マルチエージェントチーム評価
マルチエージェントシステムを、フラットなトランスクリプトではなくチーム構造でアノテーションします。Potato はクリック可能なエージェント相互作用グラフ、エージェント間の失敗帰属、ハンドオフレビュー、エージェント別・チーム別のスコアカード、ツール競合タイムライン、創発的挙動のタグ付けを追加します。
マルチエージェントシステムは単一エージェントとは異なる形で失敗します。破綻はエージェントの「間」で、ハンドオフの場面で、あるいはチームの組織のされ方の中で起こります。これを評価するということは、フラットなトランスクリプトを採点することではなく、どのエージェント・どのステップ・どのハンドオフに結果を帰属させるかということです。 Potato はそのために作られた一連のアノテーション面を追加します。クリック可能な相互作用グラフ、失敗帰属、ハンドオフレビュー、エージェント別・チーム別のスコアカード、ツール競合タイムライン、レーンをまたぐ創発的挙動のタグ付けです。
これらはエージェントトレース表示と MAST 失敗分類体系の上に構築されています。各スキーマはレンダリング時にトレース自体からエージェント・ステップ・ハンドオフを導出するため、アノテーターは実行中に実際に起きた内容の中から選択します。
相互作用グラフ (agent_interaction_graph)
実行全体が有向グラフとしてレンダリングされます。ノードはエージェント、エッジはそれらの間のメッセージとハンドオフの遷移(太いエッジほど頻度が高い)で、トレースから自動的にレイアウトされます。アノテーターはノードをクリックしてクリティカルパスをマークし、エッジをクリックして normal → critical → problematic と切り替えます。これは「マルチエージェント実行の構造をどう見るか」という問いに対する最も明確な答えであり、汎用のアノテーションツールが提供しない面です。
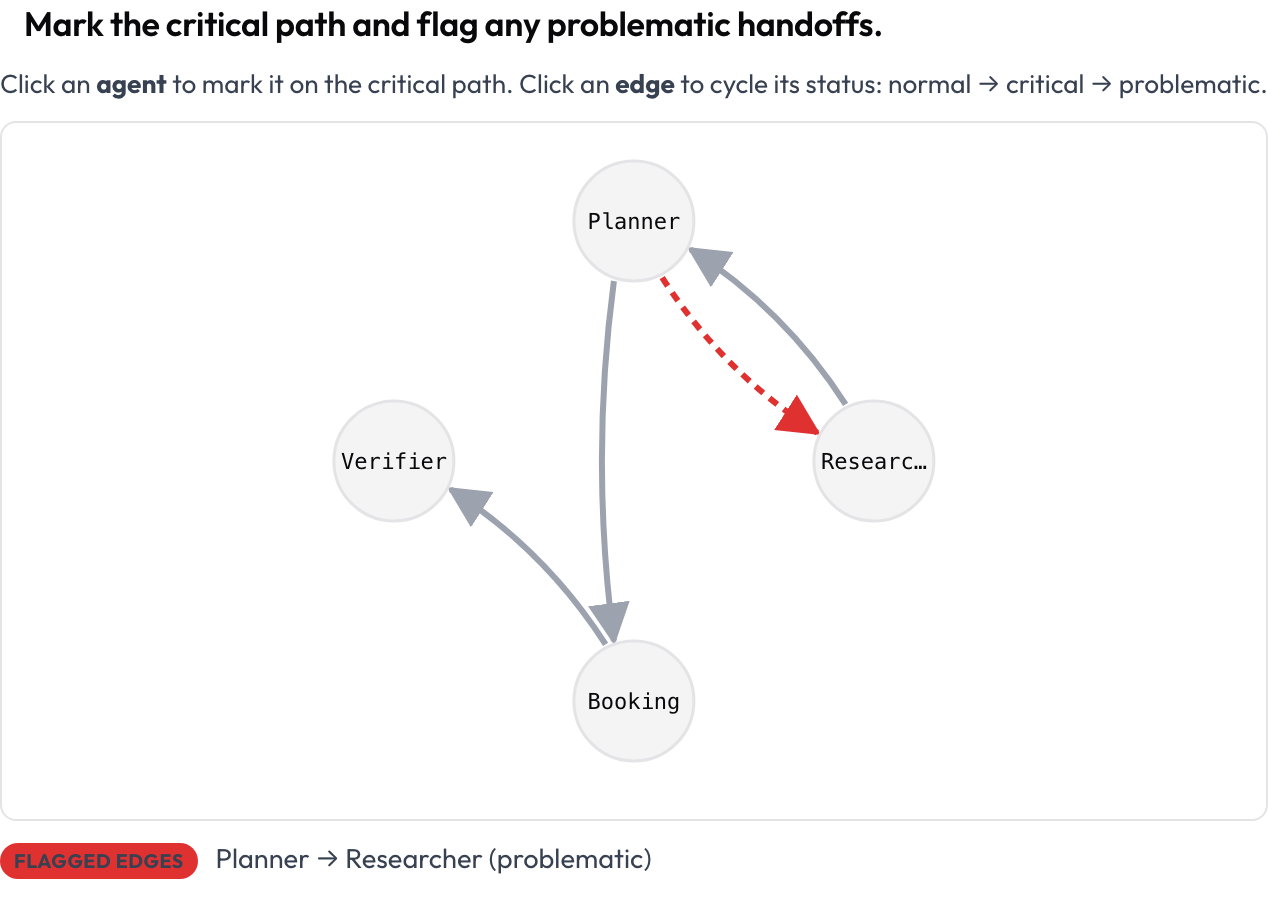 クリック可能なエージェント相互作用グラフでクリティカルパスをマークし、問題のあるハンドオフにフラグを立てる
クリック可能なエージェント相互作用グラフでクリティカルパスをマークし、問題のあるハンドオフにフラグを立てる
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agent{"critical_nodes": [...], "edges": {"A->B": "problematic", ...}} として保存されます。すべてのノードとエッジはキーボードでフォーカス可能で、ライブのテキスト要約がクリティカルなノードとフラグ付きのエッジを列挙するため、意味が色だけで伝えられることはありません。
エージェント間の失敗帰属 (failure_attribution)
チームが失敗したとき、有用なラベルは失敗帰属の研究文献に由来する**(責任を負うエージェント、決定的なステップ、理由)**の三つ組です(Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, the Who&When dataset)。エージェントのドロップダウンとステップ選択はトレース自身のターンから生成されるため、アノテーターは実在するエージェントと実在するステップに失敗を帰属させます。
