멀티모달 에이전트 평가
텍스트를 넘어 행동하는 에이전트를 평가합니다. 컴퓨터 사용 및 GUI 에이전트, 음성 비서, 비디오, 문서 에이전트가 그 대상입니다. Potato는 클릭 그라운딩을 포함한 GUI 트라젝토리, 풀듀플렉스 음성 타임라인, 라이브 IoU가 있는 비디오 시간 그라운딩, 음성-트랜스크립트 오류 태깅, 교차 멀티모달 추론, 표 격자 구조를 위한 전용 스키마를 제공합니다.
에이전트는 점점 더 텍스트를 넘어선 모달리티에서 행동합니다. GUI를 조작하고, 비디오를 보고, 음성 대화를 나눕니다. 각 모달리티는 단순 텍스트 위젯이 제공할 수 없는 검토 화면을 필요로 합니다. 에이전트의 클릭이 표시된 스크린샷, 듀얼 트랙 음성 타임라인, 골드 구간이 있는 비디오 스크러버 같은 것들입니다. Potato는 기존의 이미지, 오디오, 비디오 화면과 더불어, 이런 트레이스를 위해 전용으로 만들어진 어노테이션 스키마를 제공합니다.
모든 스키마는 렌더링 시점에 트레이스로부터 스텝, 턴, 또는 세그먼트를 도출하며, 각각 examples/agent-traces/ 아래에 실행 가능한 예제가 함께 제공됩니다.
GUI / 컴퓨터 사용 트라젝토리 (gui_trajectory)
컴퓨터 사용, GUI, 또는 OS 에이전트를 스텝 단위로 평가합니다(OSWorld, NeurIPS 2024; ScreenSpot-Pro; AndroidWorld). 각 스텝은 에이전트가 본 스크린샷과 에이전트가 취한 행동을 보여줍니다. 어노테이터는 행동을 판단합니다(올바름 / 잘못된 요소 / 잘못된 행동 / 환각). 스텝에 클릭 좌표가 있을 때는 스크린샷 위의 그라운딩 마커가 클릭이 올바른 요소에 떨어졌는지 보여줍니다.
 각 컴퓨터 사용 스텝을 검토하세요: 행동의 정확성과 스크린샷 위의 클릭 그라운딩
각 컴퓨터 사용 스텝을 검토하세요: 행동의 정확성과 스크린샷 위의 클릭 그라운딩
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot # field on each step holding an image URL / data-URI
action_key: action # field holding the action text
coord_space: normalized # normalized (0..1) | pixels — for the x/y grounding marker
verdict_options: [correct, wrong_element, wrong_action, hallucinated]각 스텝은 screenshot, action, 그리고 선택적 x/y(또는 중첩된 click: {x, y})를 제공할 수 있습니다. {index, step, verdict, notes}의 리스트로 저장됩니다.
음성 / 풀듀플렉스 상호작용 (voice_interaction)
사람↔에이전트 음성 대화를 턴 주고받기와 끼어들기(barge-in) 처리에 대해 어노테이션합니다(Full-Duplex-Bench, 2025). 듀얼 트랙 타임라인(사용자 레인과 에이전트 레인)이 각 턴을 시작 및 종료 시각으로 배치하고, 두 화자가 동시에 말하는 겹침 구간을 강조합니다. 어노테이터는 각 겹침을 분류하고(에이전트가 응답해야 함 / 재개해야 함 / 맞장구 / 불확실) 전체적인 턴 주고받기를 평가합니다. 원본 오디오가 제공되면 인라인으로 재생됩니다.
