多智能体团队评估
按团队结构而非扁平的对话记录来标注多智能体系统。Potato 提供可点击的智能体交互图、跨智能体失败归因、交接审查、单智能体与整队评分卡、工具争用时间线,以及涌现行为标记。
多智能体系统的失败方式与单个智能体不同:故障发生在智能体之间、在某次交接处,或源于团队的组织方式。评估它意味着把结果归因到是哪个智能体、哪一步、哪次交接,而不只是给一段扁平的对话记录打分。 Potato 为此提供了一组专门构建的标注界面:可点击的交互图、失败归因、交接审查、单智能体与整队评分卡、工具争用时间线,以及跨泳道的涌现行为标记。
这些都建立在智能体轨迹视图与 MAST 失败分类体系之上。每个 schema 在渲染时都从轨迹本身推导出其中的智能体、步骤与交接,因此标注者只能从运行中实际发生的内容中进行选择。
交互图(agent_interaction_graph)
整次运行渲染为一张有向图:节点是智能体,边是它们之间的消息与交接转移(边越粗表示越频繁),布局根据轨迹自动生成。标注者点击节点以标记关键路径,点击边以在 正常 → 关键 → 有问题 之间循环切换。对于"我如何看清一次多智能体运行的结构"这个问题,这是最清晰的答案,也是通用标注工具不提供的一种界面。
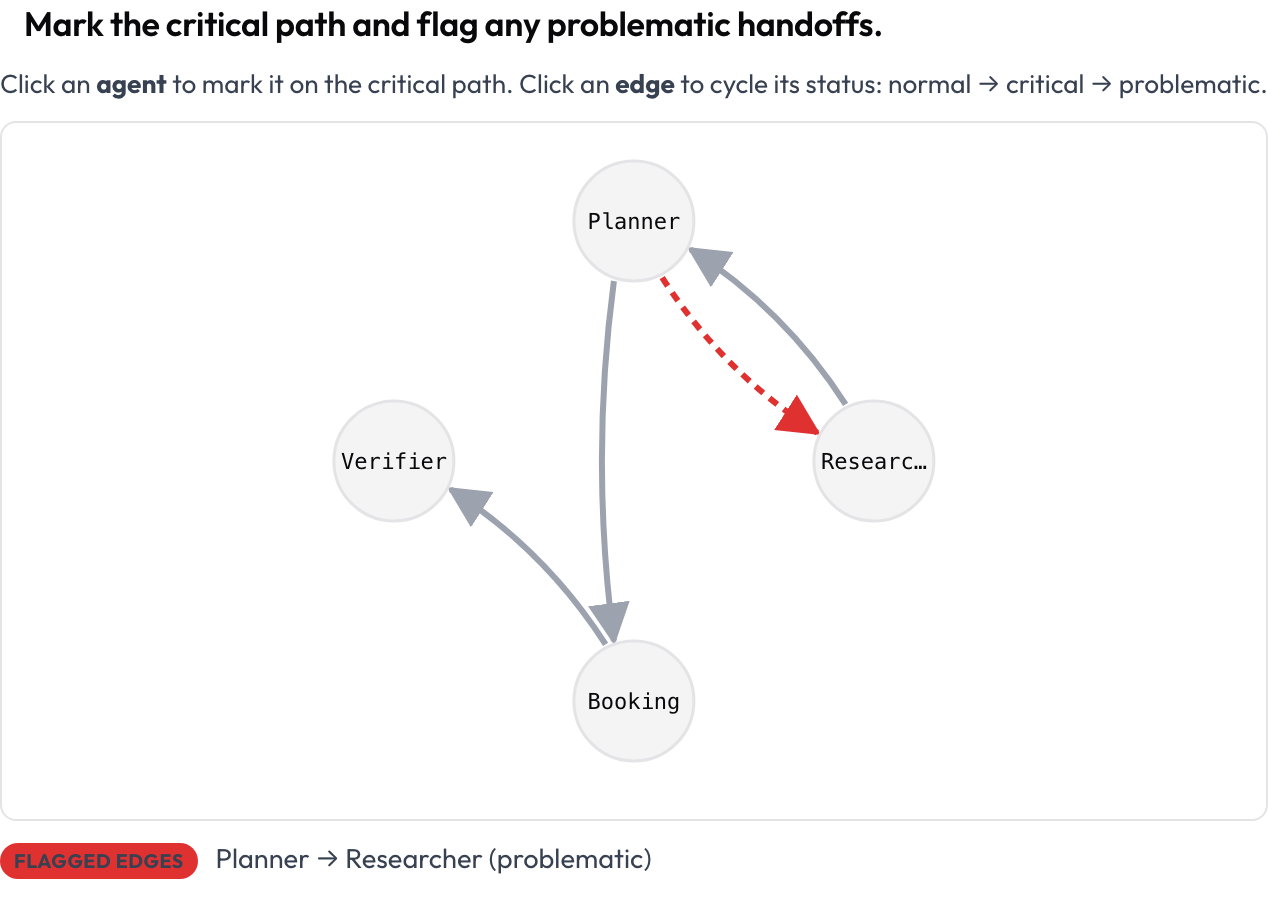 Mark the critical path and flag problematic handoffs on a clickable agent-interaction graph
