Multi-Agent Team Evaluation
Annotate multi-agent systems by team structure, not a flat transcript. Potato adds a clickable agent-interaction graph, cross-agent failure attribution, handoff review, per-agent and per-team scorecards, a tool-contention timeline, and emergent-behavior tagging.
A multi-agent system fails differently than a single agent: the breakdown happens between agents, at a handoff, or in how the team was organized. Evaluating one means attributing outcomes to which agent, which step, and which handoff, not just scoring a flat transcript. Potato adds a set of annotation surfaces built for that: a clickable interaction graph, failure attribution, handoff review, per-agent and per-team scorecards, a tool-contention timeline, and cross-lane emergent-behavior tagging.
These build on the agent-trace display and the MAST failure taxonomy. Each schema derives its agents, steps, and handoffs from the trace itself at render time, so the annotator chooses from what actually happened in the run.
Interaction graph (agent_interaction_graph)
The whole run renders as a directed graph: nodes are agents, edges are the message and handoff transitions between them (thicker edges mean more frequent), laid out automatically from the trace. The annotator clicks a node to mark the critical path and clicks an edge to cycle it normal → critical → problematic. This is the clearest answer to "how do I see the structure of a multi-agent run," and it is a surface general annotation tools do not offer.
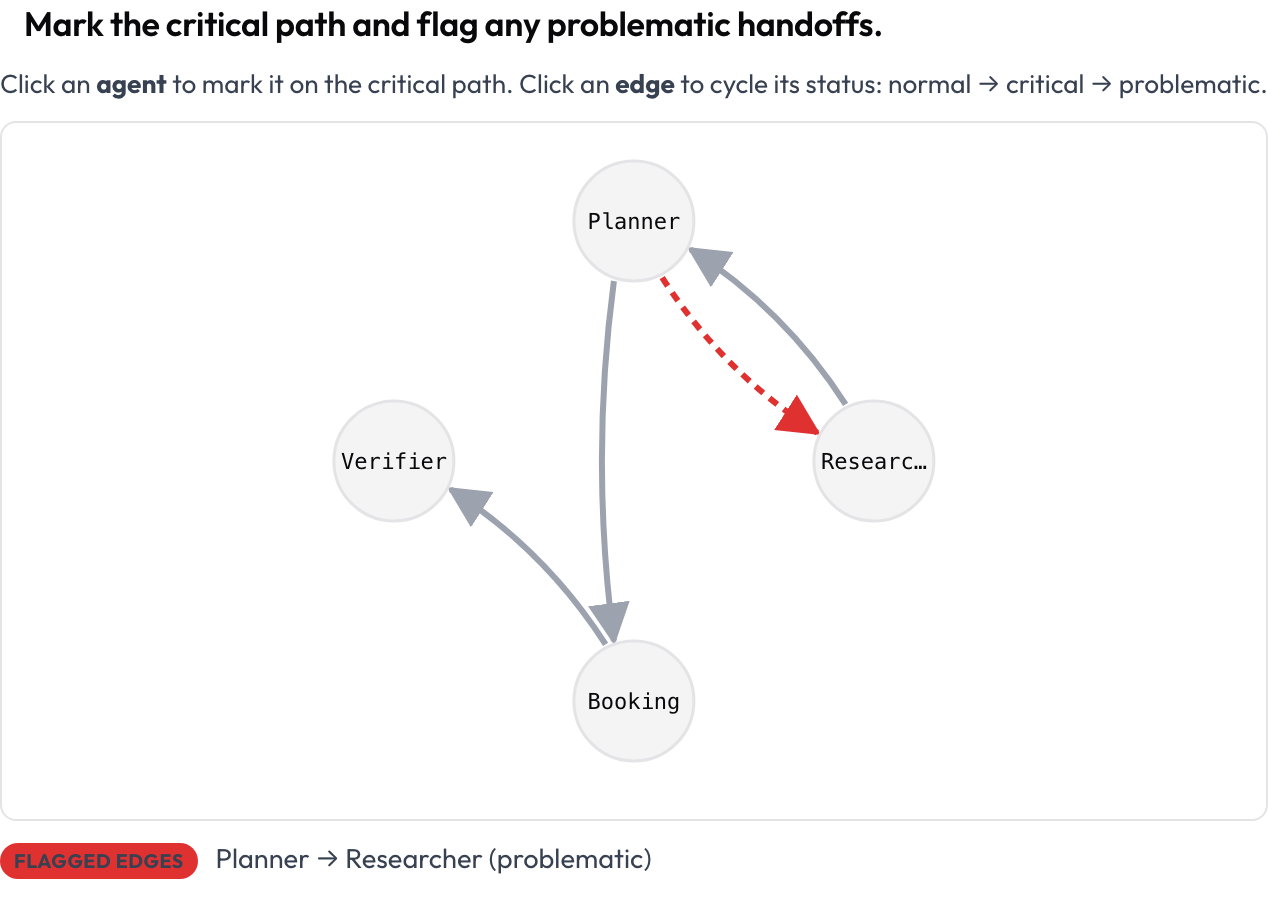 Mark the critical path and flag problematic handoffs on a clickable agent-interaction graph
Mark the critical path and flag problematic handoffs on a clickable agent-interaction graph
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentStored as {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}. Every node and edge is keyboard-focusable and a live text summary lists critical nodes and flagged edges, so meaning is never carried by color alone.