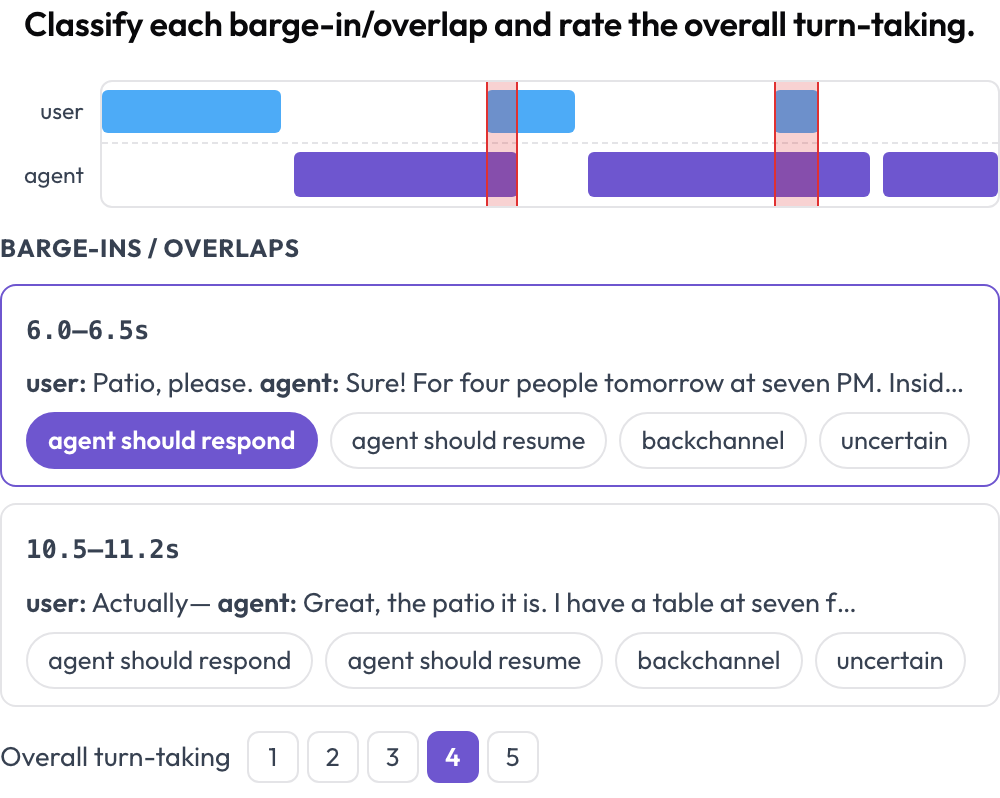 끼어들기 탐지와 턴 주고받기 점수가 있는 듀얼 트랙 음성 타임라인
끼어들기 탐지와 턴 주고받기 점수가 있는 듀얼 트랙 음성 타임라인
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns # list of {speaker, start, end, text} (seconds)
speaker_key: speaker
user_speakers: [user, human, caller] # everything else is treated as the agent
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5
# audio_key: audio # optional per-instance audio URL to enable the player서로 다른 화자의 턴 사이 겹침은 렌더링 시점에 계산됩니다. {"overlaps": {idx: label}, "rating": int} 형태로 저장됩니다.
비디오 시간 그라운딩 (temporal_grounding)
시간 그라운딩 평가를 위해 비디오에서 이벤트 시간 구간을 표시합니다(TimeScope, 2025; ET-Bench). 각 이벤트 프롬프트에 대해 어노테이터는 재생 헤드를 캡처하거나 초를 입력해 골드 [start, end]를 설정합니다. 데이터에 모델의 예측 구간이 있을 때는, 조정하는 동안 라이브 IoU와 두 막대 미니 타임라인(예측 대 골드)이 갱신됩니다. 이는 예측-대-골드 위치 측정 점수를 위해 전용으로 만들어졌으며, 일반적인 세그먼트 레이블링과는 구별됩니다.
