Confidence Annotation
Add confidence ratings paired with other annotations in Potato using Likert scales or sliders to capture annotator certainty.
The confidence annotation schema lets annotators rate their confidence in another annotation they have made. It pairs a confidence scale (Likert or slider) with a target annotation schema, enabling researchers to measure not just what annotators chose but how certain they were about their choice.
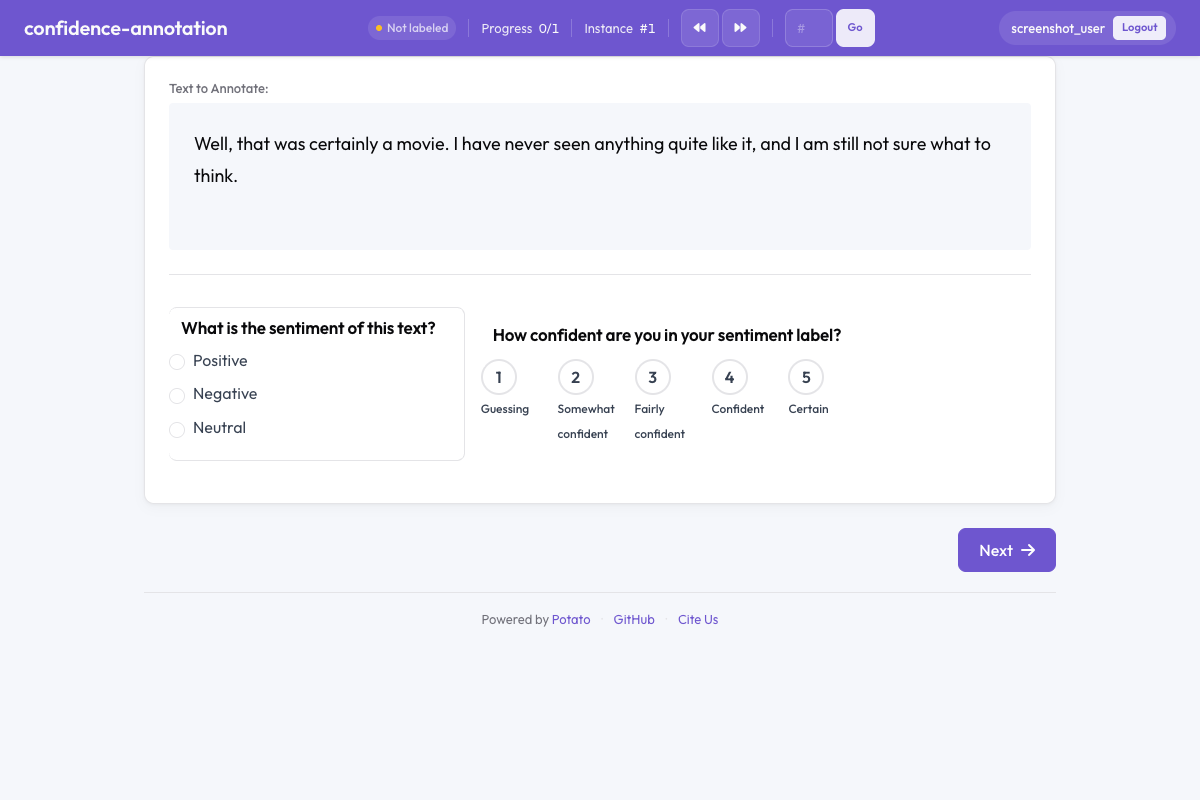 Confidence annotation in Potato
Confidence annotation in Potato
Overview
Confidence annotations are essential for studying annotation quality, identifying ambiguous items, and weighting labels during aggregation. When configured, a confidence rating widget appears alongside the target annotation, prompting annotators to indicate how sure they are of their decision.
Quick Start
annotation_schemes:
- annotation_type: radio
name: sentiment
description: What is the sentiment of this text?
labels: ["Positive", "Negative", "Neutral"]
- annotation_type: confidence
name: sentiment_confidence
description: How confident are you in your sentiment label?
target_schema: sentiment
scale_type: likert
scale_points: 5Configuration Options
| Field | Type | Default | Description |
|---|---|---|---|
annotation_type | string | Required | Must be "confidence" |
name | string | Required | Unique identifier for this schema |
description | string | Required | Instructions displayed to annotators |
target_schema | string | Optional | Name of the annotation schema this confidence rating applies to |
scale_type | string | "likert" | Type of scale: "likert" for discrete points or "slider" for continuous |
scale_points | integer | 5 | Number of points on the Likert scale (ignored for slider) |
labels | array | Optional | Custom labels for scale points (e.g., ["Not confident", "Very confident"]) |
slider_min | integer | — | Minimum value for the slider (only used when scale_type is "slider") |
slider_max | integer | — | Maximum value for the slider (only used when scale_type is "slider") |
label_requirement.required | boolean | false | Whether the confidence rating must be completed before moving on |
Examples
Likert Confidence Scale
annotation_schemes:
- annotation_type: radio
name: toxicity
description: Is this comment toxic?
labels: ["Toxic", "Not Toxic"]
- annotation_type: confidence
name: toxicity_confidence
description: How confident are you in your toxicity judgment?
target_schema: toxicity
scale_type: likert
scale_points: 5
labels: ["Not at all confident", "Slightly confident", "Moderately confident", "Very confident", "Extremely confident"]Slider Confidence Scale
annotation_schemes:
- annotation_type: radio
name: stance
description: What stance does the author take?
labels: ["Support", "Oppose", "Neutral"]
- annotation_type: confidence
name: stance_confidence
description: Rate your confidence from 0 (guessing) to 100 (certain).
target_schema: stance
scale_type: slider
slider_min: 0
slider_max: 100Required Confidence Rating
annotation_schemes:
- annotation_type: multiselect
name: topics
description: Select all topics that apply.
labels: ["Politics", "Economy", "Health", "Education"]
- annotation_type: confidence
name: topics_confidence
description: How confident are you in your topic selections?
target_schema: topics
scale_type: likert
scale_points: 3
labels: ["Low", "Medium", "High"]
label_requirement:
required: trueStandalone Confidence (No Target)
Confidence annotations can also be used without a target schema for general self-assessment:
annotation_schemes:
- annotation_type: confidence
name: task_familiarity
description: How familiar are you with this topic area?
scale_type: likert
scale_points: 5
labels: ["Not familiar", "Slightly familiar", "Somewhat familiar", "Very familiar", "Expert"]Output Format
{
"toxicity_confidence": {
"labels": {
"confidence": 4
}
}
}For Likert scales, values range from 1 to scale_points. For sliders, values range from slider_min to slider_max.
Best Practices
- Always pair with a target schema - confidence ratings are most useful when linked to a specific annotation decision
- Use Likert for simplicity - discrete scales are faster and easier for annotators to use
- Use sliders for fine-grained measurement - when you need precise confidence values for downstream analysis
- Make confidence required - optional confidence ratings often get skipped, reducing data utility
- Analyze confidence patterns - low-confidence items are good candidates for adjudication or additional annotations
Further Reading
- Likert Scales - Ordinal rating scales
- Slider - Continuous value annotation
- Quality Control - Attention checks and gold standards
For implementation details, see the source documentation.