Mark the critical path and flag problematic handoffs on a clickable agent-interaction graph
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agent存储为 {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}。每个节点和边都可通过键盘聚焦,并有一段实时文本摘要列出关键节点和被标记的边,因此含义绝不会仅靠颜色来传达。
跨智能体失败归因(failure_attribution)
当一个团队失败时,有用的标签是来自失败归因文献的**(责任智能体、决定性步骤、原因)**三元组(Zhang 等人,Which Agent Causes Task Failures and When?,ICML 2025,Who&When 数据集)。智能体下拉框和步骤选择器由轨迹自身的回合填充,因此标注者会把失败归因到一个真实的智能体和一个真实的步骤上。
 Attribute a multi-agent failure to the responsible agent, the decisive step, and why
Attribute a multi-agent failure to the responsible agent, the decisive step, and why
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the trace存储为 {"responsible_agent", "decisive_step", "reason"}。将它与一个 radio 结果 schema(成功/失败)搭配使用,使归因只在失败的运行上触发。
交接审查(handoff_review)
每一次交接,即一个智能体将控制权传给另一个智能体,都成为一个可标注的一等对象。只要行动智能体在相邻回合之间发生变化,Potato 就会生成一张交接卡片 A → B;标注者标记智能体间的失配并评定交接质量。这些失败模式以 MAST 的智能体间类别和"回声"现象为依据(Zhang 等人,2025)。
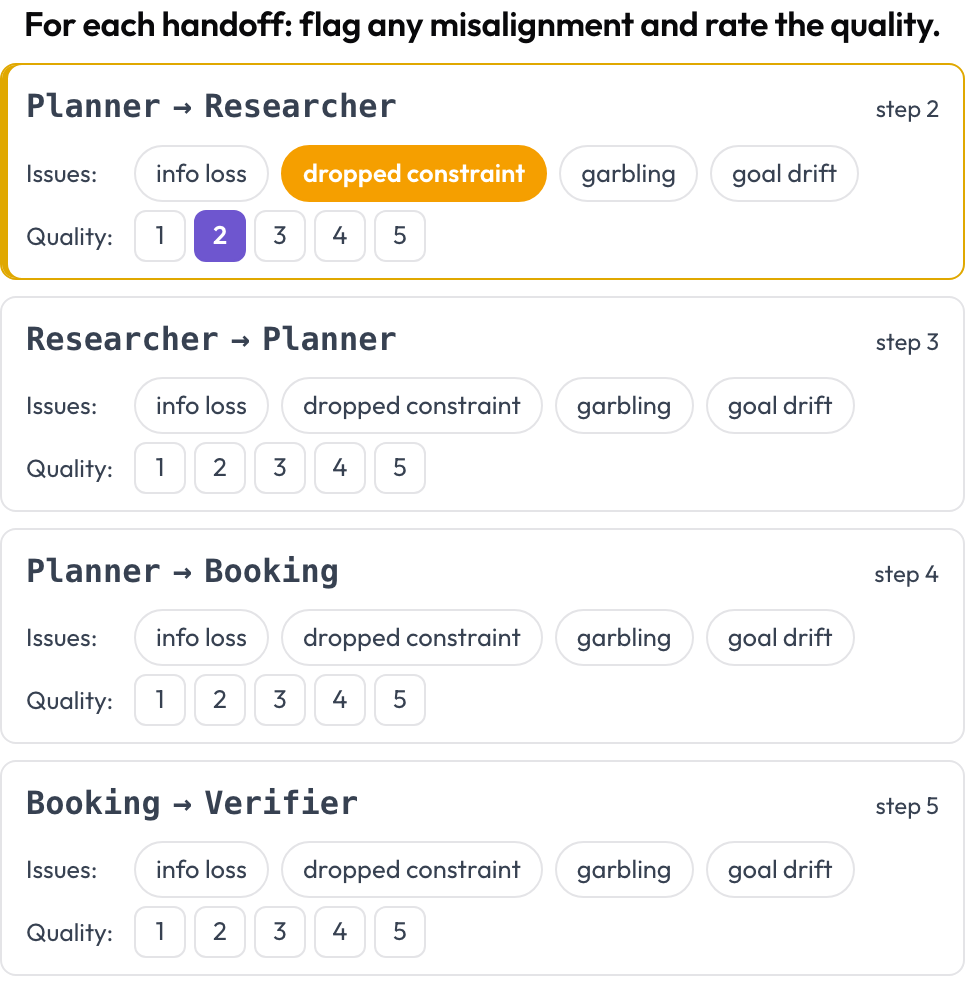 Flag inter-agent misalignment on every handoff and rate its quality
Flag inter-agent misalignment on every handoff and rate its quality
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5交接在渲染时从轨迹中推导出来,因此无需手动设置。存储为一个 {index, step, from, to, flags, quality} 列表。
