SFT/DPO를 위한 궤적 편집
주석자는 에이전트 트레이스의 단계를 다시 작성하여 잘못된 추론 단계를 고치거나 도구 호출을 수정하거나 최종 답변을 강화하며, Potato는 각 원본/수정 쌍을 지도 미세 조정 타깃과 DPO 선호 쌍으로 내보냅니다.
trajectory_edit 스키마를 사용하면 주석자가 에이전트 트레이스의 단계를 다시 작성하고 각 수정을 학습 데이터로 내보낼 수 있습니다. 잘못된 추론 단계를 고치거나, 오타가 있는 도구 호출을 수정하거나, 최종 답변을 강화하면 Potato는 수정된 궤적을 원본 옆에 저장합니다. 이후 trajectory_correction 내보내기 도구가 각 (original, corrected) 쌍을 지도 미세 조정(SFT) 타깃과 직접 선호 최적화(DPO) 선호 쌍으로 변환합니다.
이로써 Potato는 평가 도구일 뿐만 아니라 학습 데이터 생산 도구가 됩니다. 이는 단계 수준 채점의 편집 버전에 해당합니다. 즉, 주석자는 궤적을 평가하는 대신 수리하며, 그 수리가 학습 신호가 됩니다.
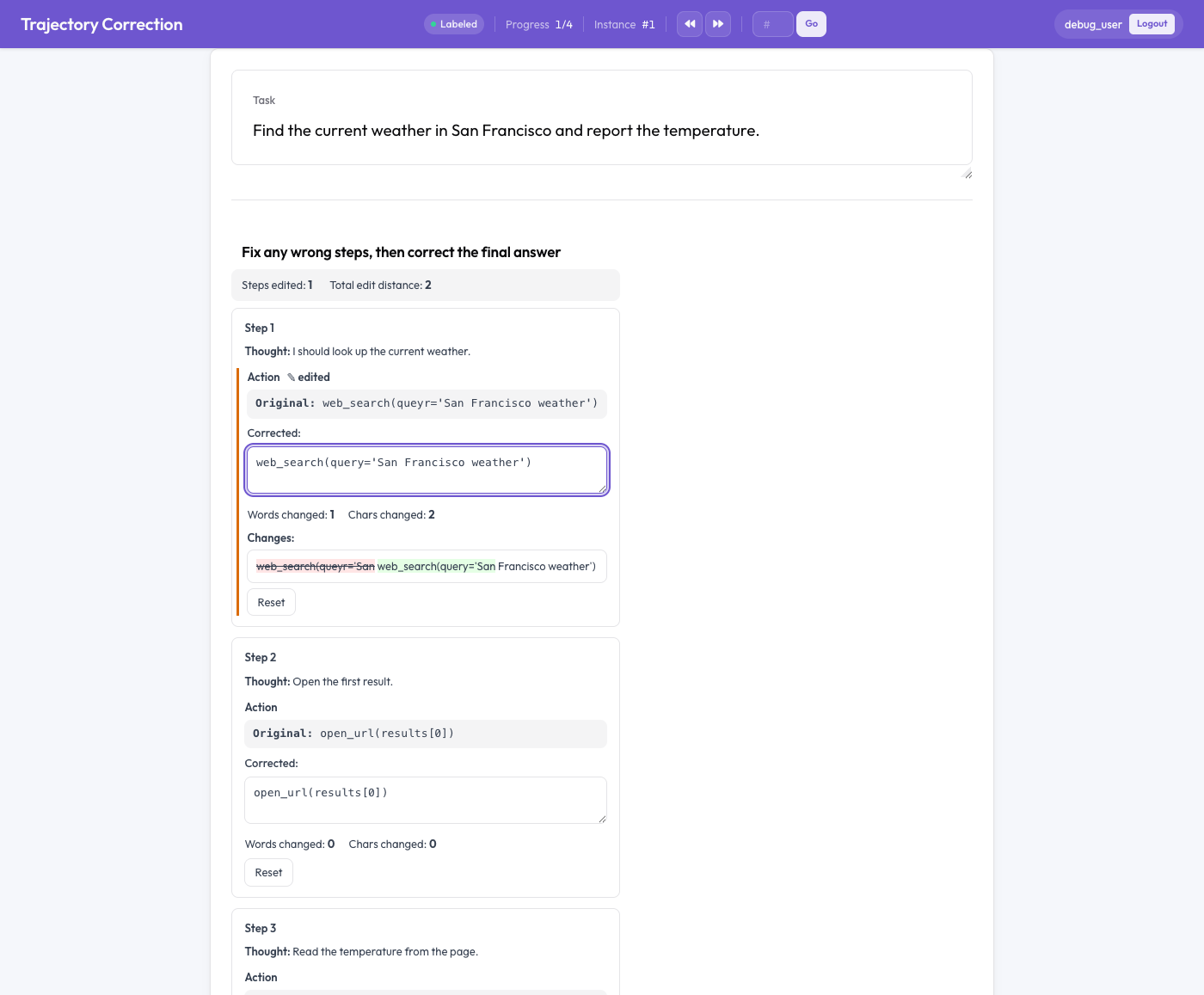 읽기 전용 원본과 단어 수준 diff를 갖춘 편집 가능한 수정 상자로 표시된 에이전트 단계
읽기 전용 원본과 단어 수준 diff를 갖춘 편집 가능한 수정 상자로 표시된 에이전트 단계
빠른 시작
저장소 루트에서 포함된 예제를 실행합니다.