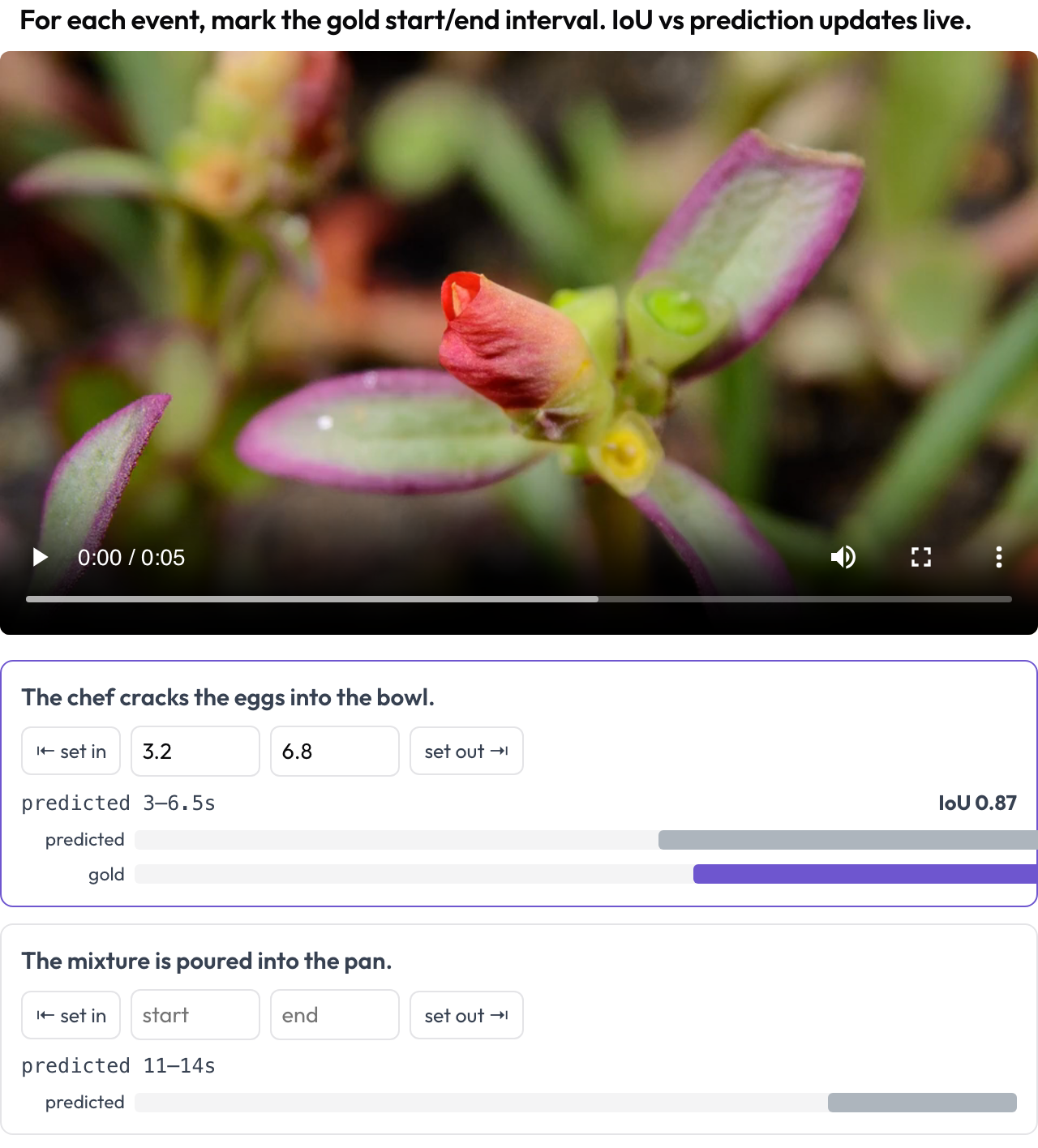 모델 예측 대비 라이브 IoU와 함께 비디오에서 골드 이벤트 구간을 표시하세요
모델 예측 대비 라이브 IoU와 함께 비디오에서 골드 이벤트 구간을 표시하세요
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video # per-instance video URL
events_key: events # list of {prompt, predicted: {start, end}} (predicted optional)
# duration: 120 # optional fixed timeline scale (else inferred from the video){"events": {idx: {start, end}}} 형태로 저장됩니다.
정렬된 트랜스크립트 음성 오류 (speech_transcript)
시간 정렬된 음성 트랜스크립트를 ASR/TTS 및 음성 품질 오류에 대해 세그먼트 단위로 어노테이션합니다(Speak & Improve, 2025). 각 세그먼트 {start, end, text, speaker?}는 타임스탬프와 텍스트를 보여주는 카드입니다. 어노테이터는 오류를 태깅하고(ASR 오류 / TTS 아티팩트 / 발음 오류 / 비유창성) 수정된 트랜스크립트를 입력할 수 있습니다. 이는 voice_interaction의 턴 주고받기 화면을 보완하는 세그먼트 단위 화면입니다.
