用于 SFT/DPO 的轨迹编辑
标注者重写智能体轨迹中的步骤,以修正错误的推理步骤、纠正工具调用或强化最终答案,Potato 会将每个原始/修正对导出为有监督微调目标和 DPO 偏好对。
trajectory_edit 模式让标注者重写智能体轨迹中的步骤,并将每次修正导出为训练数据。 修正错误的推理步骤、纠正打错字的工具调用,或强化最终答案,Potato 都会将修正后的轨迹保存在原始轨迹旁边。随后 trajectory_correction 导出器会将每个 (original, corrected) 对转化为有监督微调(SFT)目标和直接偏好优化(DPO)偏好对。
这让 Potato 不仅是一款评估工具,更成为一款训练数据生产工具。它是步级评分的编辑对应物:标注者不是给轨迹打分,而是修复它,而修复本身就成为了一种学习信号。
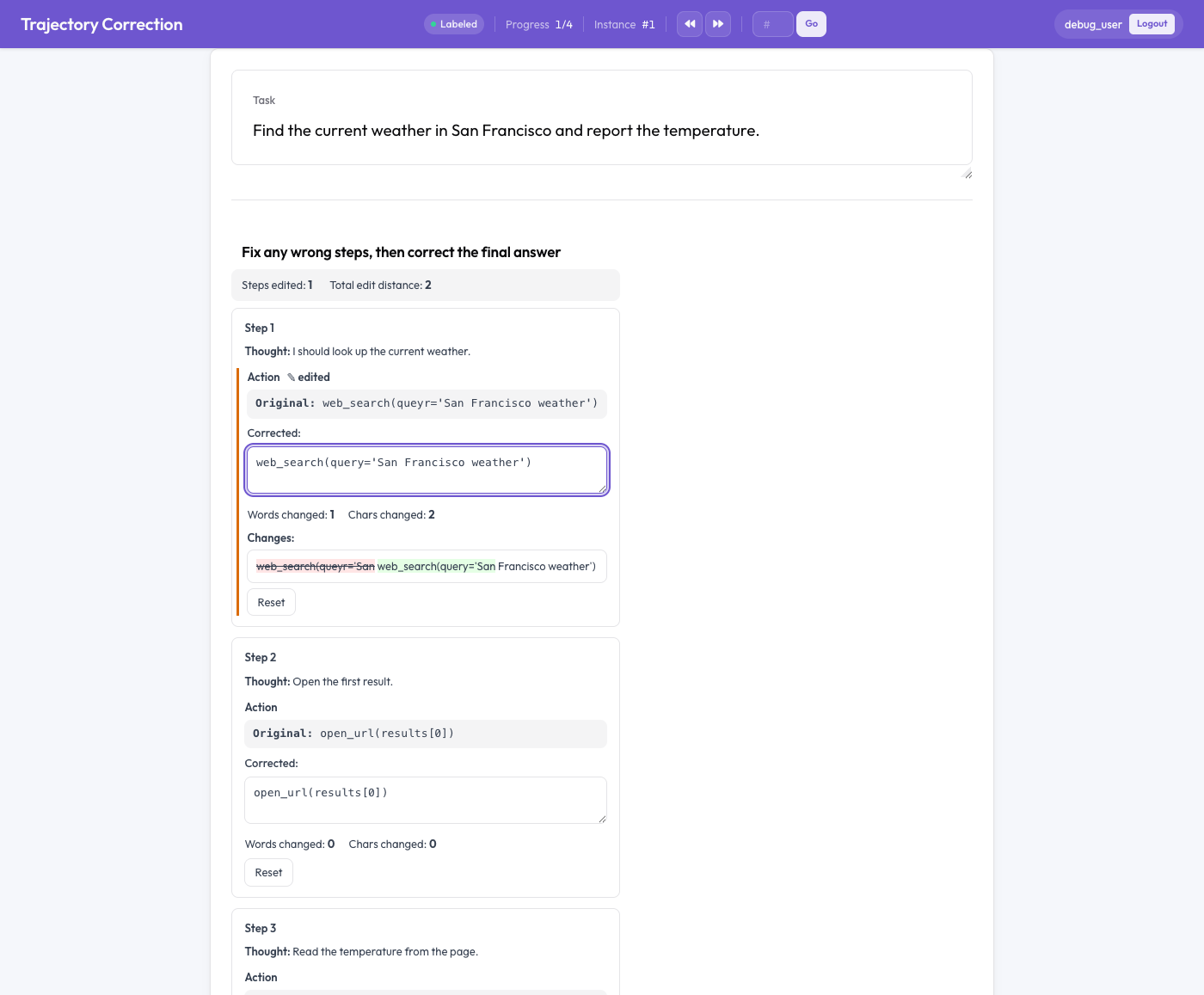 一个智能体步骤,显示一个只读的原始内容和一个可编辑的修正框,并带有词级别的差异对比
一个智能体步骤,显示一个只读的原始内容和一个可编辑的修正框,并带有词级别的差异对比
快速开始
从仓库根目录运行随附的示例:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000工作原理
每个智能体步骤都渲染为一张卡片,显示原始文本(只读)和一个预填了原始内容的可编辑修正框。当标注者输入时:
- 实时的词级别差异对比会高亮显示插入内容(绿色)和删除内容(红色删除线),
- 统计更改的词数和字符数,以及
- 在已更改的字段上出现"已编辑"标记。
"重置"按钮可按字段恢复原始内容。设置 edit_final_answer: true 后,最终答案会获得自己的编辑器。一切都非必填:未经编辑的轨迹根本不会生成训练对。
配置
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer| 选项 | 默认值 | 描述 |
|---|---|---|
steps_key | steps | 保存步骤列表的实例字段。 |
step_text_key | action | 每个步骤默认的可编辑字段。 |
editable_fields | [step_text_key] | 哪些步骤字段获得编辑器,例如 [action, thought]。 |
show_diff | true | 显示实时的词级别差异对比。 |
show_edit_distance | true | 显示更改的词数和字符数。 |
allow_reset | true | 每个字段的"重置为原始"按钮。 |
require_reason_on_edit | false | 每个字段的"编辑原因"输入框。 |
edit_final_answer | false | 为最终答案添加一个编辑器。 |
final_answer_key | final_answer | 保存最终答案的实例字段。 |
数据格式
该模式从实例的 steps_key 下读取步骤。每个步骤都是一个对象,其字段(action、thought 等)可被编辑;纯字符串步骤则作为 step_text_key 字段进行编辑。
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}导出
运行 trajectory_correction 导出器。它会写入三个文件:
trajectory_corrections.json— 包含每条记录:original_trace、重建的corrected_trace,以及带编辑距离和原因的逐字段edits。trajectory_sft.jsonl— 每条已编辑轨迹一行:{"prompt": <task>, "completion": <corrected_trace>}。trajectory_dpo.jsonl— 每条已编辑轨迹一行:{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}。
未编辑的轨迹会被计数但排除在 SFT/DPO 之外,因为在未更改的轨迹上训练毫无意义;被跳过的数量会出现在导出统计中。在多名标注者的情况下,每位编辑过某条轨迹的标注者都会产生一条 SFT/DPO 记录。
注意事项与限制
- 差异对比是词级别的。对于没有空格、类似代码的工具调用,即使只改了一个字符,单个标记也可能显示为整体更改;字符距离计数器才是精确的信号。
- 如果你还想在同一条轨迹上获得逐步正确性或错误分类,可搭配步级评分一起使用。
相关内容
有关实现细节,请参阅源文档。