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000작동 방식
각 에이전트 단계는 원본 텍스트(읽기 전용)와 원본이 미리 채워진 편집 가능한 수정 상자를 보여주는 카드로 렌더링됩니다. 주석자가 입력하면:
- 실시간 단어 수준 diff가 삽입(녹색)과 삭제(빨간색 취소선)를 강조 표시하고,
- 변경된 단어와 문자가 집계되며,
- 변경된 필드에 "편집됨" 플래그가 나타납니다.
"재설정" 버튼은 필드별로 원본을 복원합니다. edit_final_answer: true를 사용하면 최종 답변에 자체 편집기가 생깁니다. 아무것도 필수가 아닙니다. 편집되지 않은 트레이스는 단순히 학습 쌍을 생성하지 않습니다.
구성
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer| 옵션 | 기본값 | 설명 |
|---|---|---|
steps_key | steps | 단계 목록을 담는 인스턴스 필드. |
step_text_key | action | 단계별 기본 편집 가능 필드. |
editable_fields | [step_text_key] | 어떤 단계 필드에 편집기를 둘지, 예: [action, thought]. |
show_diff | true | 실시간 단어 수준 diff를 표시합니다. |
show_edit_distance | true | 변경된 단어와 문자를 표시합니다. |
allow_reset | true | 필드별 "원본으로 재설정" 버튼. |
require_reason_on_edit | false | 필드별 "편집 사유" 입력란. |
edit_final_answer | false | 최종 답변용 편집기를 추가합니다. |
final_answer_key | final_answer | 최종 답변을 담는 인스턴스 필드. |
데이터 형식
스키마는 인스턴스의 steps_key 아래에서 단계를 읽습니다. 각 단계는 필드(action, thought 등)를 편집할 수 있는 객체입니다. 순수 문자열 단계는 step_text_key 필드로 편집됩니다.
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}내보내기
trajectory_correction 내보내기 도구를 실행합니다. 세 개의 파일을 작성합니다.
trajectory_corrections.json— 모든 레코드:original_trace, 재구성된corrected_trace, 그리고 편집 거리와 사유가 포함된 필드별edits.trajectory_sft.jsonl— 편집된 트레이스당 한 줄:{"prompt": <task>, "completion": <corrected_trace>}.trajectory_dpo.jsonl— 편집된 트레이스당 한 줄:{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}.
편집되지 않은 트레이스는 집계되지만 SFT/DPO에서는 제외됩니다. 변경되지 않은 궤적으로 학습해도 얻을 것이 없기 때문입니다. 건너뛴 개수는 내보내기 통계에 표시됩니다. 여러 주석자가 있는 경우, 트레이스를 편집한 각 주석자가 하나의 SFT/DPO 레코드를 생성합니다.
참고 사항 및 제한
- diff는 단어 수준입니다. 공백이 없는 코드 형태의 도구 호출의 경우, 한 글자만 고쳐도 단일 토큰이 통째로 변경된 것처럼 표시될 수 있습니다. 문자 거리 카운터가 정확한 신호입니다.
- 동일한 트레이스에서 단계별 정확성이나 오류 분류 체계도 원한다면 단계 수준 채점과 함께 사용하세요.
관련 항목
- 3분할 트레이스 평가 — 읽기 전용 추론, 호출, 답변 보기
- 에이전트형 주석 — 에이전트 트레이스 표시 및 평가 패턴
- 내보내기 형식 — 전체 내보내기 도구 참조
구현 세부 사항은 소스 문서를 참조하세요.