Cross-agent failure attribution (failure_attribution)
When a team fails, the useful label is the (responsible agent, decisive step, reason) triple from the failure-attribution literature (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, the Who&When dataset). The agent dropdown and step picker are populated from the trace's own turns, so the annotator attributes the failure to a real agent and a real step.
 Attribute a multi-agent failure to the responsible agent, the decisive step, and why
Attribute a multi-agent failure to the responsible agent, the decisive step, and why
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the traceStored as {"responsible_agent", "decisive_step", "reason"}. Pair it with a radio outcome scheme (success/failure) so attribution only fires on failed runs.
Handoff review (handoff_review)
Every handoff, one agent passing control to another, becomes a first-class object to annotate. Wherever the acting agent changes between consecutive turns, Potato emits a handoff card A → B; the annotator flags inter-agent misalignment and rates the handoff quality. The failure modes are grounded in MAST's inter-agent category and the "echoing" phenomenon (Zhang et al., 2025).
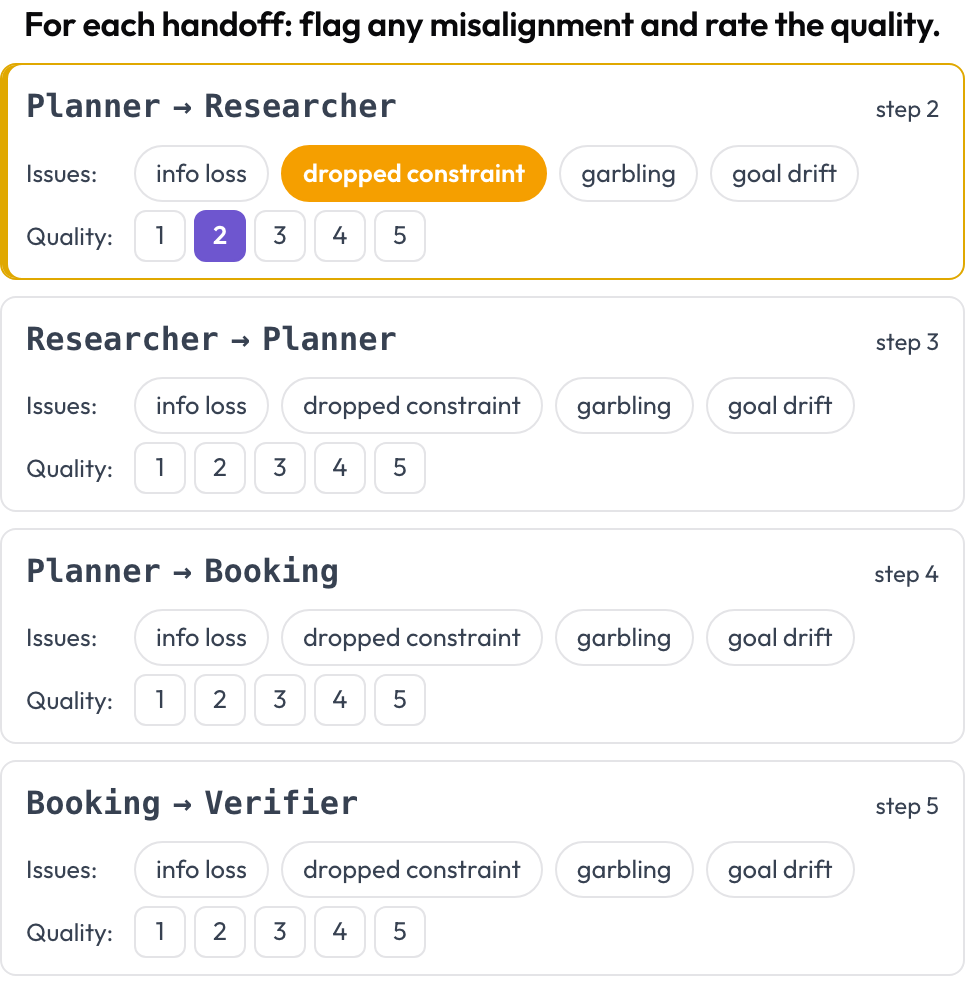 Flag inter-agent misalignment on every handoff and rate its quality
Flag inter-agent misalignment on every handoff and rate its quality
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Handoffs are derived from the trace at render time, so there is no manual setup. Stored as a list of {index, step, from, to, flags, quality}.