单智能体与整队评分卡(agent_scorecard)
在两个层级上同时为一次运行打分(MultiAgentBench,Zhou 等人,ACL 2025):每个智能体获得各维度的分数(角色忠实度、贡献度、协调性),团队获得共享维度的分数,并可选地勾选里程碑。智能体的行来自轨迹自身的回合,因此该矩阵与实际参与者相匹配。
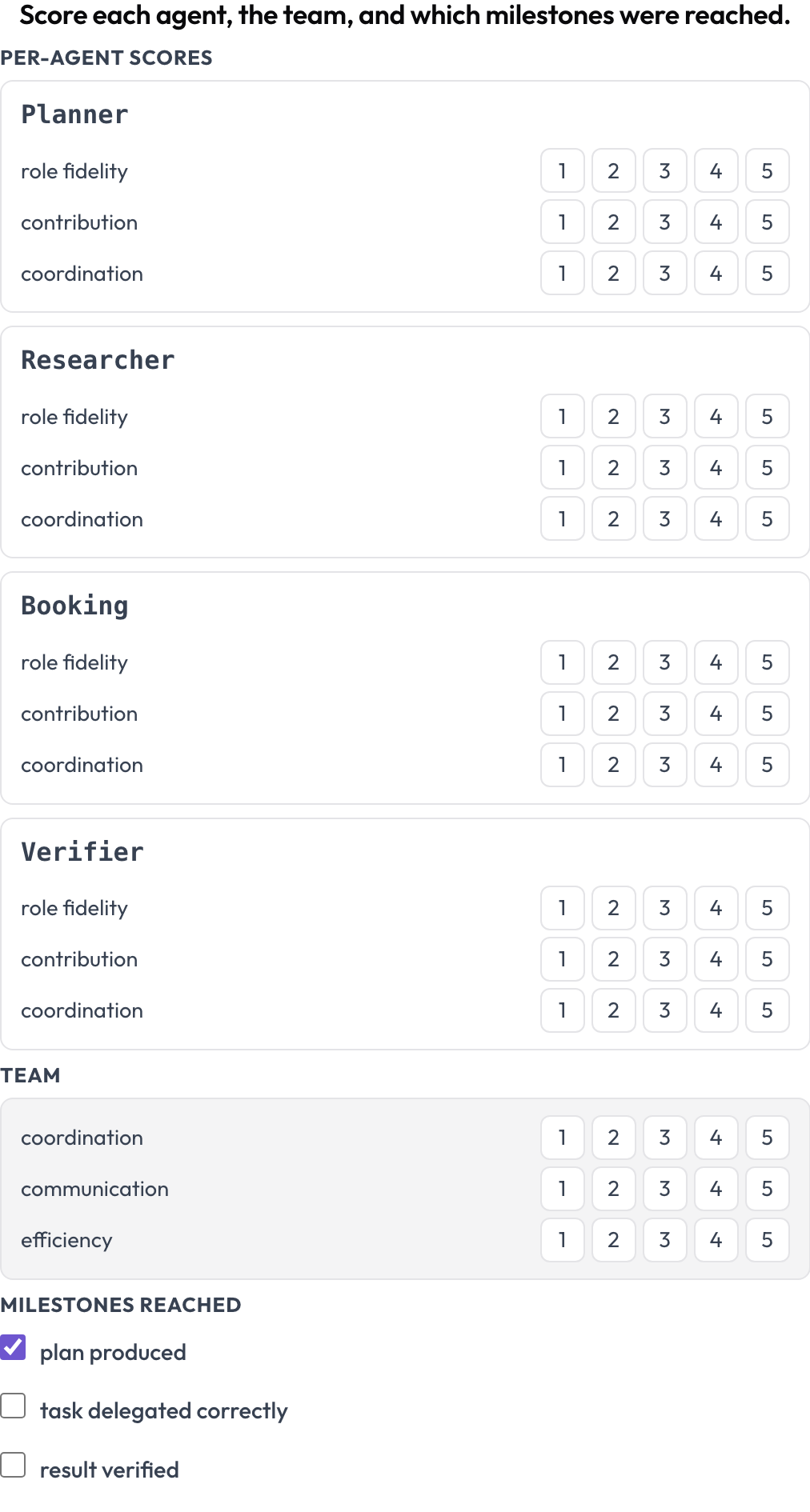 Score every agent on role fidelity, contribution, and coordination, plus the team and milestones
Score every agent on role fidelity, contribution, and coordination, plus the team and milestones
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optional存储为 {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}。
工具/资源争用时间线(tool_contention)
