멀티 에이전트 팀 평가
멀티 에이전트 시스템을 평탄한 트랜스크립트가 아니라 팀 구조 단위로 어노테이션합니다. Potato는 클릭 가능한 에이전트 상호작용 그래프, 에이전트 간 실패 귀인, 핸드오프 검토, 에이전트별 및 팀별 스코어카드, 도구 경합 타임라인, 창발적 행동 태깅을 제공합니다.
멀티 에이전트 시스템은 단일 에이전트와는 다르게 실패합니다. 붕괴는 에이전트 사이에서, 핸드오프 지점에서, 또는 팀이 어떻게 조직되었는가에서 일어납니다. 이런 시스템을 평가한다는 것은 평탄한 트랜스크립트를 점수 매기는 것이 아니라 결과를 어느 에이전트, 어느 스텝, 어느 핸드오프에 귀인하는 것을 의미합니다. Potato는 바로 이를 위해 만들어진 어노테이션 화면 모음을 제공합니다. 클릭 가능한 상호작용 그래프, 실패 귀인, 핸드오프 검토, 에이전트별 및 팀별 스코어카드, 도구 경합 타임라인, 그리고 레인을 가로지르는 창발적 행동 태깅입니다.
이들은 에이전트 트레이스 화면과 MAST 실패 분류 체계를 기반으로 합니다. 각 스키마는 렌더링 시점에 트레이스 자체로부터 에이전트, 스텝, 핸드오프를 도출하므로, 어노테이터는 실제로 실행에서 일어난 것들 중에서 선택합니다.
상호작용 그래프 (agent_interaction_graph)
실행 전체가 방향 그래프로 렌더링됩니다. 노드는 에이전트이고, 엣지는 그들 사이의 메시지 및 핸드오프 전이입니다(엣지가 두꺼울수록 더 빈번함을 뜻함). 레이아웃은 트레이스로부터 자동으로 배치됩니다. 어노테이터는 노드를 클릭해 **임계 경로(critical path)**를 표시하고, 엣지를 클릭해 정상 → 임계 → 문제 있음 순으로 순환시킵니다. 이는 "멀티 에이전트 실행의 구조를 어떻게 볼 수 있는가"에 대한 가장 명확한 답이며, 범용 어노테이션 도구가 제공하지 않는 화면입니다.
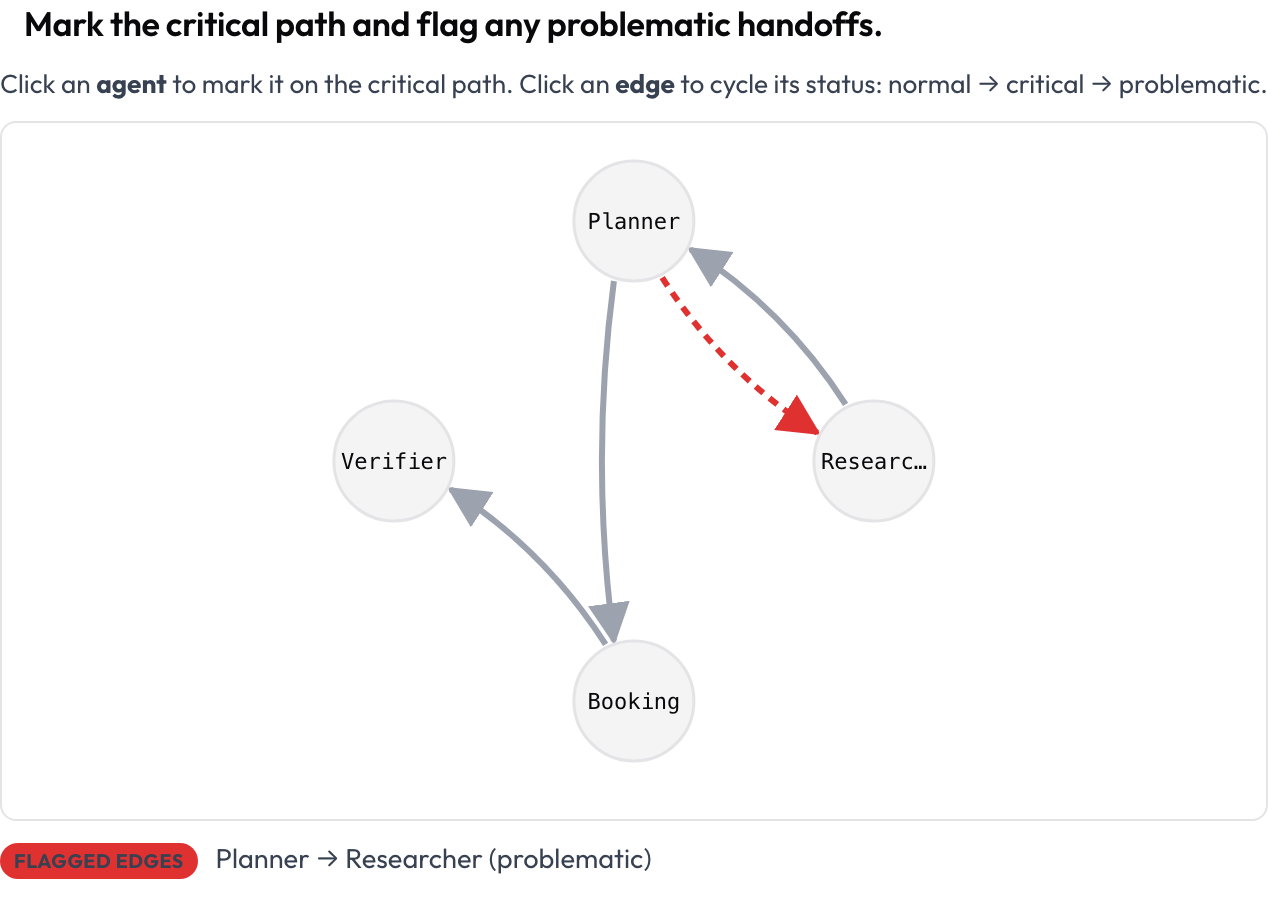 클릭 가능한 에이전트 상호작용 그래프에서 임계 경로를 표시하고 문제 있는 핸드오프를 표시하세요