Per-agent and per-team scorecard (agent_scorecard)
Score a run on two levels at once (MultiAgentBench, Zhou et al., ACL 2025): each agent gets per-dimension scores (role fidelity, contribution, coordination), the team gets shared-dimension scores, and optional milestones are checked off. Agent rows come from the trace's own turns, so the matrix matches who actually participated.
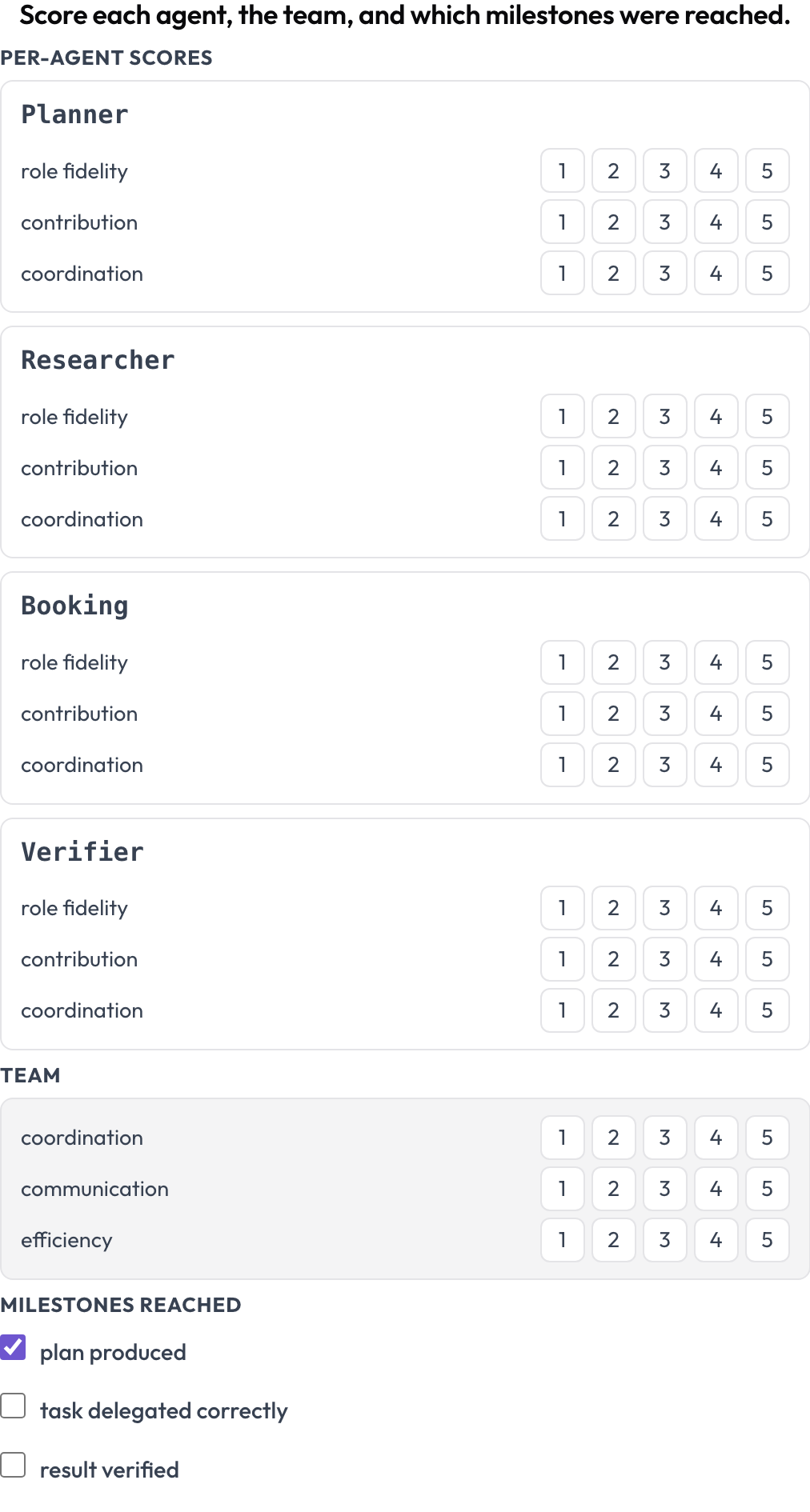 Score every agent on role fidelity, contribution, and coordination, plus the team and milestones
Score every agent on role fidelity, contribution, and coordination, plus the team and milestones
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optionalStored as {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}.