跨智能体的并发工具与资源使用会渲染在一条多泳道时间线上,每个智能体一条泳道。两次调用在重叠时间内触及同一资源的区域会跨泳道高亮,并列出以供分类:死锁、循环等待、竞态条件或良性(DPBench,2026)。这就是你捕捉逐回合对话记录所隐藏的并发故障的方式。
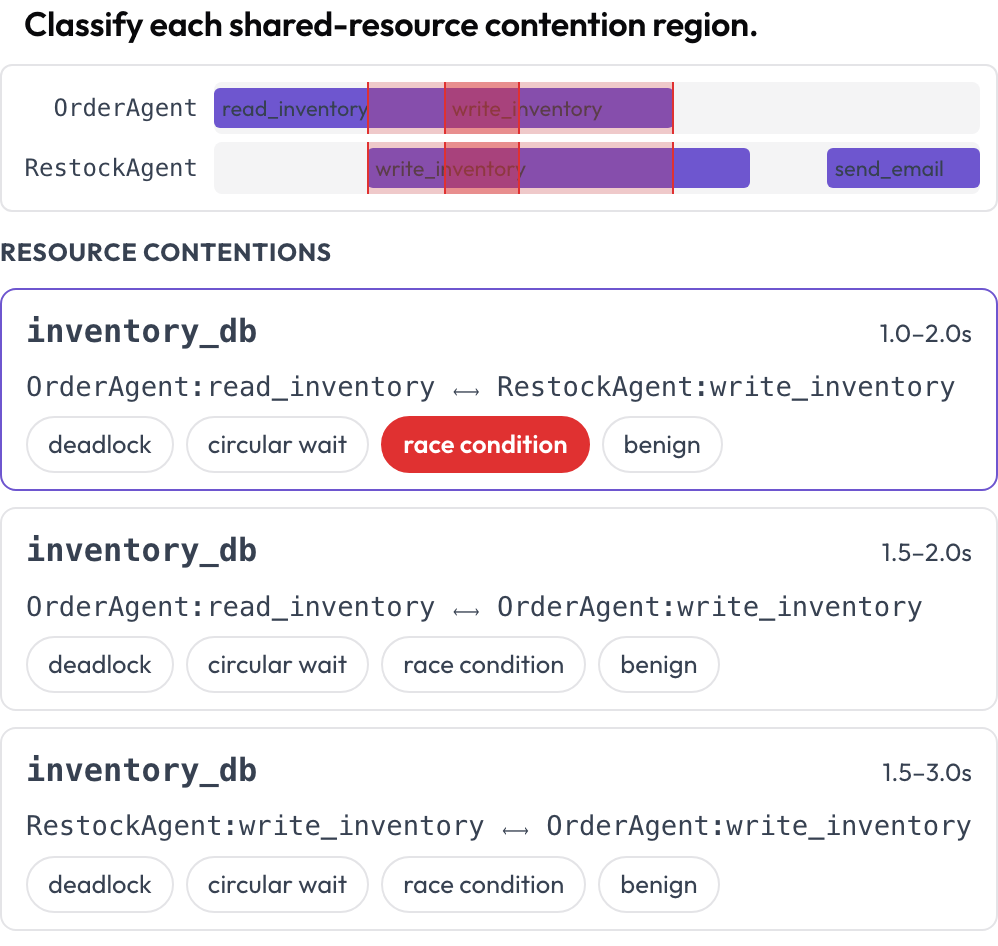 Spot deadlocks and race conditions on a per-agent tool-call timeline
Spot deadlocks and race conditions on a per-agent tool-call timeline
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]争用区域在渲染时计算得出(相同的 resource、重叠的区间)。存储为 {"contentions": {idx: label}}。
跨泳道涌现行为(emergent_behavior)
有些失败是集体性的:合谋、群体思维、级联错误、角色漂移。一种涌现行为并不是一段连续的文本跨度;它是一个参与回合的集合,可能来自不同的智能体。对于每一种行为,标注者勾选参与其中的回合并添加备注,即一个以回合集合表达的跨泳道跨度。
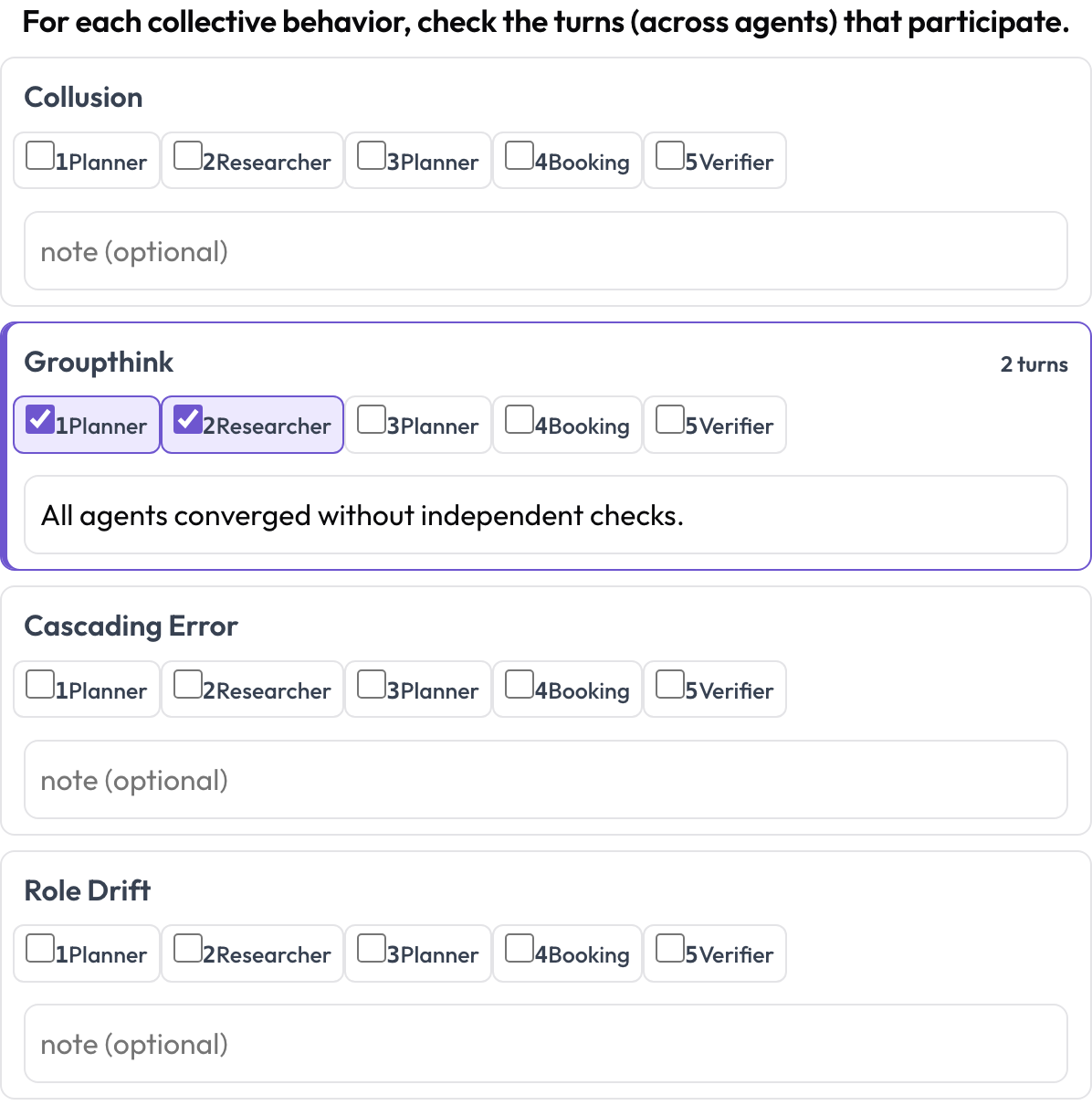 Tag collusion, groupthink, and cascading errors across agents and turns
