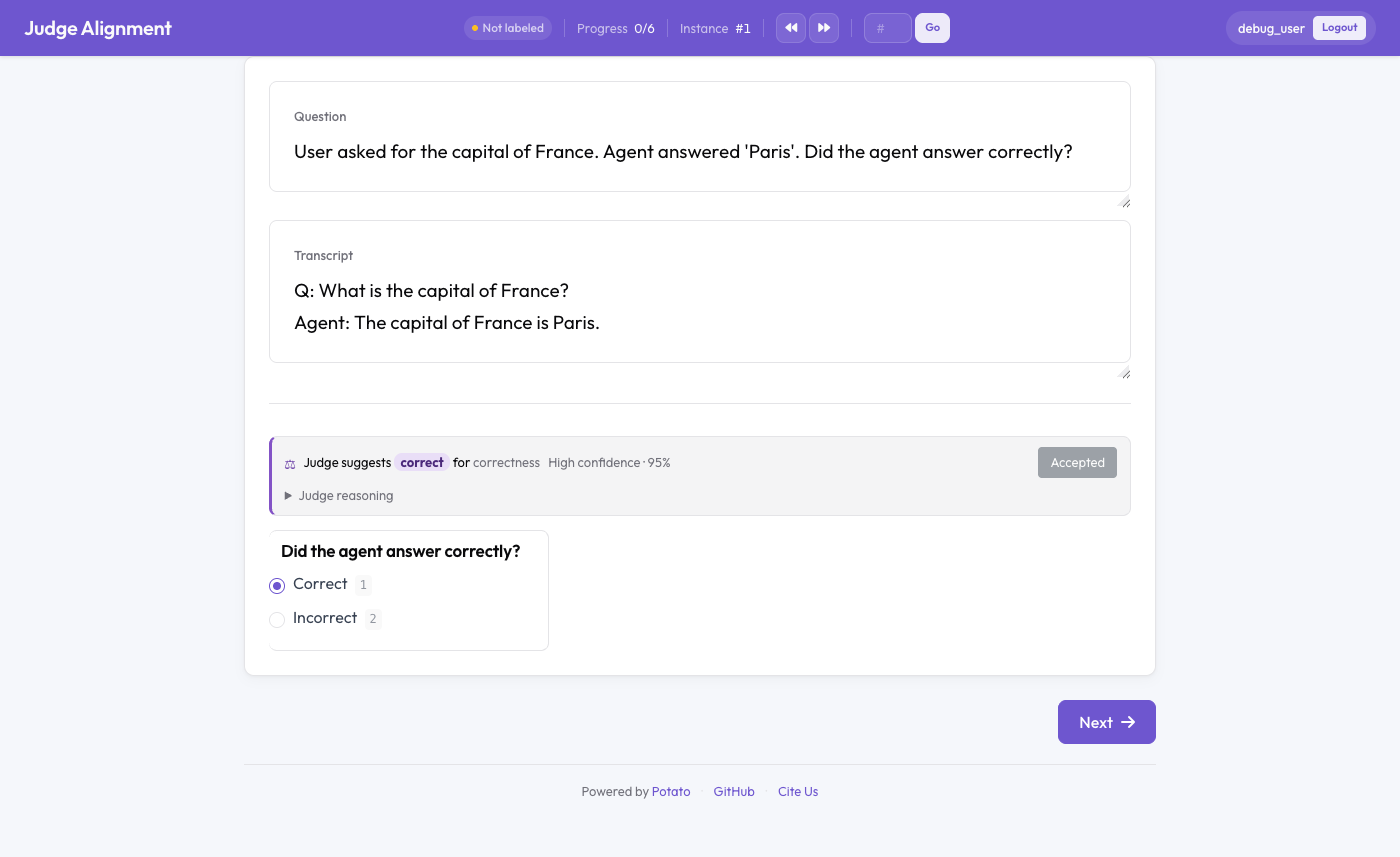 An LLM judge verdict shown next to the human annotation with a running kappa
An LLM judge verdict shown next to the human annotation with a running kappa
Configuration
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict existsScope is single-choice categorical schemes (radio, select, likert). If judge_alignment.schemas is set, only those schemes are judged; otherwise all categorical schemes are.
Running the judge
Run the judge from the admin API. Predictions are cached per prompt version, so re-runs are cheap:
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'To calibrate, pass an edited rubric. That creates a new prompt version, so you can compare κ across rounds:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'The alignment report
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
Send the X-API-Key header. Per schema, the report shows:
- Cohen's κ with a Landis–Koch interpretation, the agreement rate, and the number of instances compared.
- A confusion matrix (rows are human gold, columns are the judge).
- A disagreement table with the instance, human label, judge label, confidence, and judge reasoning.
- Prompt-version history with mean κ per version, so calibration progress is visible.
Human gold is the majority vote across annotators for each instance.
Inline mode
With inline.enabled, each annotation page shows the judge's cached verdict for the instance — its label, confidence, and expandable reasoning — alongside a running κ for the task. "Accept" fills the matching choice. Every human save records a human↔judge comparison that feeds the running agreement. Set compute_on_demand: true to call the judge live when no cached verdict exists; otherwise pre-run the batch, which is faster.
Notes and limitations
- Calibration is manual in this version: edit the rubric and re-run. Automated prompt optimization is out of scope.
- Scope is single-choice categorical schemes. Span and free-text judging is future work.
- Run the judge over a focused gold set of roughly 100–200 labeled instances for a stable κ.
Related
- LLM-as-Judge Calibration — multi-judge, blind-human calibration with calibration error
- Triage Queue — route the most informative items to humans first
- Inter-annotator agreement guide — the kappa metrics in depth
For implementation details, see the source documentation.