심사자 ↔ 사람 정렬
LLM 심사자가 사람의 골드 라벨과 얼마나 잘 일치하는지 측정합니다. Potato는 주석이 달린 인스턴스에 대해 심사자를 실행하여 Cohen's kappa, 혼동 행렬, 불일치 목록을 계산하고, 루브릭을 다듬어 가는 동안 일치도를 추적합니다.
심사자 정렬은 LLM 심사자가 사람의 골드 라벨과 얼마나 잘 일치하는지 측정하고 조정합니다. Potato는 주석자가 이미 라벨링한 인스턴스에 대해 구성 가능한 LLM-as-a-judge를 실행하여 Cohen's κ, 혼동 행렬, 불일치 목록을 계산하고, 심사자 루브릭을 편집하는 동안 κ를 추적합니다. 인라인 모드를 켜면 주석 작업 중에 심사자의 판정이 사람 라벨 옆에 표시되며, 실시간 κ도 함께 나타납니다.
이는 LangSmith Align Evals나 Evidently 같은 도구가 사용하는 표준적인 「심사자를 약 100~200개의 골드 라벨에 정렬한다」 루프입니다. 사람 라벨을 수집하고, 심사자를 실행하고, 불일치를 검토하고, 루브릭을 다듬은 뒤, 일치도가 충분히 높아질 때까지 다시 실행합니다.
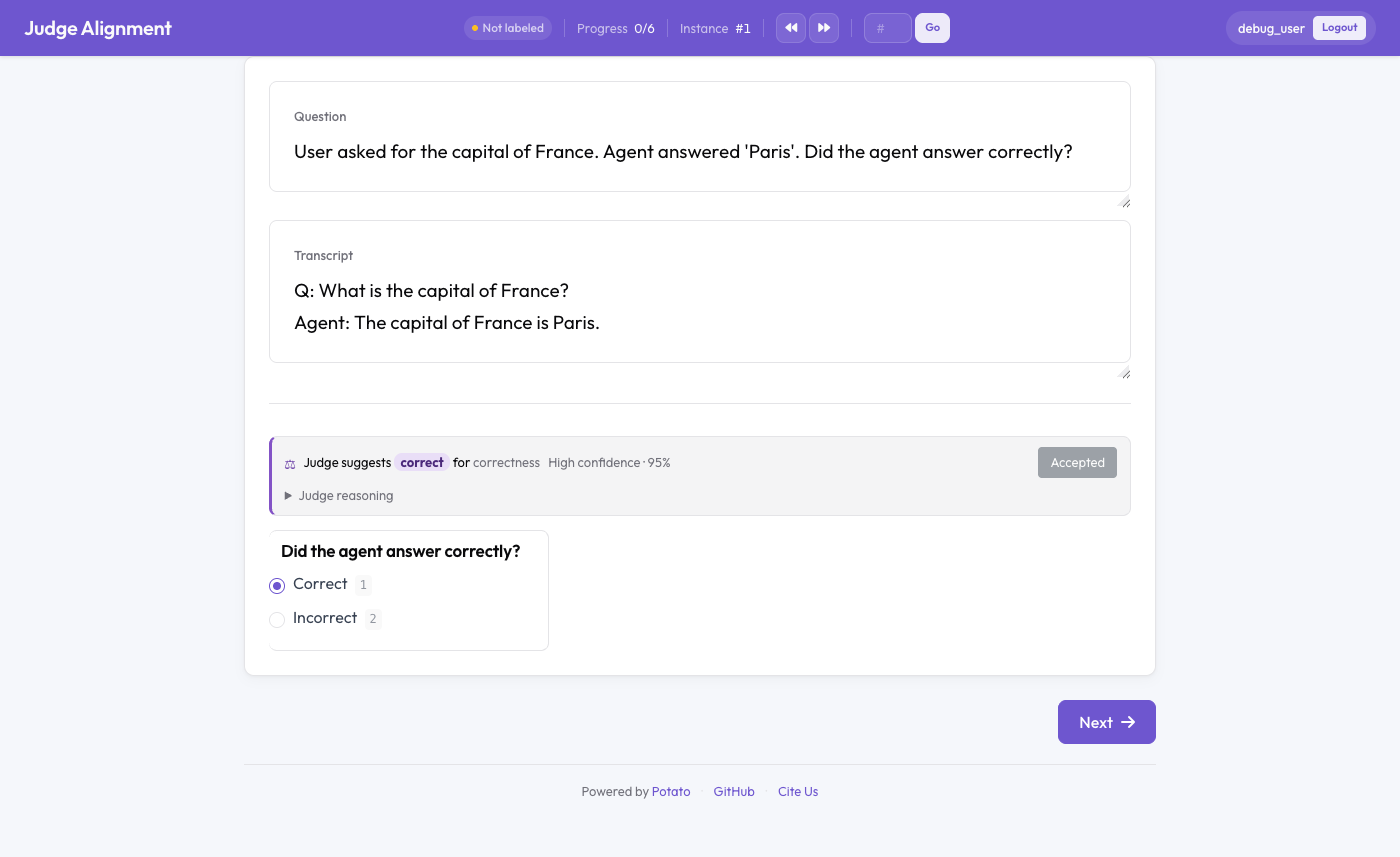 실시간 kappa와 함께 사람 주석 옆에 표시된 LLM 심사자의 판정
실시간 kappa와 함께 사람 주석 옆에 표시된 LLM 심사자의 판정
구성
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict exists적용 범위는 단일 선택 범주형 스킴(radio, select, likert)입니다. judge_alignment.schemas가 설정되어 있으면 해당 스킴만 심사하고, 그렇지 않으면 모든 범주형 스킴을 심사합니다.
심사자 실행
심사자는 관리자 API에서 실행합니다. 예측 결과는 프롬프트 버전별로 캐시되므로 재실행 비용이 저렴합니다.
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'보정하려면 편집한 루브릭을 전달하세요. 이렇게 하면 새 프롬프트 버전이 생성되어 라운드별로 κ를 비교할 수 있습니다.