Tool / resource-contention timeline (tool_contention)
Concurrent tool and resource use across agents renders on a multi-lane timeline, one lane per agent. Regions where two calls touch the same resource at overlapping times are highlighted across lanes and listed for classification: deadlock, circular wait, race condition, or benign (DPBench, 2026). This is how you catch concurrency failures that a per-turn transcript hides.
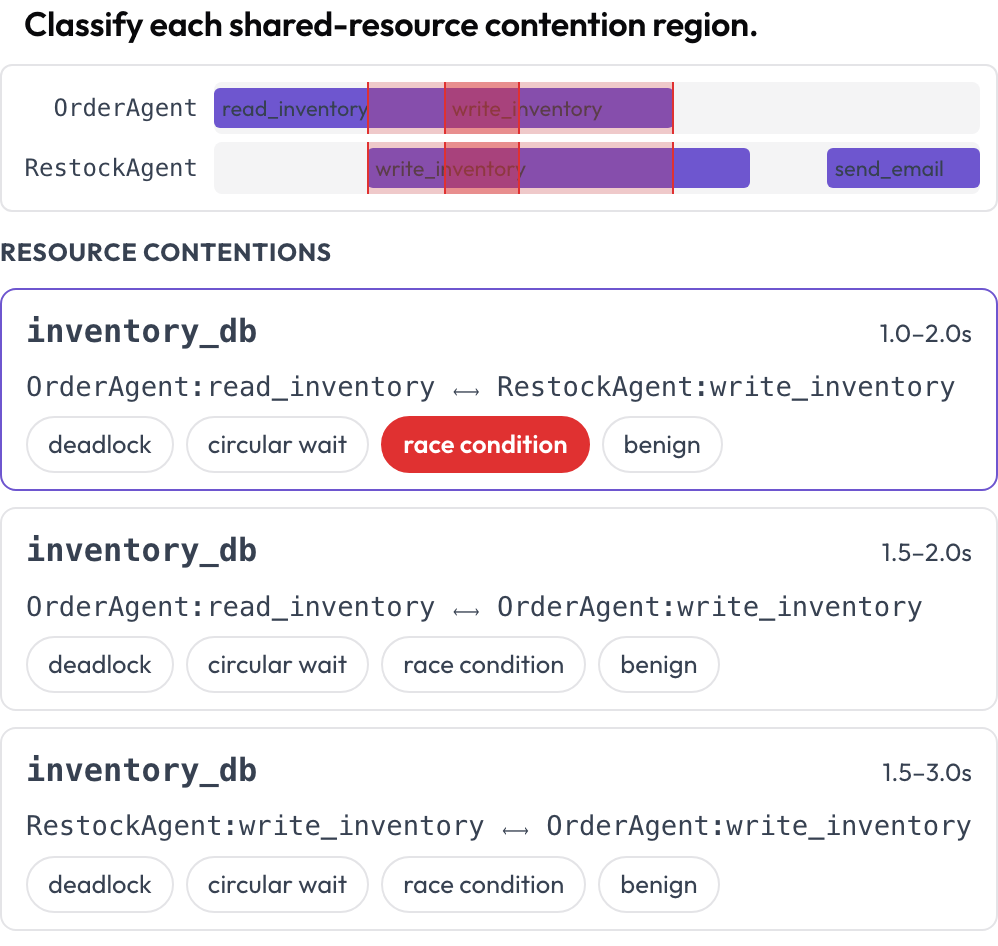 Spot deadlocks and race conditions on a per-agent tool-call timeline
Spot deadlocks and race conditions on a per-agent tool-call timeline
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]Contention regions are computed at render time (same resource, overlapping interval). Stored as {"contentions": {idx: label}}.
