ジャッジ ↔ 人間の整合性
LLM ジャッジが人間のゴールドラベルとどれだけ一致するかを測定します。Potato はアノテーション済みのインスタンスに対してジャッジを実行し、Cohen's kappa、混同行列、不一致リストを算出し、ルーブリックを改善するにつれて一致度を追跡します。
ジャッジ整合性は、LLM ジャッジが人間のゴールドラベルとどれだけ一致するかを測定し、調整します。 Potato は、アノテーターがすでにラベル付けしたインスタンスに対して設定可能な LLM-as-a-judge を実行し、Cohen's κ、混同行列、不一致リストを算出し、ジャッジのルーブリックを編集するたびに κ を追跡します。インラインモードを有効にすると、アノテーション中にジャッジの判定が人間のラベルの隣に表示され、リアルタイムの κ も併せて示されます。
これは、LangSmith Align Evals や Evidently などのツールで使われている、標準的な「ジャッジをおよそ 100〜200 件のゴールドラベルに整合させる」ループです。人間のラベルを集め、ジャッジを実行し、不一致を確認し、ルーブリックを改善し、一致度が高くなるまで再実行します。
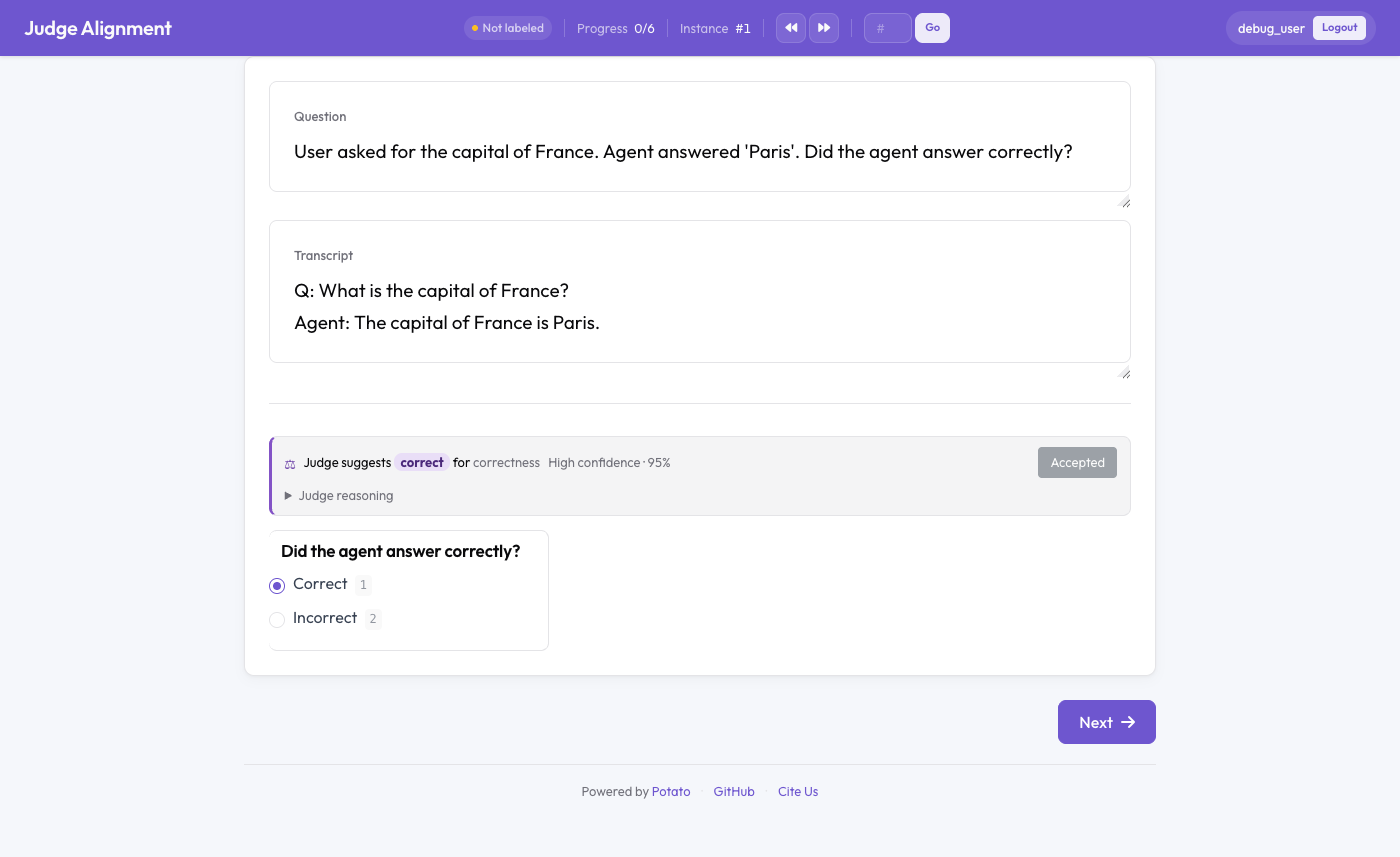 リアルタイムの kappa とともに人間のアノテーションの隣に表示される LLM ジャッジの判定
リアルタイムの kappa とともに人間のアノテーションの隣に表示される LLM ジャッジの判定
設定
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict exists対象となるのは単一選択のカテゴリカルスキーム(radio、select、likert)です。judge_alignment.schemas が設定されている場合は、それらのスキームのみがジャッジされます。設定されていない場合は、すべてのカテゴリカルスキームが対象になります。
ジャッジの実行
ジャッジは管理者 API から実行します。予測はプロンプトバージョンごとにキャッシュされるため、再実行のコストは低く抑えられます。
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'キャリブレーションを行うには、編集したルーブリックを渡します。これにより新しいプロンプトバージョンが作成されるため、ラウンドごとに κ を比較できます。