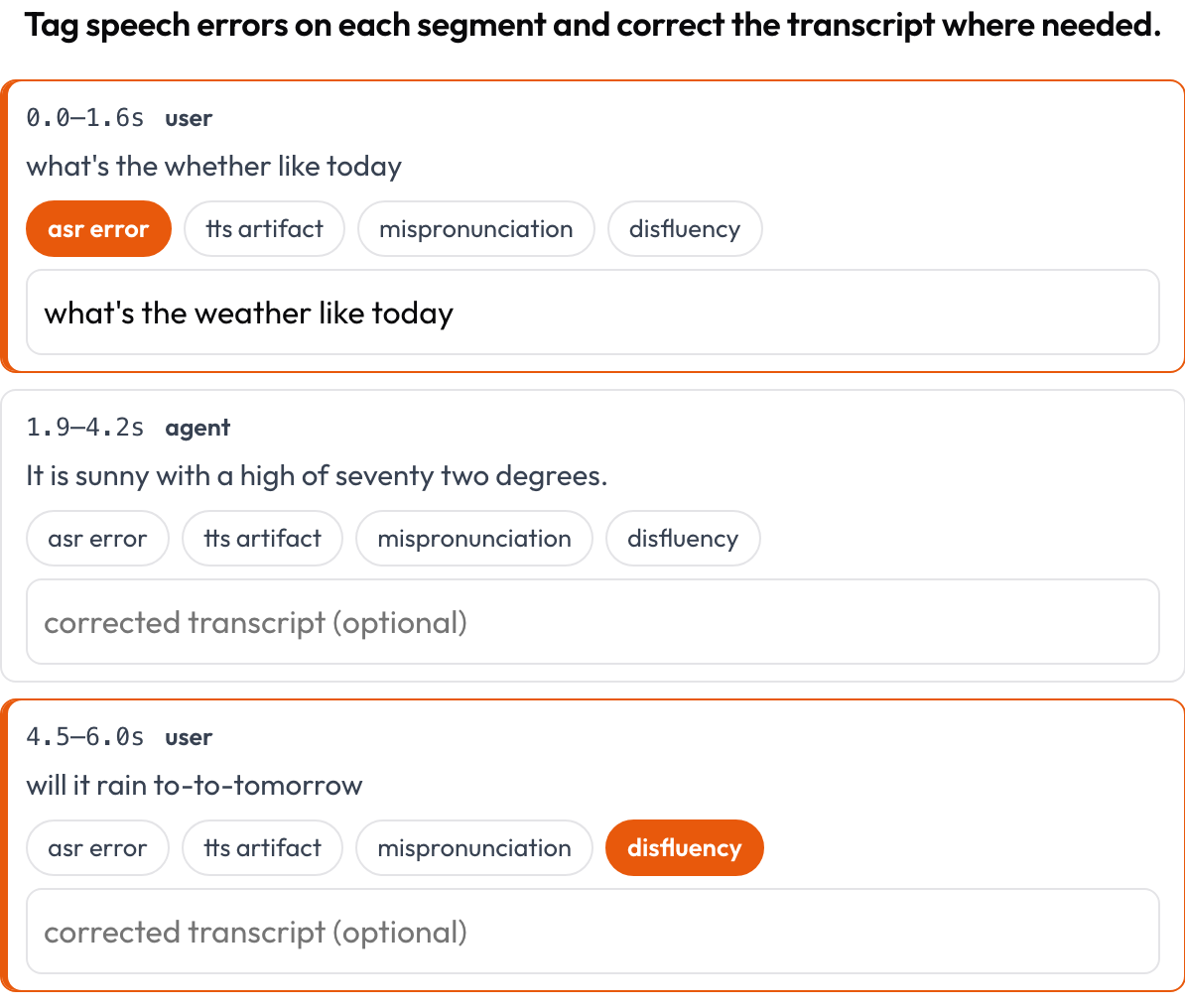 세그먼트마다 ASR/TTS/발음 오류를 태깅하고 트랜스크립트를 인라인으로 수정하세요
세그먼트마다 ASR/TTS/발음 오류를 태깅하고 트랜스크립트를 인라인으로 수정하세요
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments # list of {start, end, text, speaker?}
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true
# audio_key: audio # optional per-item audio URL to enable the player{index, start, end, errors, correction}의 리스트로 저장됩니다.
교차 멀티모달 추론 (multimodal_reasoning)
텍스트 ↔ 이미지 ↔ 도구 ↔ 행동이 교차되는 추론 트레이스를 스텝 단위로 평가합니다(Multimodal RewardBench 2, 2025; Zebra-CoT). 각 스텝은 타입이 지정된 블록으로, 타입에 따라 인라인으로 렌더링됩니다. 어노테이터는 각 스텝의 일관성을 판단합니다. 추론이 이미지와 이전 스텝으로부터 따라 나오는가, 아니면 시각 정보가 환각된 것인가?