클릭 가능한 에이전트 상호작용 그래프에서 임계 경로를 표시하고 문제 있는 핸드오프를 표시하세요
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agent{"critical_nodes": [...], "edges": {"A->B": "problematic", ...}} 형태로 저장됩니다. 모든 노드와 엣지는 키보드 포커스가 가능하며, 라이브 텍스트 요약이 임계 노드와 표시된 엣지를 나열하므로 의미가 색상만으로 전달되는 일이 없습니다.
에이전트 간 실패 귀인 (failure_attribution)
팀이 실패할 때 유용한 레이블은 실패 귀인 문헌에서 말하는 (책임 에이전트, 결정적 스텝, 이유) 삼중항입니다(Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, Who&When 데이터셋). 에이전트 드롭다운과 스텝 선택기는 트레이스 자체의 턴들로부터 채워지므로, 어노테이터는 실제 에이전트와 실제 스텝에 실패를 귀인합니다.
 멀티 에이전트 실패를 책임 에이전트, 결정적 스텝, 그리고 그 이유로 귀인하세요
멀티 에이전트 실패를 책임 에이전트, 결정적 스텝, 그리고 그 이유로 귀인하세요
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the trace{"responsible_agent", "decisive_step", "reason"} 형태로 저장됩니다. radio 결과 스키마(성공/실패)와 짝지어, 귀인이 실패한 실행에서만 발동되도록 하십시오.
핸드오프 검토 (handoff_review)
한 에이전트가 다른 에이전트에게 제어를 넘기는 모든 핸드오프가 어노테이션할 일급 객체가 됩니다. 연속된 두 턴 사이에서 행동하는 에이전트가 바뀌는 곳마다 Potato는 핸드오프 카드 A → B를 생성합니다. 어노테이터는 에이전트 간 정렬 불일치를 표시하고 핸드오프 품질을 평가합니다. 실패 양상은 MAST의 에이전트 간 범주와 "echoing" 현상에 근거합니다(Zhang et al., 2025).
