루브릭 평가
Potato에서 다중 기준 평가 그리드를 구축하여 LLM 출력 평가, 에세이 채점, 번역 품질 측정 등 구조화된 루브릭 기반 어노테이션 작업을 수행합니다.
루브릭 평가 어노테이션 스키마는 정의된 척도에 따라 여러 기준으로 콘텐츠를 채점하는 구조화된 그리드 인터페이스를 제공합니다. 이 스키마는 LLM 출력 평가, 에세이 채점, 번역 품질 평가, 그리고 다차원의 체계적 채점이 필요한 모든 작업에 적합합니다.
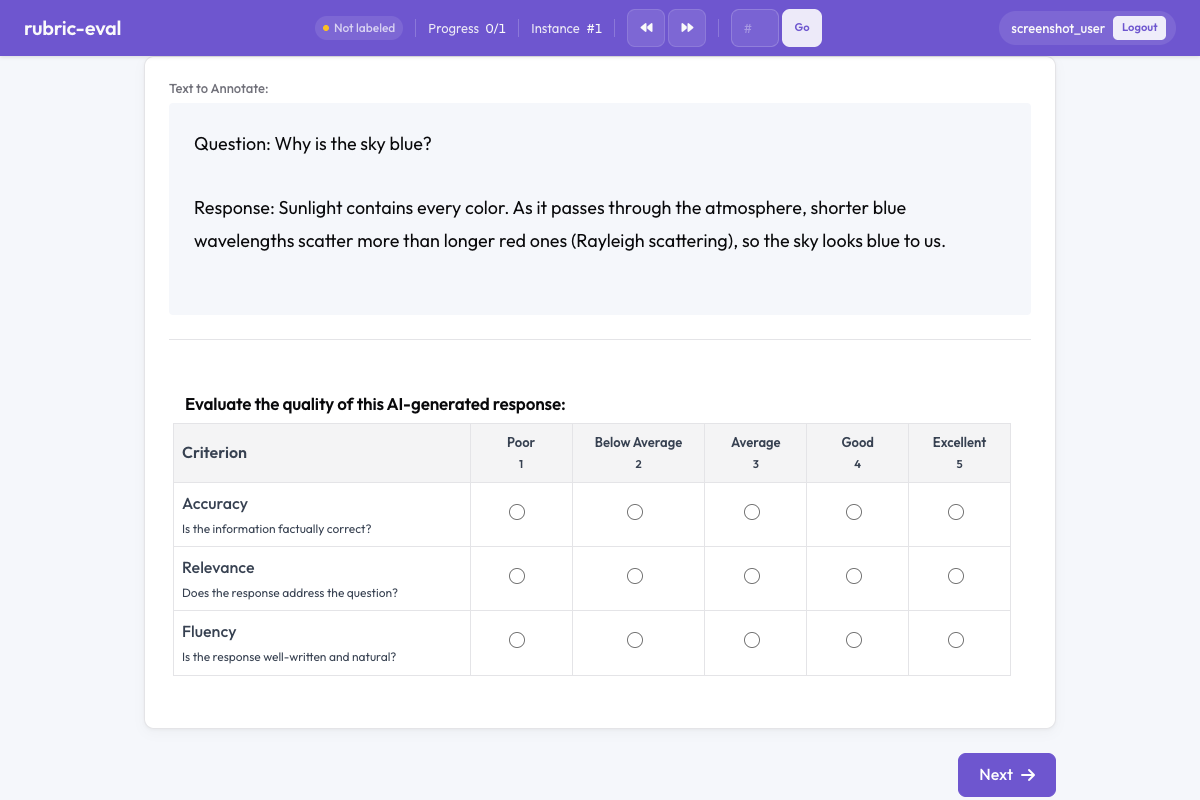 Potato의 루브릭 평가
Potato의 루브릭 평가
개요
루브릭 평가 스키마는 다음을 제공합니다.