 マルチエージェントの失敗を、責任を負うエージェント、決定的なステップ、そしてその理由に帰属させる
マルチエージェントの失敗を、責任を負うエージェント、決定的なステップ、そしてその理由に帰属させる
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the trace{"responsible_agent", "decisive_step", "reason"} として保存されます。radio の結果スキーマ(成功/失敗)と組み合わせれば、帰属は失敗した実行に対してのみ発火します。
ハンドオフレビュー (handoff_review)
すべてのハンドオフ、つまりあるエージェントが別のエージェントに制御を渡すことが、アノテーション対象の第一級オブジェクトになります。連続するターンの間で行動するエージェントが変わる箇所すべてで、Potato はハンドオフカード A → B を生成します。アノテーターはエージェント間の不整合にフラグを立て、ハンドオフの品質を評価します。失敗モードは MAST のエージェント間カテゴリと「echoing」現象に基づいています(Zhang et al., 2025)。
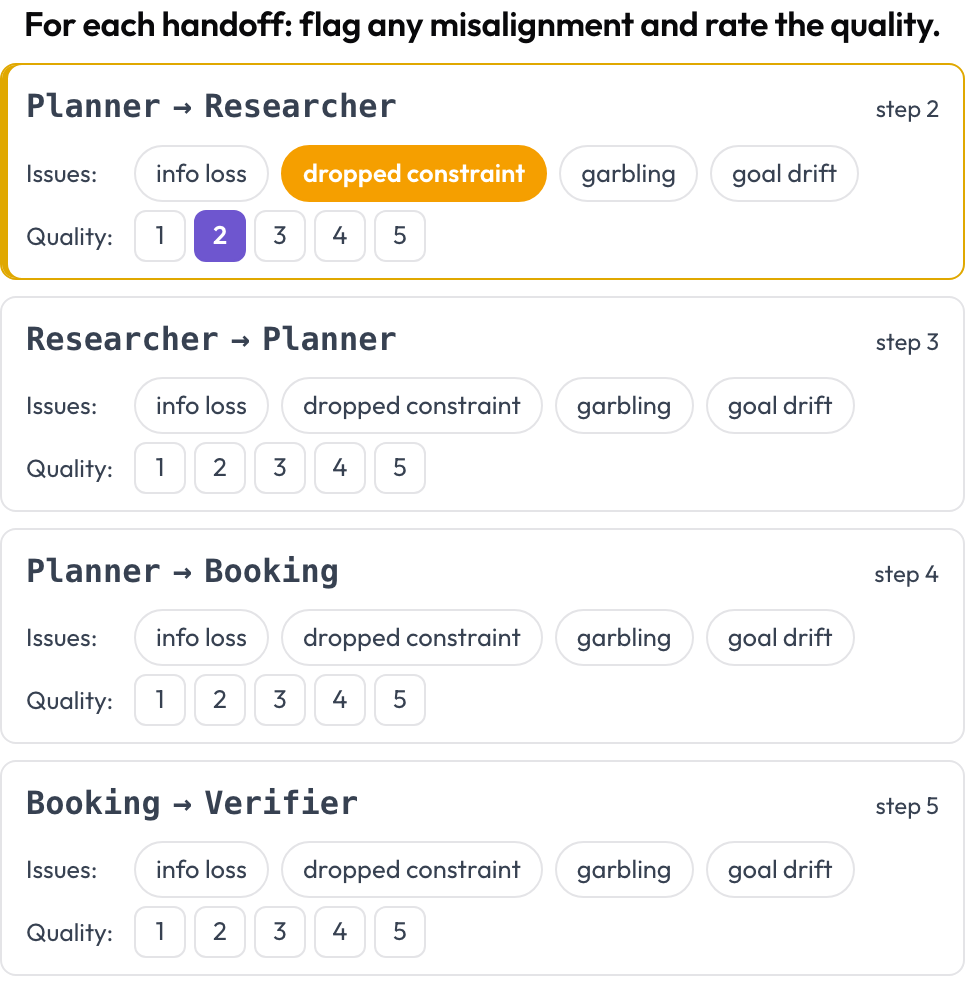 すべてのハンドオフでエージェント間の不整合にフラグを立て、その品質を評価する
すべてのハンドオフでエージェント間の不整合にフラグを立て、その品質を評価する
