QDA 模式
将 Potato 变为协作式定性数据分析工作区。QDA 模式将动态码本、原位编码、分析备忘录、案例与全文搜索组合在一起,用于为访谈记录、开放式问卷回答和田野笔记编码。
QDA 模式将 Potato 变为定性数据分析(QDA)工作区。 设置 qda_mode.enabled: true,Potato 便会把动态码本、原位编码、分析备忘录、案例与全文搜索组合成一套统一的工作流,用于通读和编码整个语料库。它是 NVivo、ATLAS.ti、MAXQDA 和 Dedoose 等工具的免费、开源、基于网页的替代方案。
定性数据分析 是指为非结构化文本(访谈记录、开放式问卷回答、田野笔记或文档)的段落赋予编码,并将这些编码构建为主题的实践。QDA 模式是同时启用 Potato 各项定性编码功能的单一开关,其默认值针对一位分析者贯穿整个语料库工作的场景进行了调优。
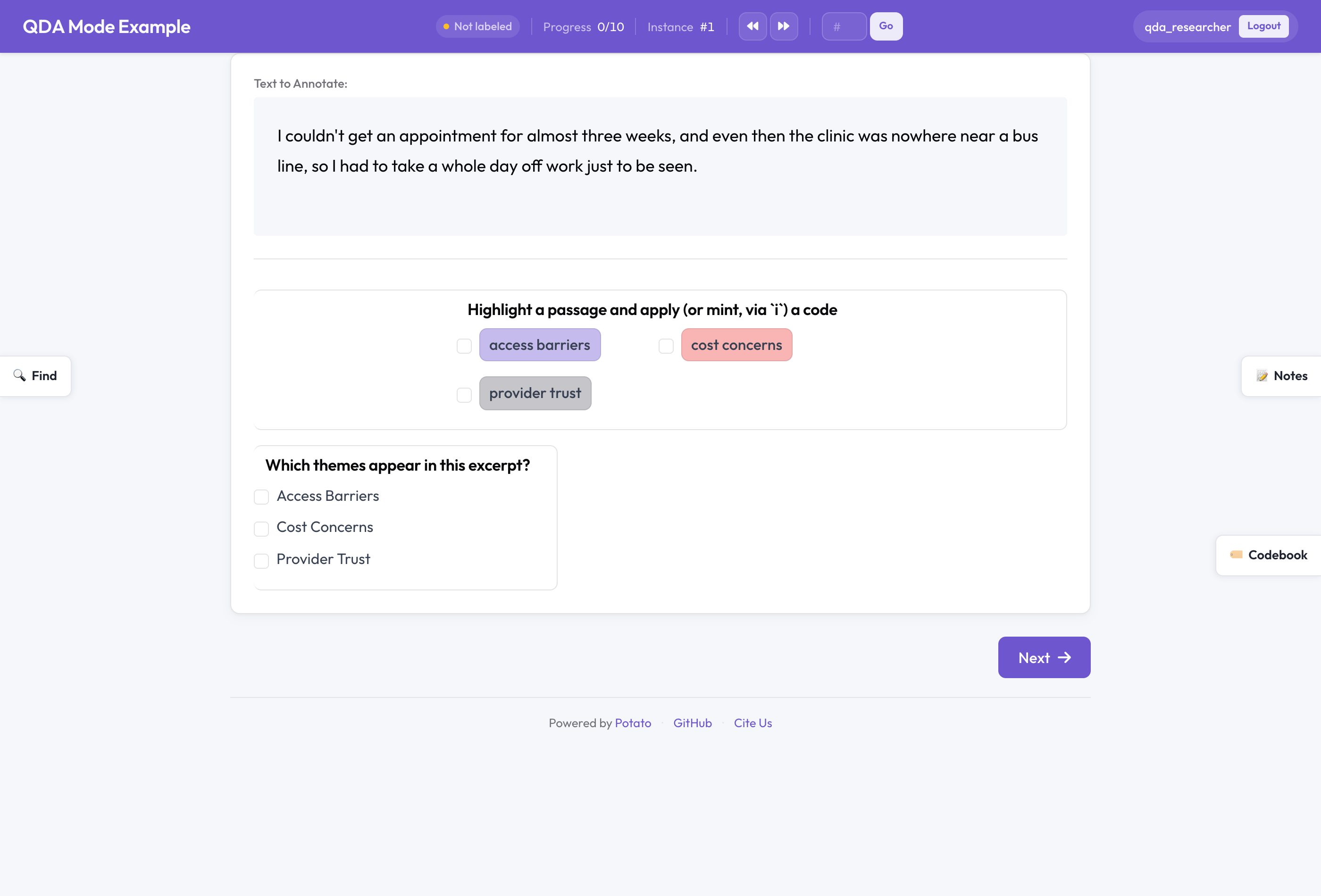 处于 QDA 模式的 Potato:一个以码本为支撑的跨度方案,配有“查找”搜索面板以及“备忘录”和“码本”侧边栏
处于 QDA 模式的 Potato:一个以码本为支撑的跨度方案,配有“查找”搜索面板以及“备忘录”和“码本”侧边栏
QDA 模式改变了什么
启用 qda_mode 假定的是单编码者姿态(一位分析者处理整个语料库,无需保护标注者间抽样)。在此前提下,它将 Potato 的通用功能切换为其定性默认值:
| 功能 | 标准默认值 | 在 qda_mode.enabled: true 下 |
|---|---|---|
| 码本模式 | fixed | open —— 在编码时添加、重命名、改色、移动或删除编码 |
| 备忘录侧边栏 | 关闭 | 开启 |
| 案例 | 关闭 | 开启,并带自动检测 |
| 标注者搜索并认领 | 关闭 | 可用(通过 search.annotator_claim: true 选择启用) |
| 原位编码键 | i | i(在任何标记为 codebook: true 的 span 方案上生效) |
每一项默认值都可被覆盖。QDA 模式只改变起点。即使在 QDA 模式下,众包后端也会强制将码本锁定为 fixed,因此付费标注者无法重塑共享码本。
快速开始
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true # compose codebook + memos + cases + search
codebook_invivo_key: i # mint a code from a text selection
cases: # group excerpts into units of analysis
enabled: true
key: participant_id
attributes: [condition]
search: # let the coder jump to any matching excerpt
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span # span + codebook = in-vivo coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]cases、search 和备忘录代码块都是可选的,因为 QDA 模式已经开启了案例和备忘录。只有在需要调整默认值时才写它们,例如选择 cases.key 或启用 annotator_claim。