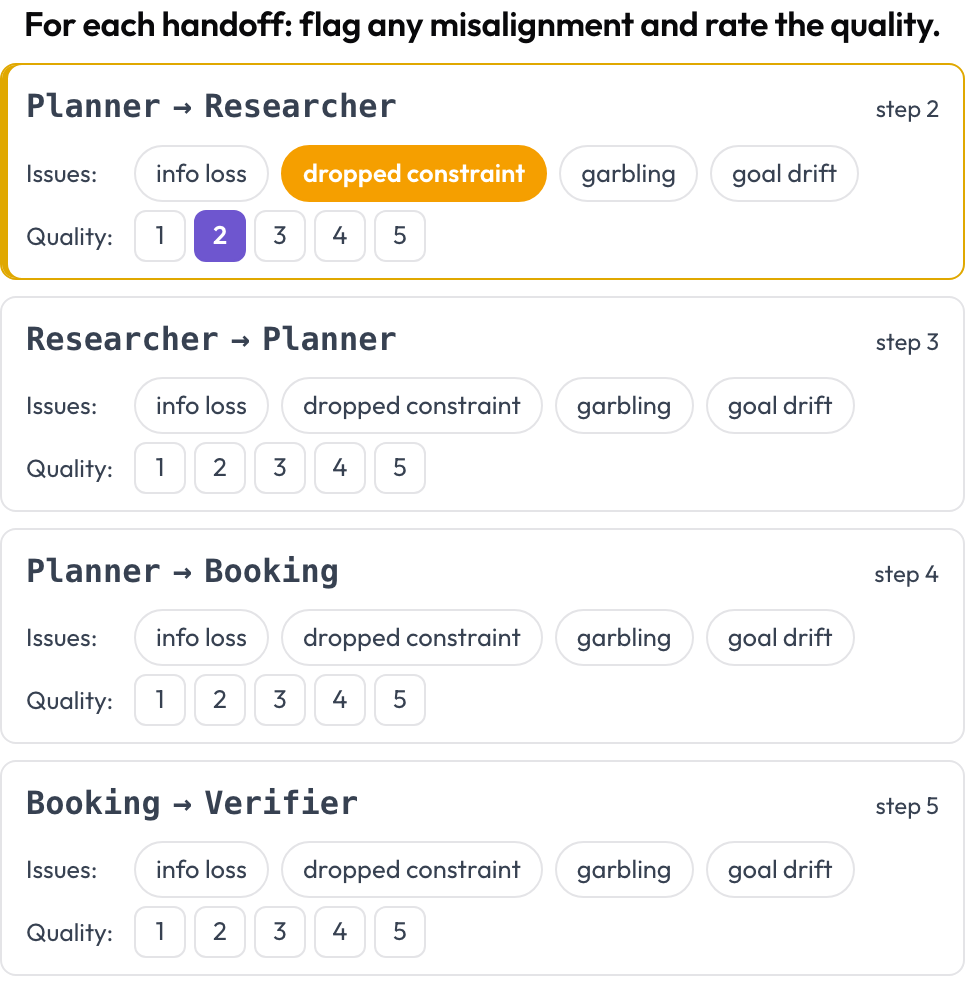 모든 핸드오프에서 에이전트 간 정렬 불일치를 표시하고 그 품질을 평가하세요
모든 핸드오프에서 에이전트 간 정렬 불일치를 표시하고 그 품질을 평가하세요
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5핸드오프는 렌더링 시점에 트레이스로부터 도출되므로 수동 설정이 필요 없습니다. {index, step, from, to, flags, quality}의 리스트로 저장됩니다.
에이전트별 및 팀별 스코어카드 (agent_scorecard)
한 실행을 두 수준에서 동시에 점수 매깁니다(MultiAgentBench, Zhou et al., ACL 2025). 각 에이전트는 차원별 점수(역할 충실도, 기여도, 협응)를 받고, 팀은 공유 차원 점수를 받으며, 선택적 마일스톤이 체크됩니다. 에이전트 행은 트레이스 자체의 턴들에서 나오므로, 매트릭스가 실제로 참여한 주체와 일치합니다.