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5ハンドオフはレンダリング時にトレースから導出されるため、手動でのセットアップは不要です。{index, step, from, to, flags, quality} のリストとして保存されます。
エージェント別・チーム別スコアカード (agent_scorecard)
実行を 2 つのレベルで同時に採点します(MultiAgentBench, Zhou et al., ACL 2025)。各エージェントは次元ごとのスコア(役割忠実度、貢献、協調)を得て、チームは共有次元のスコアを得て、任意のマイルストーンがチェックされます。エージェントの行はトレース自身のターンから来るため、マトリックスは実際に参加した者と一致します。
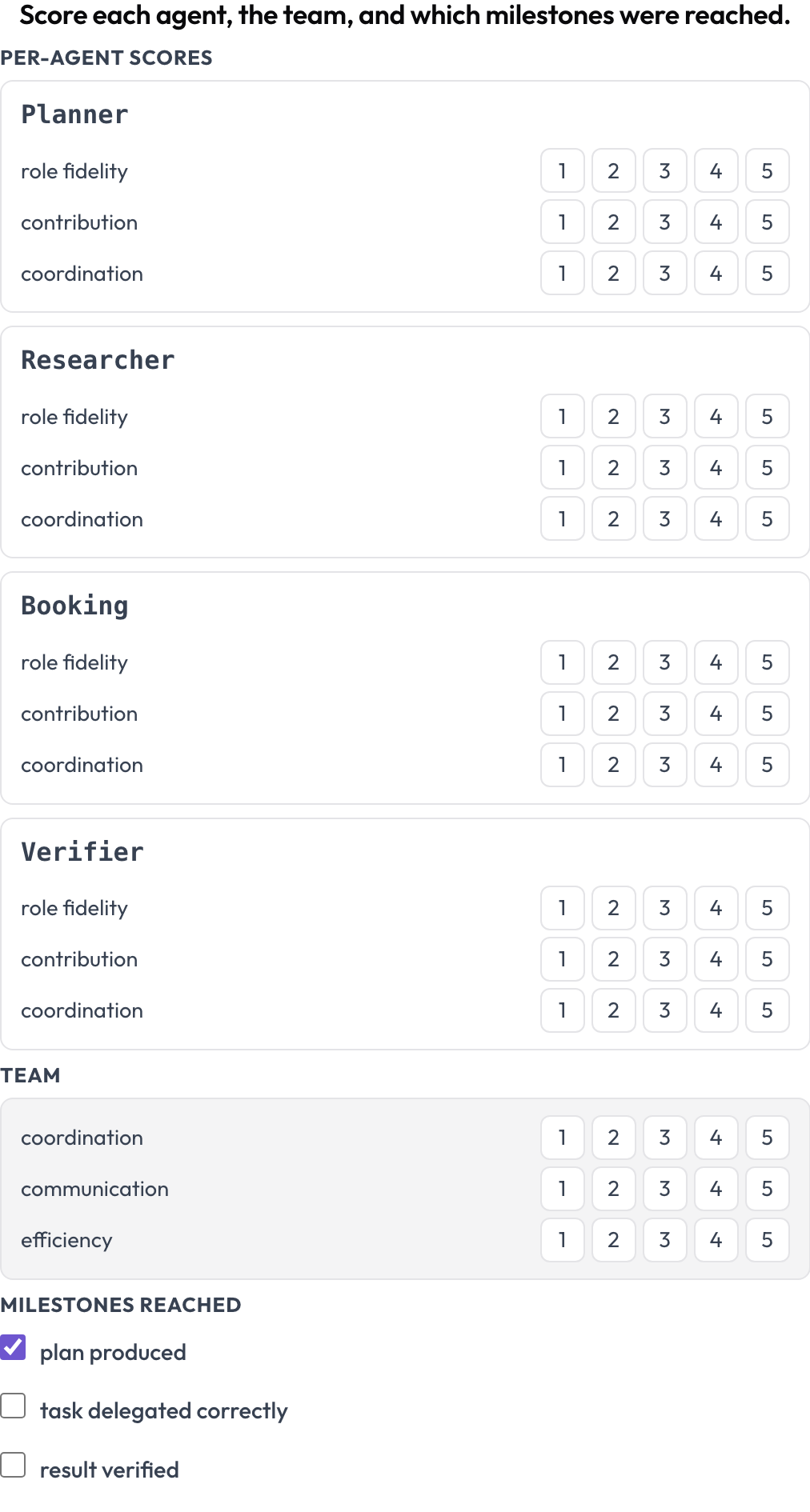 各エージェントを役割忠実度・貢献・協調で採点し、さらにチームとマイルストーンも採点する
各エージェントを役割忠実度・貢献・協調で採点し、さらにチームとマイルストーンも採点する
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optional{"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}} として保存されます。
ツール/リソース競合タイムライン (tool_contention)