从仓库根目录运行随附的示例:
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000各个组成部分
- 动态码本。 共享、可变的编码集合。通过
codebook: true让某个方案加入;在 QDA 模式下,你可以在阅读时扩充并重组码本。 - 原位编码。 在同时为
codebook: true的span方案上,选中一段文字并按下原位键(codebook_invivo_key,默认i),即可直接从所选文本铸造一个编码。编排器会显示近似重复的编码,让你复用而非碎片化。 - 备忘录。 附加到某个实例或某段具体文本选区的分析性笔记,可设为仅你可见或与团队共享。
- 案例。 将摘录归组为分析单元(一位参与者、一份文档),并提取案例级属性,如
condition,从而让管理员编码交叉表能够将编码与参与者层面的变量进行制表。 - 搜索。 对语料库进行 FTS5 全文搜索。配合
annotator_claim: true,编码者可将任意匹配项拉入自己的队列。
配置
qda_mode:
enabled: true
memos:
enabled: true # memo defaults under QDA Mode
show_sidebar_by_default: true
codebook:
enabled: true
mode: open # open | extensible | fixed| 选项 | 默认值 | 描述 |
|---|---|---|
qda_mode.enabled | false | 主开关。初始化 QDA 模式并应用上述定性默认值。 |
qda_mode.memos.enabled | true | 分析备忘录是否启用。 |
qda_mode.memos.show_sidebar_by_default | true | 备忘录侧边栏是否默认打开。 |
qda_mode.codebook.enabled | true | 码本是否启用。 |
qda_mode.codebook.mode | open | 标注者的编辑权限:open、extensible 或 fixed。等同于顶层的 codebook_mode。 |
未知的 qda_mode.* 键会被保留而非拒绝,因此你可以为后续阶段才落地的功能编写向前兼容的 YAML。
导出你的编码
两个导出器可将已编码数据转化为定性研究的交付成果:
codebook—— 每个编码一行,含其层级、描述、颜色与使用次数。quotation_report—— 每个已编码跨度一行:引文、其字符偏移量、来源实例以及编码者。添加include_memos=true可追加备忘录行。
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csvcodebook、quotation_report 以及标注者间一致性功能(Cohen's 与 Fleiss' kappa)均在 2.5.0 定性编码版本中发布。版本历史请参见 更新内容。
相关内容
有关实现细节,请参见 源文档。