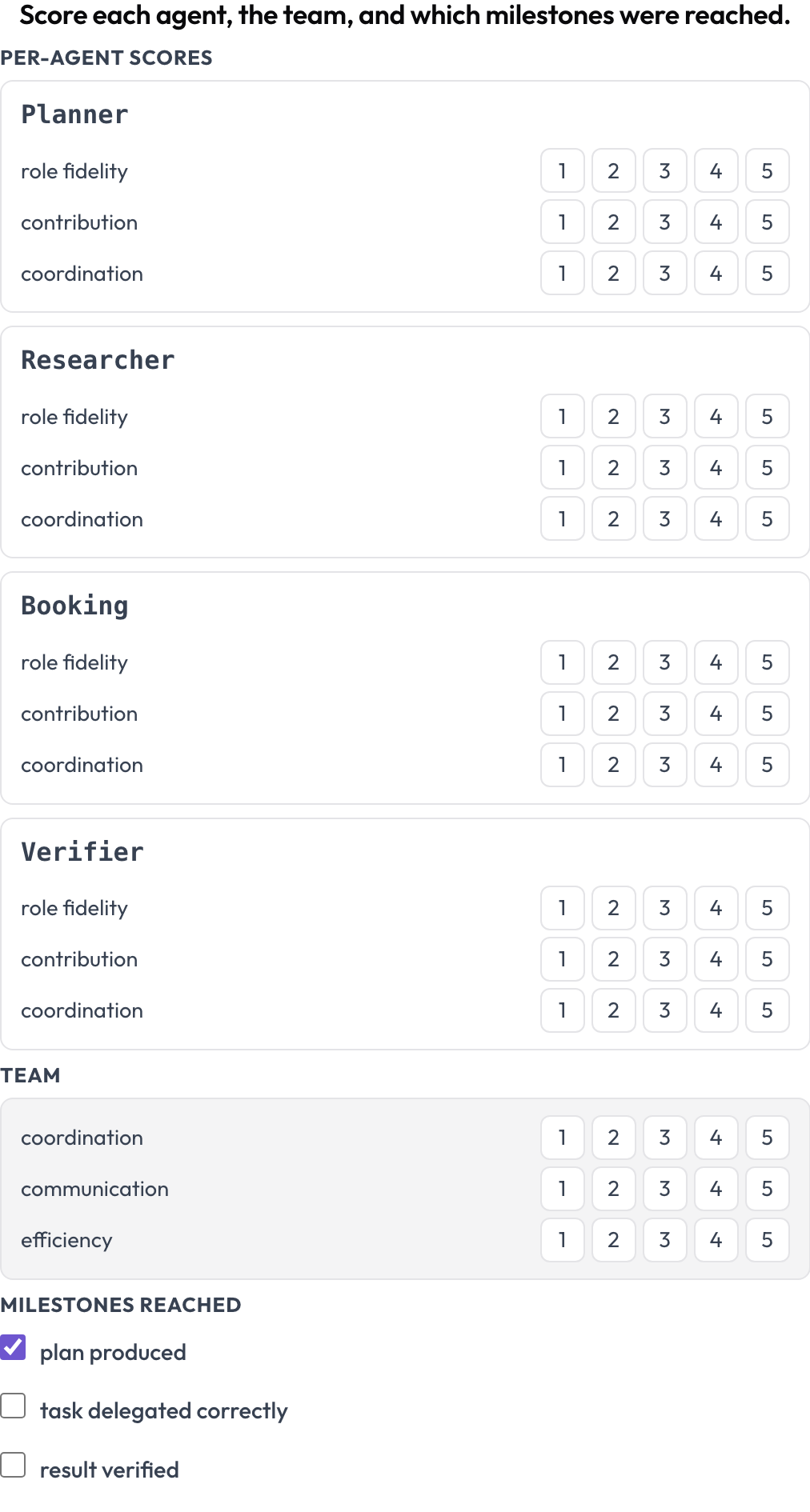 모든 에이전트를 역할 충실도, 기여도, 협응으로 점수 매기고, 팀과 마일스톤도 평가하세요
모든 에이전트를 역할 충실도, 기여도, 협응으로 점수 매기고, 팀과 마일스톤도 평가하세요
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optional{"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}} 형태로 저장됩니다.
도구 / 자원 경합 타임라인 (tool_contention)
에이전트들에 걸친 동시 도구 및 자원 사용이 다중 레인 타임라인에 렌더링되며, 에이전트당 한 레인입니다. 두 호출이 겹치는 시간에 같은 자원을 건드리는 구간은 레인을 가로질러 강조되고 분류를 위해 나열됩니다. 데드락, 순환 대기, 경쟁 상태, 또는 무해 중에서 분류합니다(DPBench, 2026). 이것이 턴별 트랜스크립트가 숨기는 동시성 실패를 잡아내는 방법입니다.
