Error Span
Build MQM-style error annotation interfaces in Potato for translation quality evaluation, text error marking, and typed error span annotation with severity scoring.
The error span annotation schema provides an MQM-style (Multidimensional Quality Metrics) interface for marking errors in text with typed categories and severity levels. This schema is ideal for translation quality evaluation, text editing review, content quality assessment, and any task requiring fine-grained error annotation.
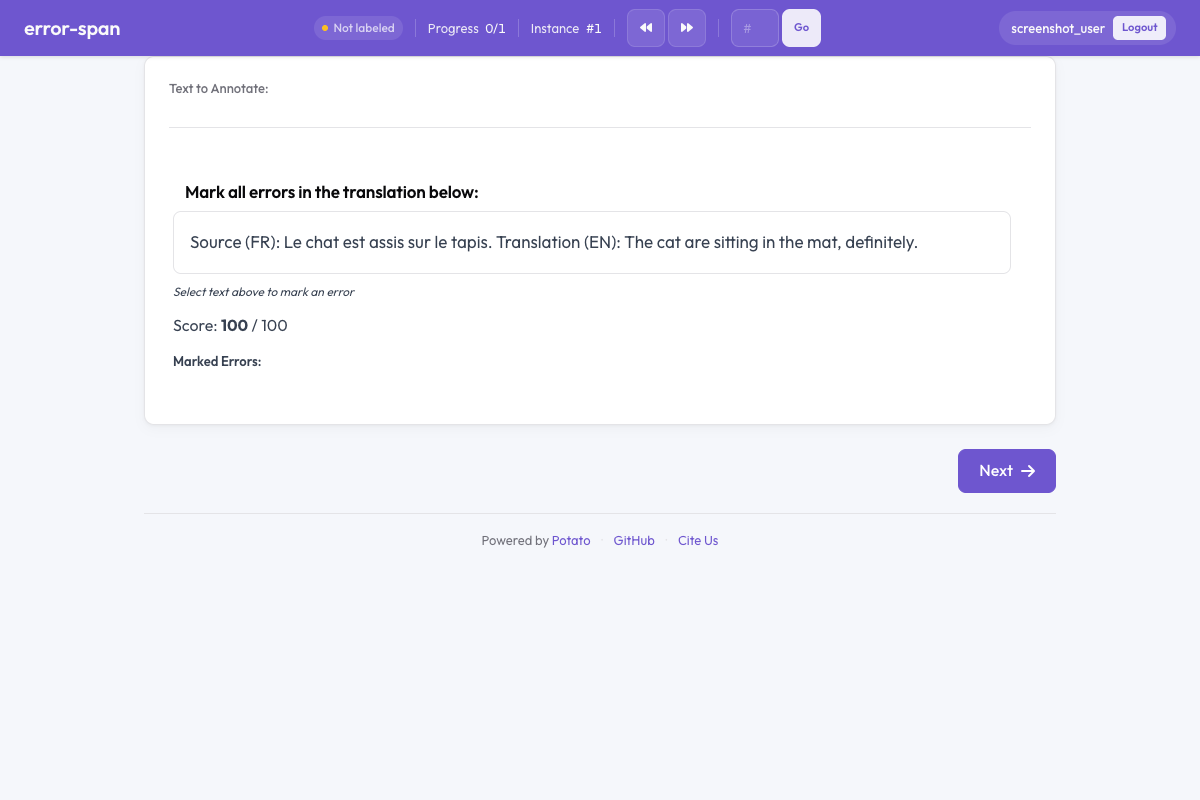 Error span in Potato
Error span in Potato
Overview
The error span schema provides:
- Typed error categories with optional subtypes for detailed classification
- Severity levels with configurable point deductions
- Running quality score that decreases as errors are marked
- Color-coded spans that visually distinguish error types and severities
Annotators select text spans, assign an error type and severity, and the system automatically computes a quality score.
Quick Start
annotation_schemes:
- annotation_type: error_span
name: translation_errors
description: Mark all errors in the translation below.
error_types:
- name: Accuracy
- name: Fluency
- name: Terminology
show_score: true
max_score: 100Configuration Options
| Field | Type | Default | Description |
|---|---|---|---|
annotation_type | string | Required | Must be "error_span" |
name | string | Required | Unique identifier for this schema |
description | string | Required | Instructions displayed to annotators |
error_types | array | Required | List of error type objects, each with name and optional subtypes array |
severities | array | [{name: "Minor", weight: -1}, {name: "Major", weight: -5}, {name: "Critical", weight: -10}] | List of severity levels with name and weight (point deduction) |
show_score | boolean | true | Display a running quality score |
max_score | integer | 100 | Starting quality score before deductions |
Examples
Translation Quality (MQM)
annotation_schemes:
- annotation_type: error_span
name: mqm_errors
description: >
Mark all errors in the machine translation.
Select the error span, choose a category and severity.
error_types:
- name: Accuracy
subtypes:
- Mistranslation
- Addition
- Omission
- Untranslated
- name: Fluency
subtypes:
- Grammar
- Spelling
- Punctuation
- Register
- name: Terminology
subtypes:
- Inconsistent
- Wrong Term
- name: Style
severities:
- name: Minor
weight: -1
- name: Major
weight: -5
- name: Critical
weight: -10
show_score: true
max_score: 100Content Editing Review
annotation_schemes:
- annotation_type: error_span
name: editing_errors
description: Mark all issues that need editing in this article.
error_types:
- name: Factual Error
- name: Grammar
subtypes:
- Subject-Verb Agreement
- Tense
- Pronoun Reference
- name: Style
subtypes:
- Wordiness
- Passive Voice
- Jargon
- name: Formatting
severities:
- name: Suggestion
weight: -1
- name: Required Fix
weight: -5
show_score: falseCode Review Annotation
annotation_schemes:
- annotation_type: error_span
name: code_errors
description: Mark issues in this code snippet.
error_types:
- name: Bug
subtypes:
- Logic Error
- Off-by-One
- Null Reference
- name: Style
subtypes:
- Naming
- Formatting
- name: Security
subtypes:
- Injection
- Exposure
- name: Performance
severities:
- name: Nitpick
weight: -1
- name: Warning
weight: -3
- name: Blocker
weight: -10
max_score: 100
show_score: trueOutput Format
{
"translation_errors": {
"labels": {
"errors": [
{
"start": 12,
"end": 25,
"text": "incorrectly translated",
"error_type": "Accuracy",
"subtype": "Mistranslation",
"severity": "Major"
},
{
"start": 45,
"end": 52,
"text": "the the",
"error_type": "Fluency",
"subtype": "Grammar",
"severity": "Minor"
}
],
"score": 94
}
}
}The score is computed as max_score plus the sum of all severity weights.
Best Practices
- Define clear error type boundaries - annotators should not struggle to decide between two error types; provide examples in the description
- Use subtypes for granularity - top-level types keep the interface simple while subtypes allow detailed analysis when needed
- Calibrate severity weights carefully - the weight ratios should reflect actual impact; a critical error should be meaningfully more costly than a minor one
- Set max_score relative to text length - for short texts, a lower max_score prevents single errors from having outsized impact
- Provide annotation guidelines - MQM-style annotation benefits greatly from detailed guidelines with examples of each error type and severity
Further Reading
- Span Annotation - General span labeling
- Span Linking - Linking related spans
- Quality Control - Attention checks and gold standards
For implementation details, see the source documentation.