Cross-lane emergent behavior (emergent_behavior)
Some failures are collective: collusion, groupthink, cascading errors, role drift. An emergent behavior is not a contiguous text span; it is a set of participating turns, possibly from different agents. For each behavior the annotator checks the turns that participate and adds a note, a cross-lane span expressed as a turn-set.
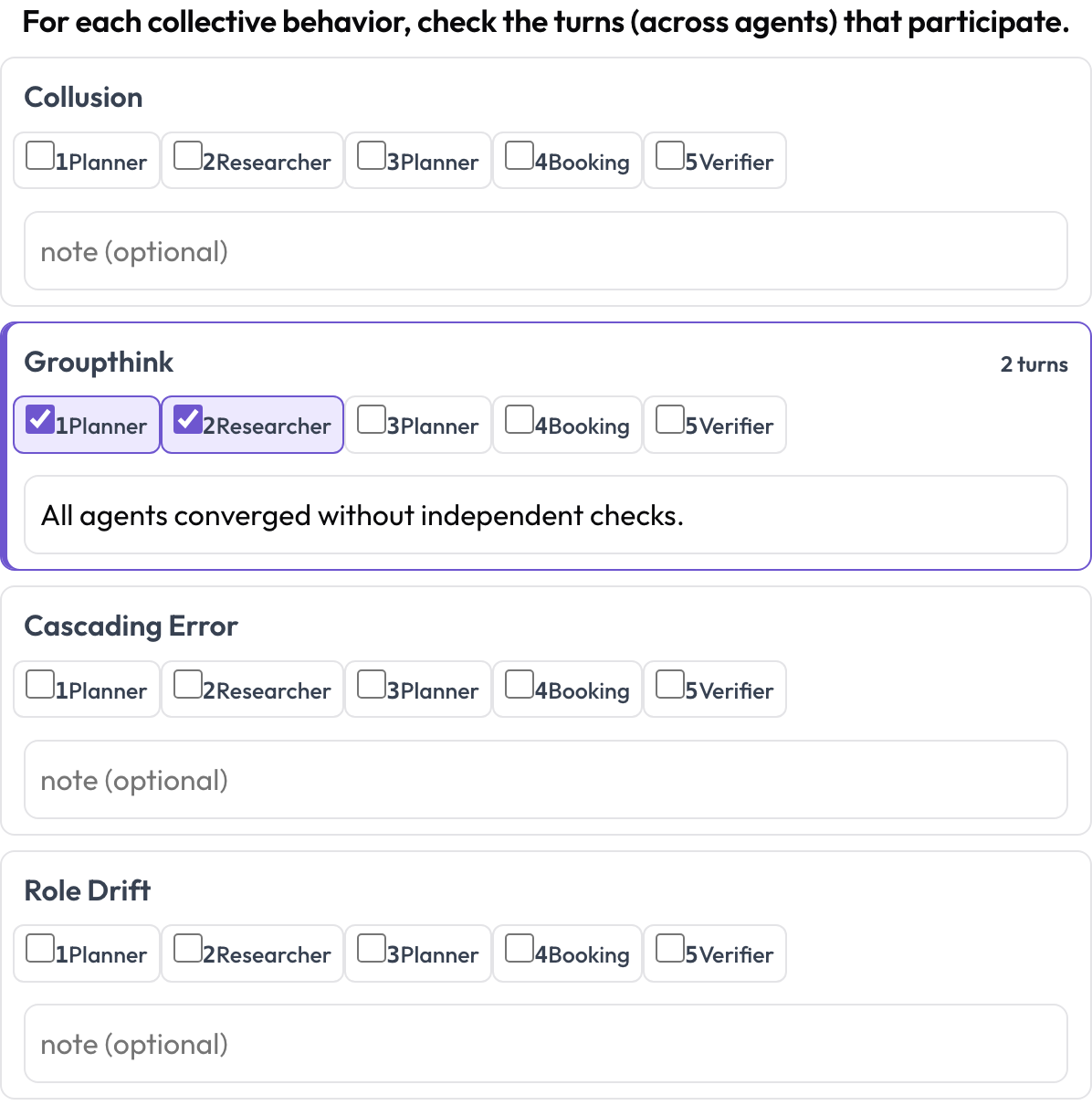 Tag collusion, groupthink, and cascading errors across agents and turns
Tag collusion, groupthink, and cascading errors across agents and turns
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueStored as {behavior: {turns: [idx...], note}}, keeping only non-empty behaviors.