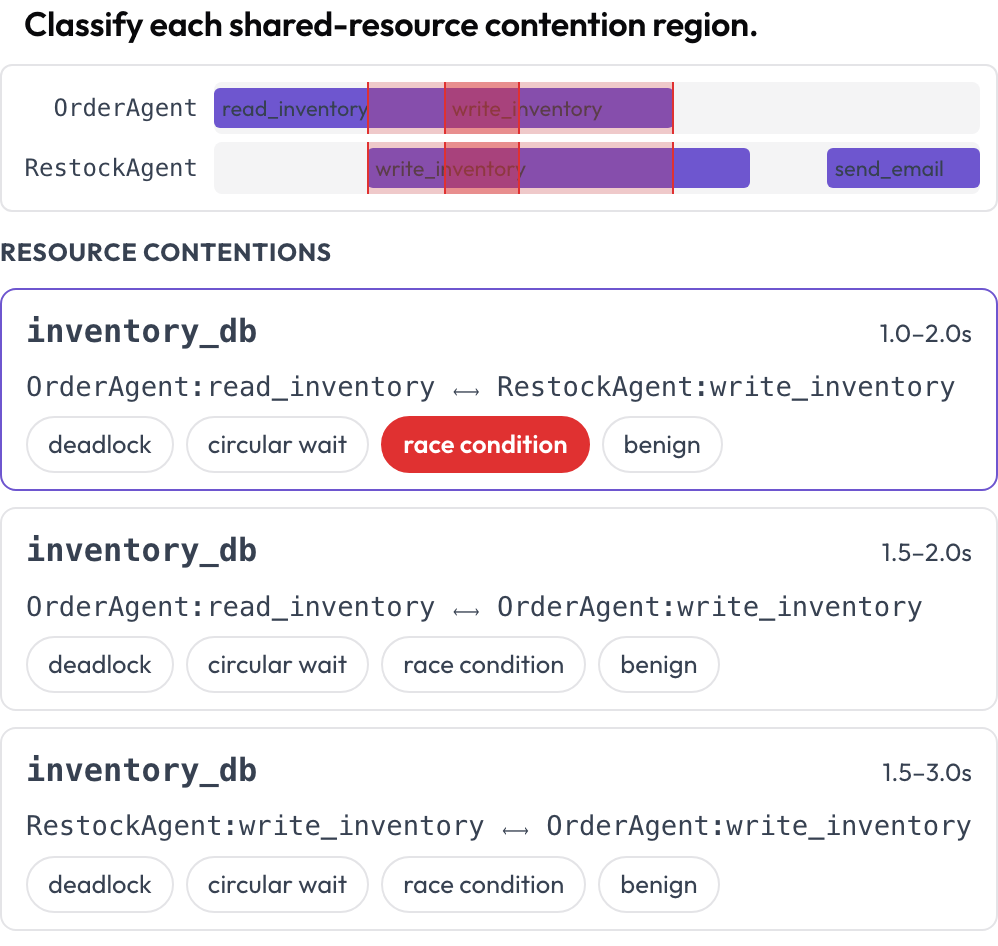 에이전트별 도구 호출 타임라인에서 데드락과 경쟁 상태를 발견하세요
에이전트별 도구 호출 타임라인에서 데드락과 경쟁 상태를 발견하세요
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]경합 구간은 렌더링 시점에 계산됩니다(같은 resource, 겹치는 구간). {"contentions": {idx: label}} 형태로 저장됩니다.
레인을 가로지르는 창발적 행동 (emergent_behavior)
어떤 실패는 집단적입니다. 공모, 집단사고, 연쇄 오류, 역할 표류 같은 것들입니다. 창발적 행동은 연속된 텍스트 스팬이 아니라 참여하는 턴들의 집합이며, 서로 다른 에이전트에서 나온 것일 수 있습니다. 각 행동에 대해 어노테이터는 참여하는 턴들을 체크하고 메모를 추가합니다. 이는 턴 집합으로 표현되는 레인 횡단 스팬입니다.