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'정렬 보고서
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
X-API-Key 헤더를 보내세요. 각 스킴별로 보고서는 다음을 표시합니다.
- Landis–Koch 해석, 일치율, 비교한 인스턴스 수와 함께 표시되는 Cohen's κ.
- 혼동 행렬(행은 사람 골드, 열은 심사자).
- 인스턴스, 사람 라벨, 심사자 라벨, 신뢰도, 심사자의 추론을 담은 불일치 표.
- 버전별 평균 κ를 표시하여 보정 진행 상황을 한눈에 볼 수 있는 프롬프트 버전 이력.
사람 골드는 각 인스턴스에 대한 주석자 간 다수결입니다.
인라인 모드
inline.enabled를 사용하면 각 주석 페이지에 해당 인스턴스에 대한 캐시된 심사자 판정(라벨, 신뢰도, 펼칠 수 있는 추론)이 작업의 실시간 κ와 함께 표시됩니다. 「수락(Accept)」을 누르면 일치하는 선택지가 채워집니다. 사람이 저장할 때마다 사람↔심사자 비교가 기록되어 실시간 일치도에 반영됩니다. 캐시된 판정이 없을 때 심사자를 실시간으로 호출하려면 compute_on_demand: true로 설정하세요. 그렇지 않으면 배치를 미리 실행하는 편이 더 빠릅니다.
참고 사항 및 제한
- 이 버전에서 보정은 수동입니다. 루브릭을 편집하고 다시 실행하세요. 자동 프롬프트 최적화는 범위를 벗어납니다.
- 적용 범위는 단일 선택 범주형 스킴입니다. 스팬과 자유 텍스트 심사는 향후 과제입니다.
- 안정적인 κ를 얻으려면 약 100~200개의 라벨링된 인스턴스로 구성된 집중된 골드 세트에 대해 심사자를 실행하세요.
관련 항목
- LLM 심사자 보정 — 보정 오차를 포함한 다중 심사자, 사람 블라인드 보정
- 분류 대기열 — 가장 유익한 항목을 사람에게 먼저 보냄
- 주석자 간 일치도 가이드 — kappa 지표를 자세히 설명
구현 세부 사항은 원본 문서를 참조하세요.