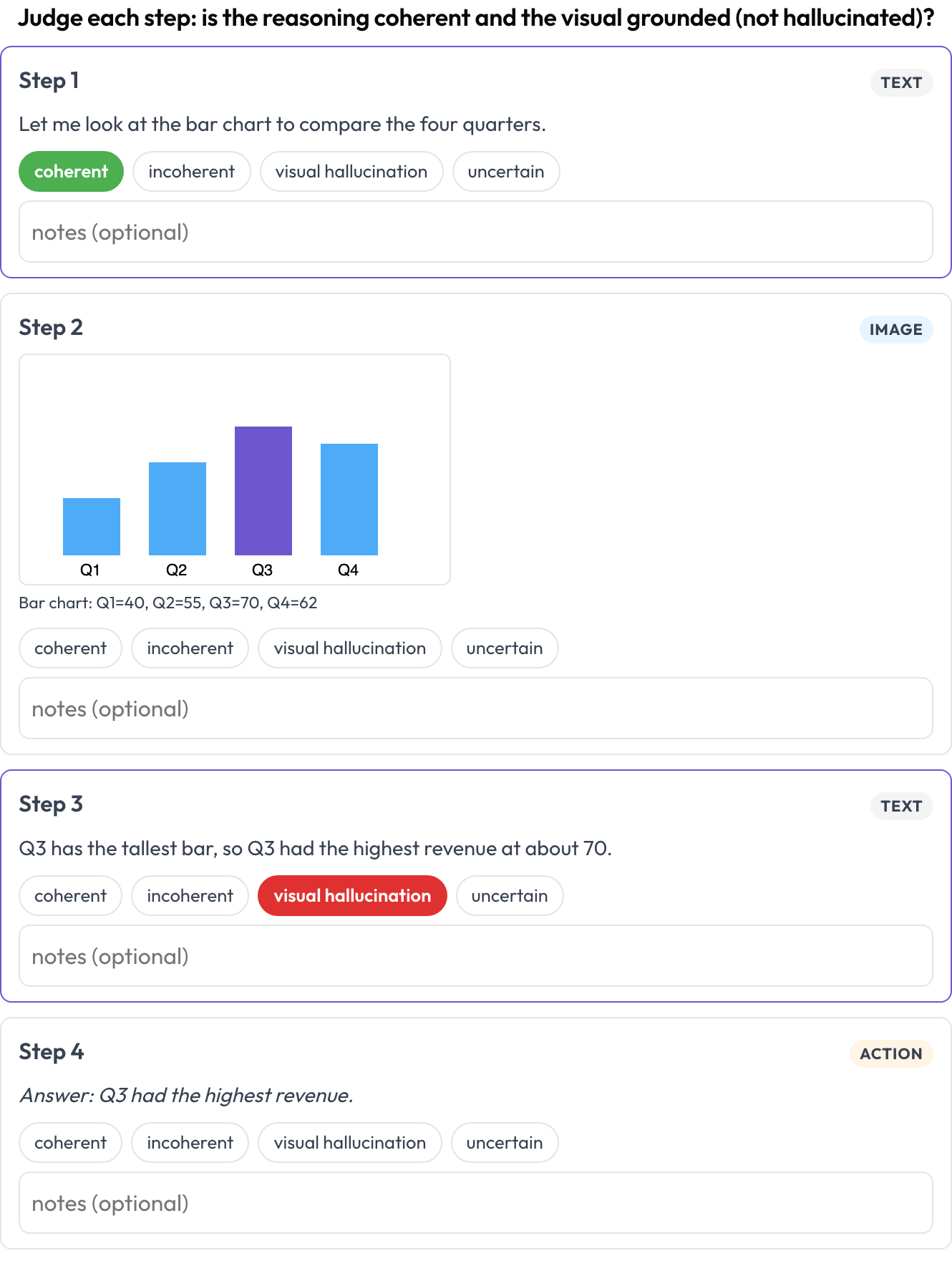 텍스트-이미지-도구 추론 트레이스의 각 스텝을 일관성과 시각 환각에 대해 평가하세요
텍스트-이미지-도구 추론 트레이스의 각 스텝을 일관성과 시각 환각에 대해 평가하세요
annotation_schemes:
- annotation_type: multimodal_reasoning
name: reasoning_review
description: "Judge each step: coherent reasoning and grounded visuals?"
steps_key: steps
type_key: type # each step's 'type': text | image | tool | action (inferred if absent)
verdict_options: [coherent, incoherent, visual_hallucination, uncertain]각 스텝은 text/content, image/image_url(+caption), 또는 tool/args를 담을 수 있습니다. {index, step, type, verdict, notes}의 리스트로 저장됩니다.