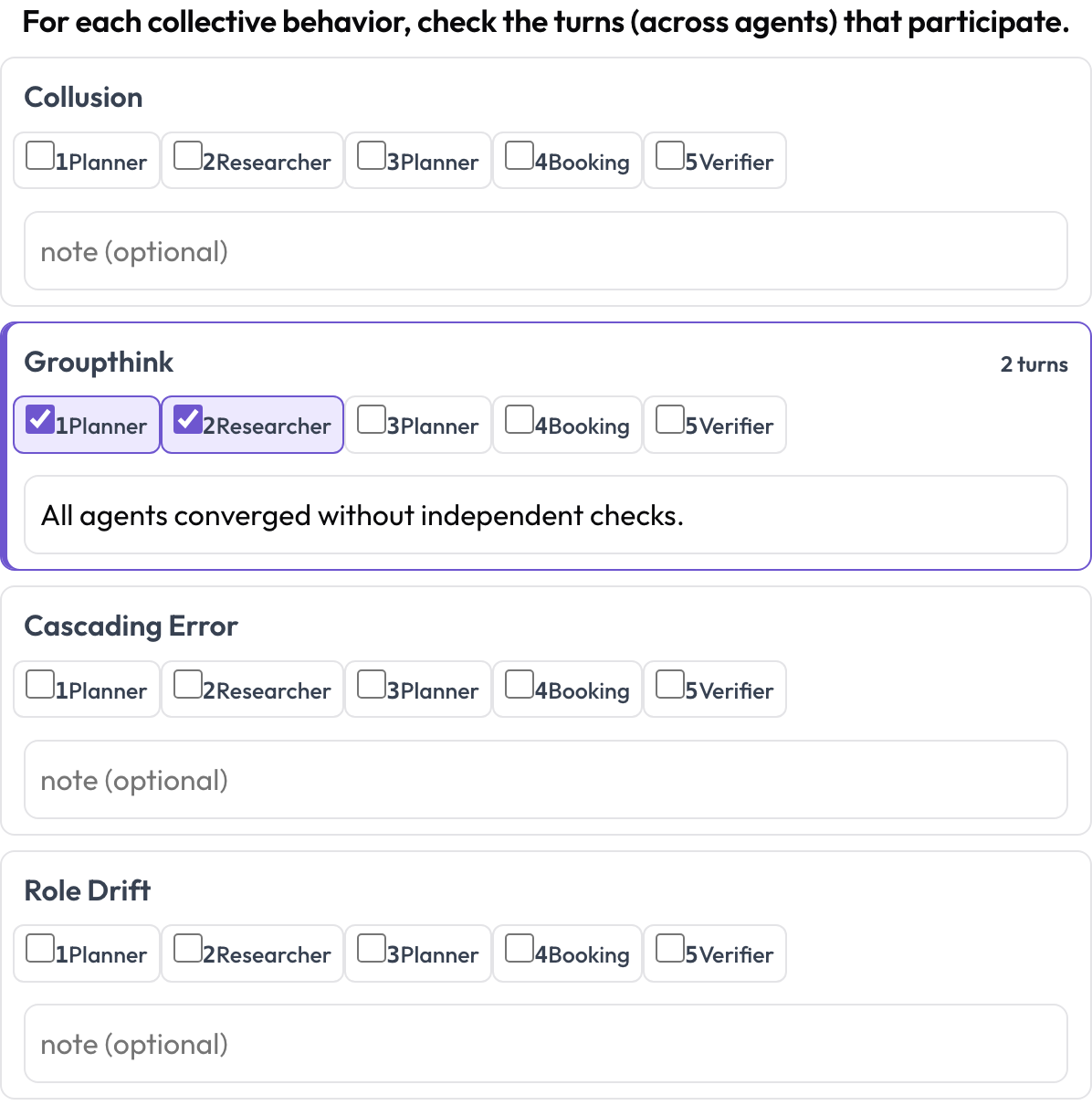 에이전트와 턴에 걸친 공모, 집단사고, 연쇄 오류를 태깅하세요
에이전트와 턴에 걸친 공모, 집단사고, 연쇄 오류를 태깅하세요
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: true{behavior: {turns: [idx...], note}} 형태로 저장되며, 비어 있지 않은 행동만 유지됩니다.
도구 호출 검토 (tool_call_review)
각 도구 또는 함수 호출을 개별적으로 판단합니다. 올바른 도구를 선택했는가, 인자가 정확했는가, 순서가 맞았는가(BFCL v4 / MCPMark을 반영). 도구 호출은 렌더링 시점에 트레이스 스텝에서 추출됩니다. 각 스텝의 tool_calls, tool_call, 또는 action이 도구 이름과 보기 좋게 정리된 인자가 표시된 카드가 됩니다.