Tool-call review (tool_call_review)
Judge each tool or function call individually: was the right tool chosen, were the arguments correct, was the ordering right (mirroring BFCL v4 / MCPMark)? Tool calls are extracted from the trace steps at render time; each step's tool_calls, tool_call, or action becomes a card with the tool name and pretty-printed arguments.
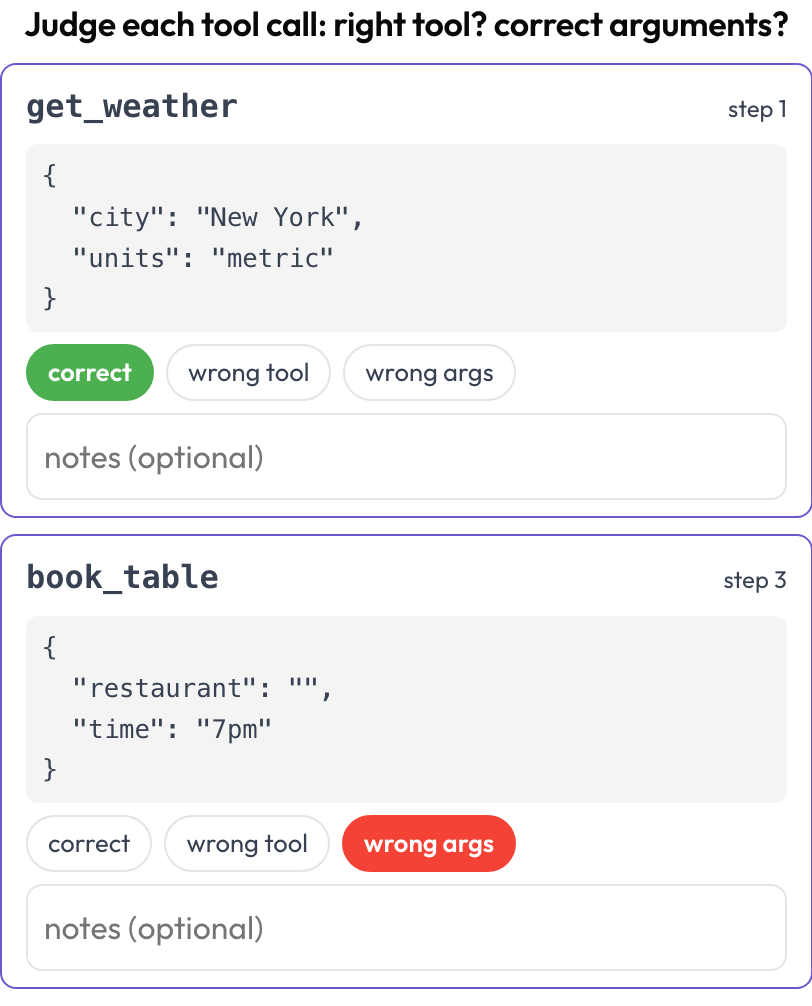 Judge every tool call: right tool, correct arguments, right order
Judge every tool call: right tool, correct arguments, right order
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizableStored as a list of {index, step, tool, verdict, notes}.
MAST tagging at step granularity
You do not need a new schema to bind the 14-mode MAST failure taxonomy (Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025) to the exact step (and therefore the acting agent) where a failure occurred. Configure the existing per-step trajectory_eval schema with the MAST modes as its error_types, grouped by the three MAST categories. Pair it with failure_attribution and handoff_review for full coverage.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]Choosing the orchestration lens
The orchestration architecture often dominates a run's outcome, so it is worth capturing as a first-class label. No new schema is needed: a radio confirms or corrects the run's pattern, which then guides both the evaluation lens and how the trace is laid out (sequential → lanes, hierarchical → tree, group-chat → board).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueRelated
- Multimodal-Agent Evaluation — GUI, voice, video, and document-agent schemas
- Annotating Agent Trajectories — per-step error annotation
- How to Evaluate AI Agents — the levels of agent evaluation
- Agentic Annotation — trace-display configuration and ingestion
For implementation details, see the source documentation.