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'整合性レポート
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
X-API-Key ヘッダーを送信してください。スキームごとに、レポートには次の内容が表示されます。
- Cohen's κ(Landis–Koch による解釈、一致率、比較したインスタンス数を含む)。
- 混同行列(行が人間のゴールド、列がジャッジ)。
- 不一致テーブル(インスタンス、人間のラベル、ジャッジのラベル、信頼度、ジャッジの推論を含む)。
- プロンプトバージョン履歴(バージョンごとの平均 κ を表示するため、キャリブレーションの進捗が一目で分かります)。
人間のゴールドは、各インスタンスに対するアノテーター間の多数決です。
インラインモード
inline.enabled を有効にすると、各アノテーションページにそのインスタンスのキャッシュされたジャッジ判定(ラベル、信頼度、展開可能な推論)が、タスクのリアルタイム κ とともに表示されます。「Accept」をクリックすると、一致する選択肢が入力されます。人間が保存するたびに人間↔ジャッジの比較が記録され、リアルタイムの一致度に反映されます。compute_on_demand: true を設定すると、キャッシュされた判定が存在しない場合にジャッジをライブで呼び出します。そうでない場合は、より高速な事前バッチ実行をおすすめします。
注意事項と制限
- このバージョンではキャリブレーションは手動です。ルーブリックを編集して再実行します。自動的なプロンプト最適化は対象外です。
- 対象は単一選択のカテゴリカルスキームです。スパンや自由テキストのジャッジは今後の課題です。
- 安定した κ を得るには、およそ 100〜200 件のラベル付きインスタンスからなる絞り込んだゴールドセットでジャッジを実行してください。
関連情報
- LLM ジャッジのキャリブレーション — 複数ジャッジ、人間ブラインドによるキャリブレーション誤差付きの調整
- トリアージキュー — 最も情報量の多い項目を優先して人間に回す
- アノテーター間一致性ガイド — kappa 指標を詳しく解説
実装の詳細については、ソースドキュメントを参照してください。