エージェントをまたぐ並行的なツールとリソースの利用が、エージェントごとに 1 レーンのマルチレーンタイムラインでレンダリングされます。2 つの呼び出しが重なり合う時間に同じリソースに触れる領域は、レーンをまたいでハイライトされ、分類のために列挙されます。デッドロック、循環待機、競合状態、または無害(DPBench, 2026)です。これは、ターンごとのトランスクリプトが隠してしまう並行性の失敗を捉える方法です。
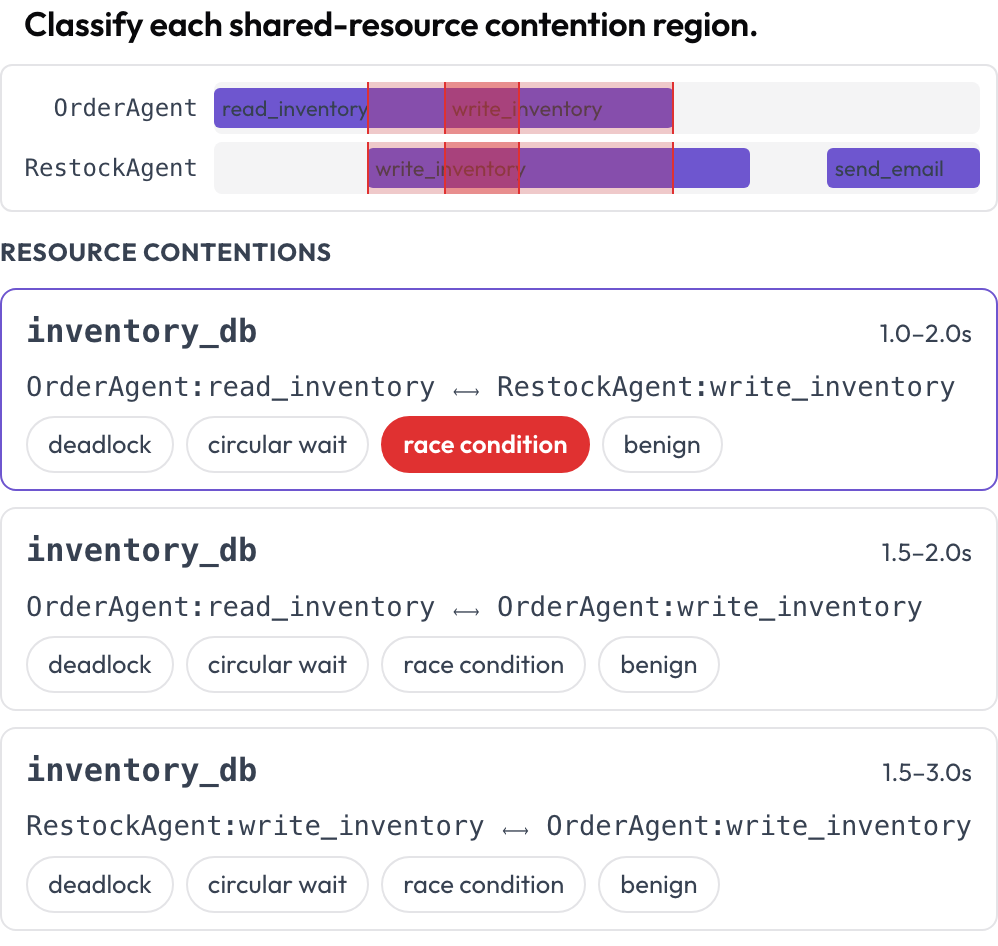 エージェント別ツール呼び出しタイムラインでデッドロックと競合状態を見つける
エージェント別ツール呼び出しタイムラインでデッドロックと競合状態を見つける
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]競合領域はレンダリング時に計算されます(同じ resource、重なる区間)。{"contentions": {idx: label}} として保存されます。
レーンをまたぐ創発的挙動 (emergent_behavior)
一部の失敗は集合的です。共謀、集団思考、連鎖的なエラー、役割ドリフトなどです。創発的挙動は連続したテキストスパンではなく、参加するターンの集合であり、異なるエージェントに由来する場合もあります。各挙動について、アノテーターは参加するターンをチェックしてメモを追加します。これはターン集合として表現される、レーンをまたぐスパンです。
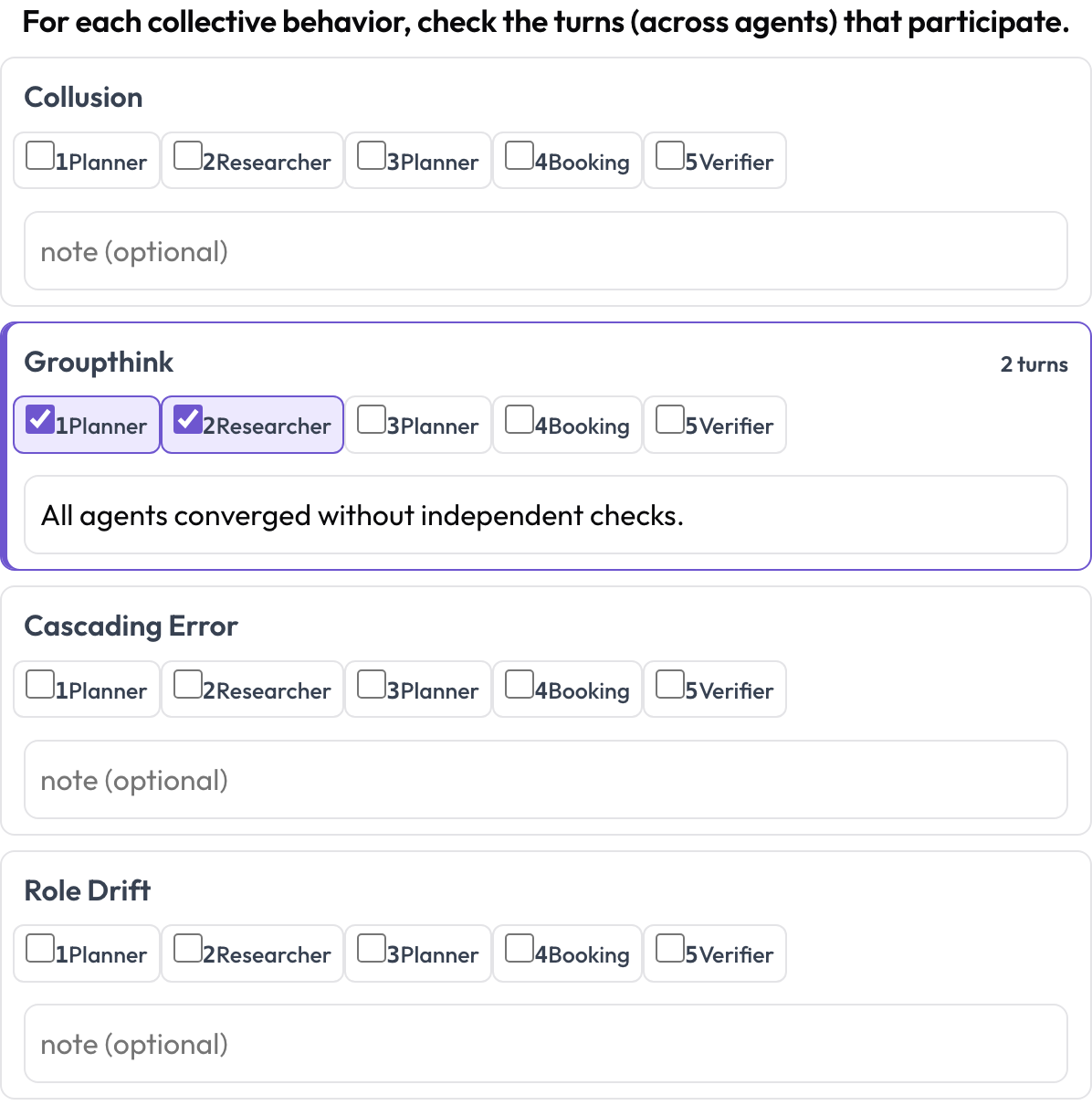 エージェントとターンをまたぐ共謀・集団思考・連鎖的エラーをタグ付けする