표 격자 구조 (table_grid)
표 이미지의 셀 구조를 어노테이션합니다. 이는 단순 바운딩 박스가 포착할 수 없는, 문서에 특화된 부분입니다(OmniDocBench, CVPR 2025; RealHiTBench). 어노테이터는 격자 차원을 설정하고 셀을 클릭해 그 역할을 표시합니다(데이터 / 열 헤더 / 행 헤더 / 비어 있음). 페이지별 영역 박스는 페이지마다 이미지 어노테이션을 실행하여 이미 다루어지므로, 이 스키마는 그 박스가 표현할 수 없는 구조에 집중합니다.
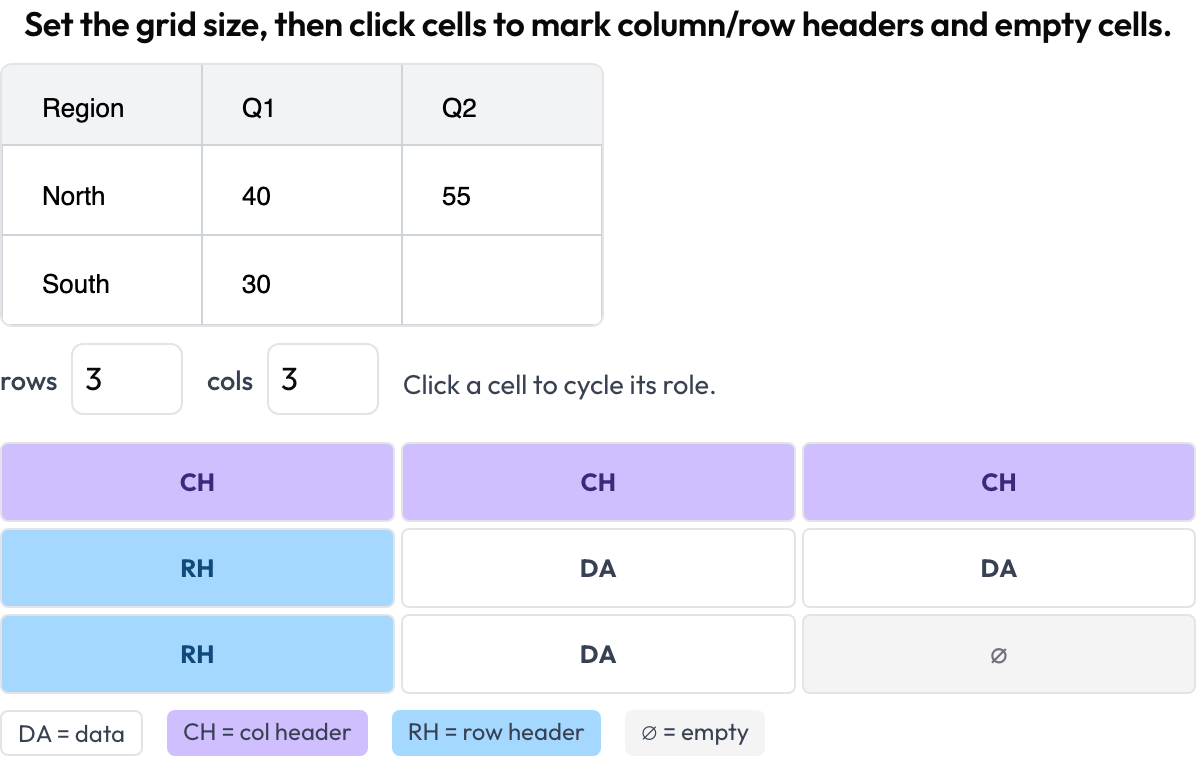 문서 표의 셀 구조를 어노테이션하세요: 열 및 행 헤더, 데이터, 빈 셀
문서 표의 셀 구조를 어노테이션하세요: 열 및 행 헤더, 데이터, 빈 셀
annotation_schemes:
- annotation_type: table_grid
name: structure
description: "Set the grid size, then click cells to mark headers and empty cells."
image_key: image # per-instance table image URL / data-URI
rows_key: rows # optional initial dims from the data
cols_key: cols
roles: [data, col_header, row_header, empty] # click cycles through these{rows, cols, cells: {"r,c": role}} 형태로 저장되며, data가 아닌 셀만 유지됩니다.
관련 항목
- 멀티 에이전트 팀 평가 — 상호작용 그래프, 핸드오프, 팀 스코어카드
- 웹 에이전트 평가 — 스크린샷-앤-액션 웹 에이전트
- AI 에이전트를 평가하는 방법 — 에이전트 평가의 수준들
- 에이전틱 어노테이션 — 트레이스 화면 구성 및 수집
구현 세부 사항은 소스 문서를 참고하십시오.