Tag collusion, groupthink, and cascading errors across agents and turns
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: true存储为 {behavior: {turns: [idx...], note}},只保留非空的行为。
工具调用审查(tool_call_review)
逐一评判每次工具或函数调用:是否选对了工具,参数是否正确,顺序是否得当(对标 BFCL v4 / MCPMark)?工具调用在渲染时从轨迹步骤中提取;每一步的 tool_calls、tool_call 或 action 都会成为一张带工具名称和美化打印参数的卡片。
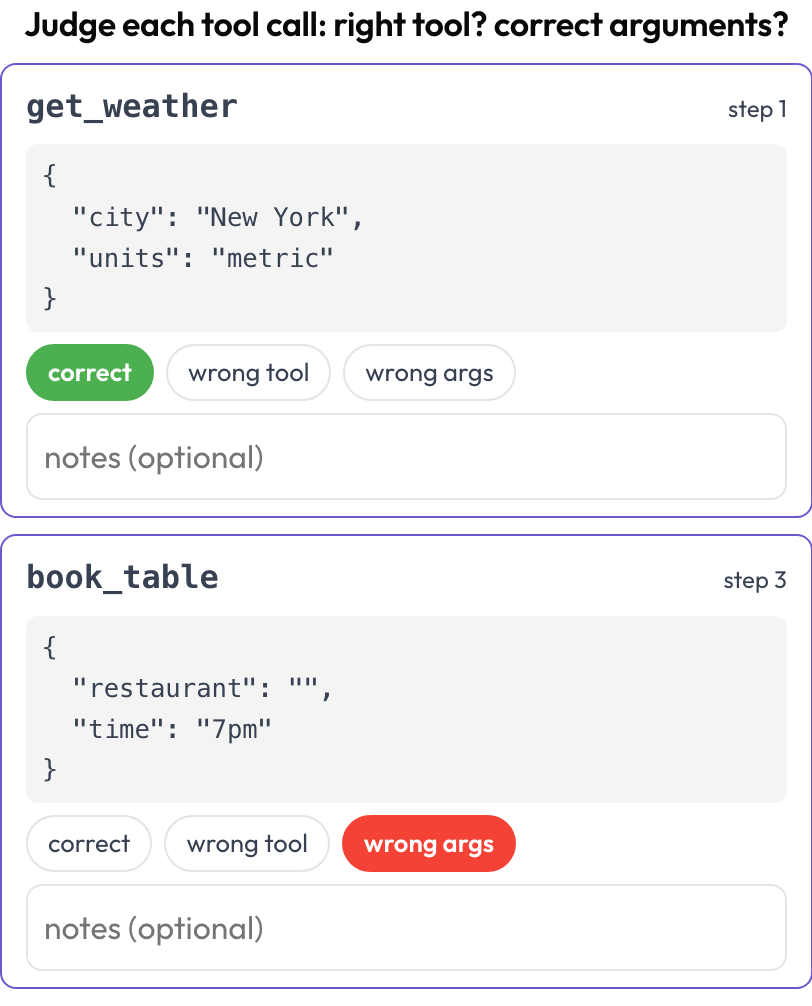 Judge every tool call: right tool, correct arguments, right order
Judge every tool call: right tool, correct arguments, right order
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizable存储为一个 {index, step, tool, verdict, notes} 列表。
步骤粒度的 MAST 标记
你无需新的 schema,就能把 14 种模式的 MAST 失败分类体系(Cemri 等人,Why Do Multi-Agent LLM Systems Fail?,2025)绑定到失败发生的确切步骤(因而也绑定到行动智能体)。把现有的逐步 trajectory_eval schema 配置为以 MAST 模式作为它的 error_types,并按三个 MAST 类别分组。将它与 failure_attribution 和 handoff_review 搭配以实现完整覆盖。
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]选择编排视角
编排架构往往主导一次运行的结果,因此值得将其作为一等标签来捕获。无需新的 schema:一个 radio 确认或纠正该运行的模式,进而引导评估视角以及轨迹的布局方式(顺序型 → 泳道,层级型 → 树,群聊型 → 看板)。
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: true相关内容
- 多模态智能体评估 — GUI、语音、视频与文档智能体 schema
- 标注智能体轨迹 — 逐步错误标注
- 如何评估 AI 智能体 — 智能体评估的各个层级
- 智能体标注 — 轨迹视图配置与数据接入
如需实现细节,请参阅源文档。