エージェントとターンをまたぐ共謀・集団思考・連鎖的エラーをタグ付けする
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: true{behavior: {turns: [idx...], note}} として保存され、空でない挙動のみが残されます。
ツール呼び出しレビュー (tool_call_review)
各ツール呼び出しや関数呼び出しを個別に判断します。正しいツールが選ばれたか、引数は正しかったか、順序は正しかったか(BFCL v4 / MCPMark を反映)。ツール呼び出しはレンダリング時にトレースのステップから抽出されます。各ステップの tool_calls、tool_call、または action が、ツール名と整形表示された引数を持つカードになります。
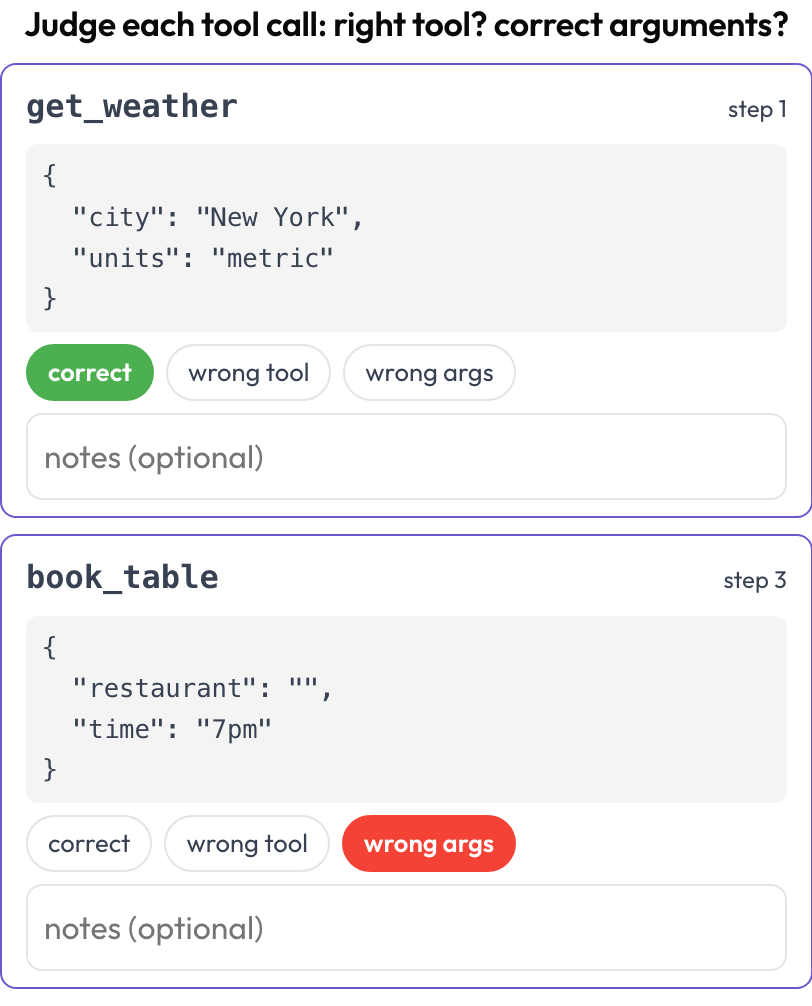 すべてのツール呼び出しを判断する。正しいツールか、正しい引数か、正しい順序か
すべてのツール呼び出しを判断する。正しいツールか、正しい引数か、正しい順序か
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizable{index, step, tool, verdict, notes} のリストとして保存されます。
ステップ粒度での MAST タグ付け
14 モードの MAST 失敗分類体系(Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025)を、失敗が起きたまさにそのステップ(したがって行動したエージェント)に結び付けるのに、新しいスキーマは必要ありません。既存のステップごとの trajectory_eval スキーマを、MAST の 3 つのカテゴリでグループ化した MAST モードを error_types として設定するだけです。完全なカバレッジのために failure_attribution と handoff_review と組み合わせてください。
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]オーケストレーションのレンズを選ぶ
オーケストレーションのアーキテクチャは実行の結果を大きく左右することが多いため、第一級のラベルとして捉える価値があります。新しいスキーマは不要です。radio で実行のパターンを確認または修正すれば、それが評価のレンズと、トレースのレイアウトのされ方の両方を導きます(sequential → レーン、hierarchical → ツリー、group-chat → ボード)。
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: true関連項目
- マルチモーダルエージェント評価 — GUI、音声、動画、文書エージェントのスキーマ
- エージェント軌跡のアノテーション — ステップごとのエラーアノテーション
- AI エージェントの評価方法 — エージェント評価のレベル
- エージェント型アノテーション — トレース表示の設定と取り込み
実装の詳細は、ソースドキュメントを参照してください。