评判员 ↔ 人工标注的一致性
衡量 LLM 评判员与你的人工黄金标签的契合程度。Potato 在已标注的实例上运行评判员,计算 Cohen's kappa、混淆矩阵和分歧清单,并在你优化评分细则时持续跟踪一致性。
评判员一致性用于衡量并调校 LLM 评判员与你的人工黄金标签之间的契合程度。 Potato 在标注员已经标注过的实例上运行一个可配置的 LLM-as-a-judge,计算 Cohen's κ、混淆矩阵和分歧清单,并在你修改评判细则时跟踪 κ 的变化。开启内联模式后,标注过程中评判员的结论会显示在人工标签旁边,并附带实时的 κ。
这就是 LangSmith Align Evals、Evidently 等工具所采用的标准「把评判员对齐到大约 100–200 个黄金标签」循环:收集人工标签、运行评判员、检查分歧、优化细则,并反复运行直到一致性足够高。
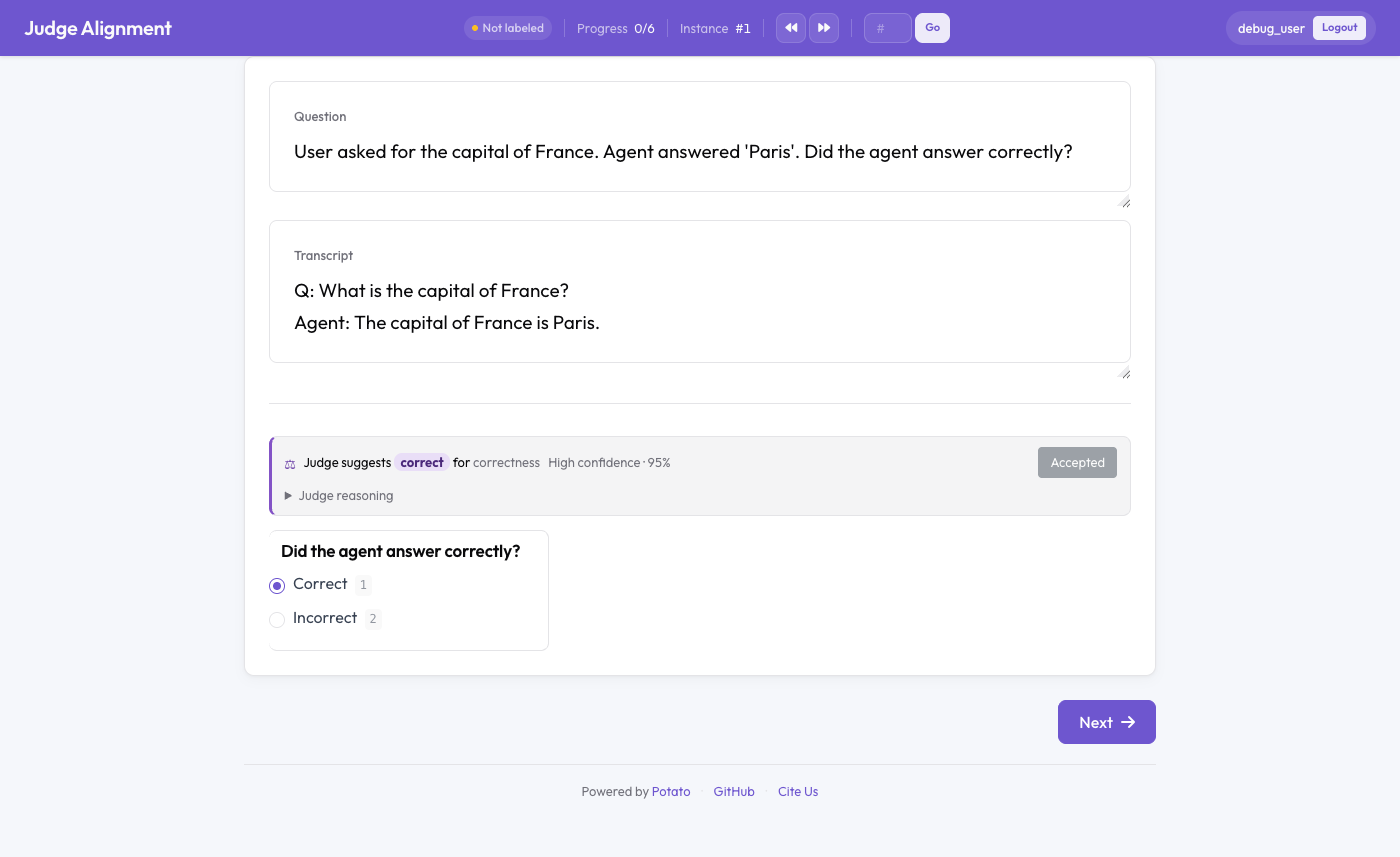 LLM 评判员的结论显示在人工标注旁边,并附带实时 kappa
LLM 评判员的结论显示在人工标注旁边,并附带实时 kappa
配置
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict exists适用范围是单选类别方案(radio、select、likert)。如果设置了 judge_alignment.schemas,则只会评判这些方案;否则会评判所有类别方案。
运行评判员
从管理员 API 运行评判员。预测结果会按提示词版本缓存,因此重复运行的成本很低:
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'要进行校准,可以传入经过修改的评判细则。这会创建一个新的提示词版本,从而让你能够在不同轮次之间对比 κ:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'一致性报告
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
请发送 X-API-Key 请求头。对于每个方案,报告会显示:
- Cohen's κ,附带 Landis–Koch 解释、一致率以及参与对比的实例数量。
- 一个混淆矩阵(行是人工黄金标签,列是评判员)。
- 一个分歧表,包含实例、人工标签、评判员标签、置信度以及评判员的推理过程。
- 提示词版本历史,显示每个版本的平均 κ,从而让校准进展一目了然。
人工黄金标签是各标注员对每个实例投票的多数结果。
内联模式
启用 inline.enabled 后,每个标注页面都会显示该实例对应的评判员缓存结论——包括其标签、置信度和可展开的推理过程——同时显示该任务的实时 κ。点击「接受」会自动填入匹配的选项。每次人工保存都会记录一次人工↔评判员的对比,从而纳入实时一致性的计算。设置 compute_on_demand: true 可在没有缓存结论时实时调用评判员;否则建议预先批量运行,这样速度更快。
注意事项与限制
- 本版本的校准是手动进行的:修改细则并重新运行。自动化的提示词优化不在范围之内。
- 适用范围是单选类别方案。跨度(span)和自由文本的评判属于未来工作。
- 在大约 100–200 个已标注实例的集中黄金集上运行评判员,可获得更稳定的 κ。
相关内容
如需了解实现细节,请参阅源文档。