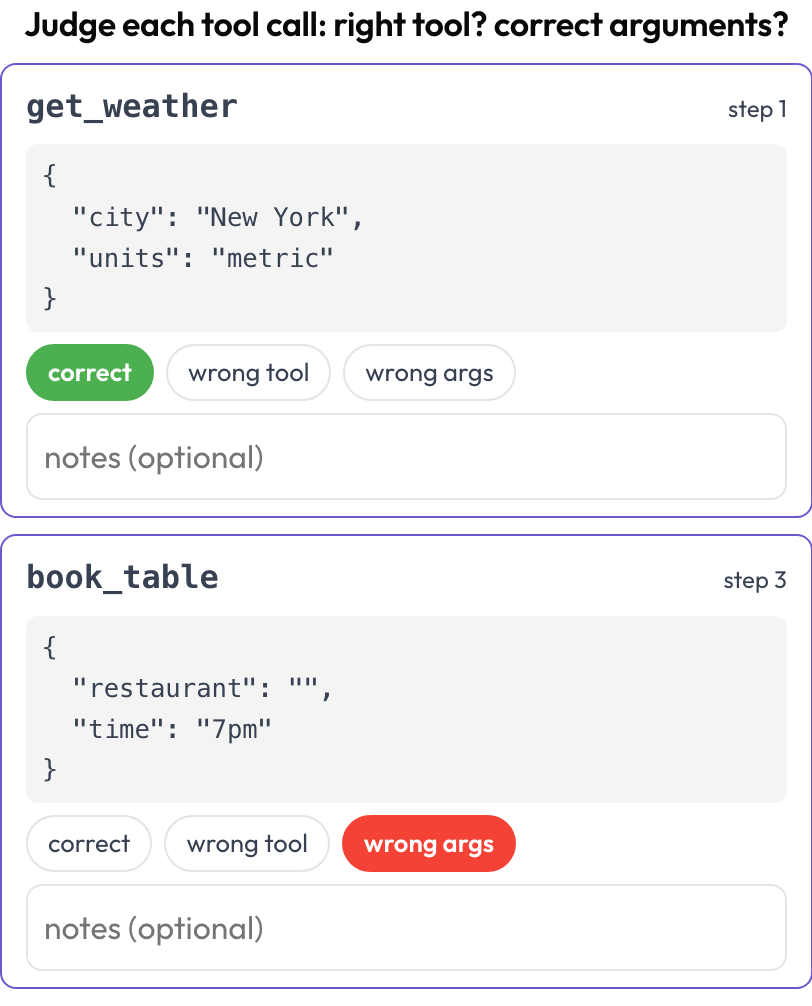 모든 도구 호출을 판단하세요: 올바른 도구, 정확한 인자, 올바른 순서
모든 도구 호출을 판단하세요: 올바른 도구, 정확한 인자, 올바른 순서
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizable{index, step, tool, verdict, notes}의 리스트로 저장됩니다.
스텝 단위 MAST 태깅
14가지 모드의 MAST 실패 분류 체계(Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025)를 실패가 발생한 정확한 스텝(따라서 행동한 에이전트)에 바인딩하는 데 새 스키마가 필요하지 않습니다. 기존의 스텝별 trajectory_eval 스키마를 MAST 모드를 error_types로 하여 구성하고, 세 가지 MAST 범주로 그룹화하십시오. 전체 범위를 다루려면 failure_attribution 및 handoff_review와 짝지으십시오.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]오케스트레이션 렌즈 선택하기
오케스트레이션 아키텍처는 흔히 실행 결과를 좌우하므로, 일급 레이블로 포착할 가치가 있습니다. 새 스키마는 필요 없습니다. radio가 실행의 패턴을 확인하거나 수정하며, 이는 평가 렌즈와 트레이스가 어떻게 배치되는지를 모두 안내합니다(순차 → 레인, 계층 → 트리, 그룹 채팅 → 보드).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: true관련 항목
- 멀티모달 에이전트 평가 — GUI, 음성, 비디오, 문서 에이전트 스키마
- 에이전트 트라젝토리 어노테이션 — 스텝별 오류 어노테이션
- AI 에이전트를 평가하는 방법 — 에이전트 평가의 수준들
- 에이전틱 어노테이션 — 트레이스 화면 구성 및 수집
구현 세부 사항은 소스 문서를 참고하십시오.