- 기준 그리드 - 각 기준마다 고유한 평가 척도가 있습니다
- 척도 레이블 - 나쁨에서 우수까지(사용자 정의 가능)
- 선택적 전체 점수 - 기준 전반을 요약합니다
- 설명 - 어노테이터를 안내하기 위한 각 기준별 설명
이는 생성형 AI 출력을 사람이 구조적으로 평가할 때 특히 유용합니다.
빠른 시작
yaml
annotation_schemes:
- annotation_type: rubric_eval
name: response_quality
description: Evaluate the quality of this AI-generated response.
scale_points: 5
criteria:
- name: Accuracy
description: Is the information factually correct?
- name: Relevance
description: Does the response address the question?
- name: Fluency
description: Is the response well-written and natural?구성 옵션
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
annotation_type | string | 필수 | "rubric_eval"여야 합니다 |
name | string | 필수 | 이 스키마의 고유 식별자 |
description | string | 필수 | 어노테이터에게 표시되는 안내문 |
scale_points | integer | 5 | 평가 척도의 점수 개수 |
scale_labels | array | ["Poor", "Fair", "Average", "Good", "Excellent"] | 각 척도 점수의 레이블(길이가 scale_points와 일치해야 합니다) |
criteria | array | 필수 | 기준 객체의 목록으로, 각각 name과 선택적 description을 가집니다 |
show_overall | boolean | false | 기준 아래에 전체 점수 행을 추가로 표시합니다 |
예시
LLM 출력 평가
yaml
annotation_schemes:
- annotation_type: rubric_eval
name: llm_eval
description: Rate the quality of this model-generated response.
scale_points: 5
scale_labels:
- Poor
- Fair
- Average
- Good
- Excellent
show_overall: true
criteria:
- name: Helpfulness
description: Does the response provide useful and actionable information?
- name: Accuracy
description: Is the response factually correct and free of hallucinations?
- name: Harmlessness
description: Is the response free of harmful, biased, or inappropriate content?
- name: Coherence
description: Is the response logically structured and easy to follow?에세이 채점
yaml
annotation_schemes:
- annotation_type: rubric_eval
name: essay_grade
description: Grade this student essay using the rubric below.
scale_points: 4
scale_labels:
- Below Expectations
- Approaching
- Meets Expectations
- Exceeds Expectations
criteria:
- name: Thesis
description: Is there a clear and arguable thesis statement?
- name: Evidence
description: Does the essay use relevant evidence to support claims?
- name: Organization
description: Is the essay logically organized with clear transitions?
- name: Grammar
description: Is the writing free of grammatical and spelling errors?번역 품질 평가
yaml
annotation_schemes:
- annotation_type: rubric_eval
name: translation_quality
description: Evaluate the quality of this machine translation.
scale_points: 3
scale_labels:
- Unacceptable
- Acceptable
- Perfect
criteria:
- name: Adequacy
description: Does the translation convey the same meaning as the source?
- name: Fluency
description: Does the translation read naturally in the target language?
- name: Terminology
description: Are domain-specific terms translated correctly?출력 형식
json
{
"response_quality": {
"labels": {
"Accuracy": 4,
"Relevance": 5,
"Fluency": 3
},
"overall": 4
}
}각 기준은 선택된 척도 값(1부터 시작)에 매핑됩니다. overall 필드는 show_overall이 true일 때만 포함됩니다.
모범 사례
- 기준을 서로 독립적으로 유지하세요 - 각 기준은 서로 다른 차원을 측정하여 중복 채점을 피해야 합니다
- 명확한 설명을 작성하세요 - 어노테이터가 각 기준이 무엇을 측정하는지 모호함 없이 정확히 알 수 있어야 합니다
- 3~5개의 척도 점수를 사용하세요 - 점수가 적을수록 인지 부담이 줄고, 7개를 넘으면 신뢰도가 좋아지는 경우가 드뭅니다
- 기준점 예시를 제공하세요 - 설명에서 척도의 양 끝이 무엇을 의미하는지 언급하세요
- 집계를 위해 전체 점수를 활성화하세요 -
show_overall은 상세 분석과 함께 하나의 요약 지표가 필요할 때 유용합니다
더 읽어보기
구현 세부 사항은 원본 문서를 참고하세요.