تقييم الفِرق متعددة الوكلاء
علّق على الأنظمة متعددة الوكلاء حسب بنية الفريق، لا بوصفها نصًّا مسطّحًا. يضيف Potato رسمًا بيانيًا قابلًا للنقر لتفاعل الوكلاء، وعزو الإخفاق عبر الوكلاء، ومراجعة عمليات التسليم، وبطاقات تقييم لكل وكيل ولكل فريق، وخطًّا زمنيًا لتنازع الأدوات، ووسم السلوك الناشئ.
يُخفق النظام متعدد الوكلاء على نحو يختلف عن إخفاق الوكيل المفرد: يقع العطل بين الوكلاء، عند عملية تسليم، أو في طريقة تنظيم الفريق. وتقييمه يعني عزو النتائج إلى أي وكيل، وأي خطوة، وأي عملية تسليم، لا مجرد تسجيل درجة لنصٍّ مسطّح. يضيف Potato مجموعة من واجهات التعليق المصممة لهذا الغرض: رسمًا بيانيًا تفاعليًا قابلًا للنقر، وعزو الإخفاق، ومراجعة عمليات التسليم، وبطاقات تقييم لكل وكيل ولكل فريق، وخطًّا زمنيًا لتنازع الأدوات، ووسم السلوك الناشئ عبر المسارات.
تبني هذه الواجهات على عرض أثر الوكيل وتصنيف الإخفاق MAST. ويشتقّ كل مخطط وكلاءه وخطواته وعمليات تسليمه من الأثر نفسه عند العرض، فيختار المُعلّق من بين ما حدث فعلًا في التشغيل.
رسم التفاعل البياني (agent_interaction_graph)
يُعرض التشغيل بأكمله بوصفه رسمًا بيانيًا موجَّهًا: العُقد هي الوكلاء، والحواف هي انتقالات الرسائل وعمليات التسليم بينهم (تعني الحواف الأثخن تكرارًا أكبر)، مرتّبة تلقائيًا من الأثر. ينقر المُعلّق عقدة لتحديد المسار الحرج وينقر حافة ليُبدّلها normal → critical → problematic. هذا أوضح إجابة عن «كيف أرى بنية تشغيل متعدد الوكلاء»، وهو سطح لا توفّره أدوات التعليق العامة.
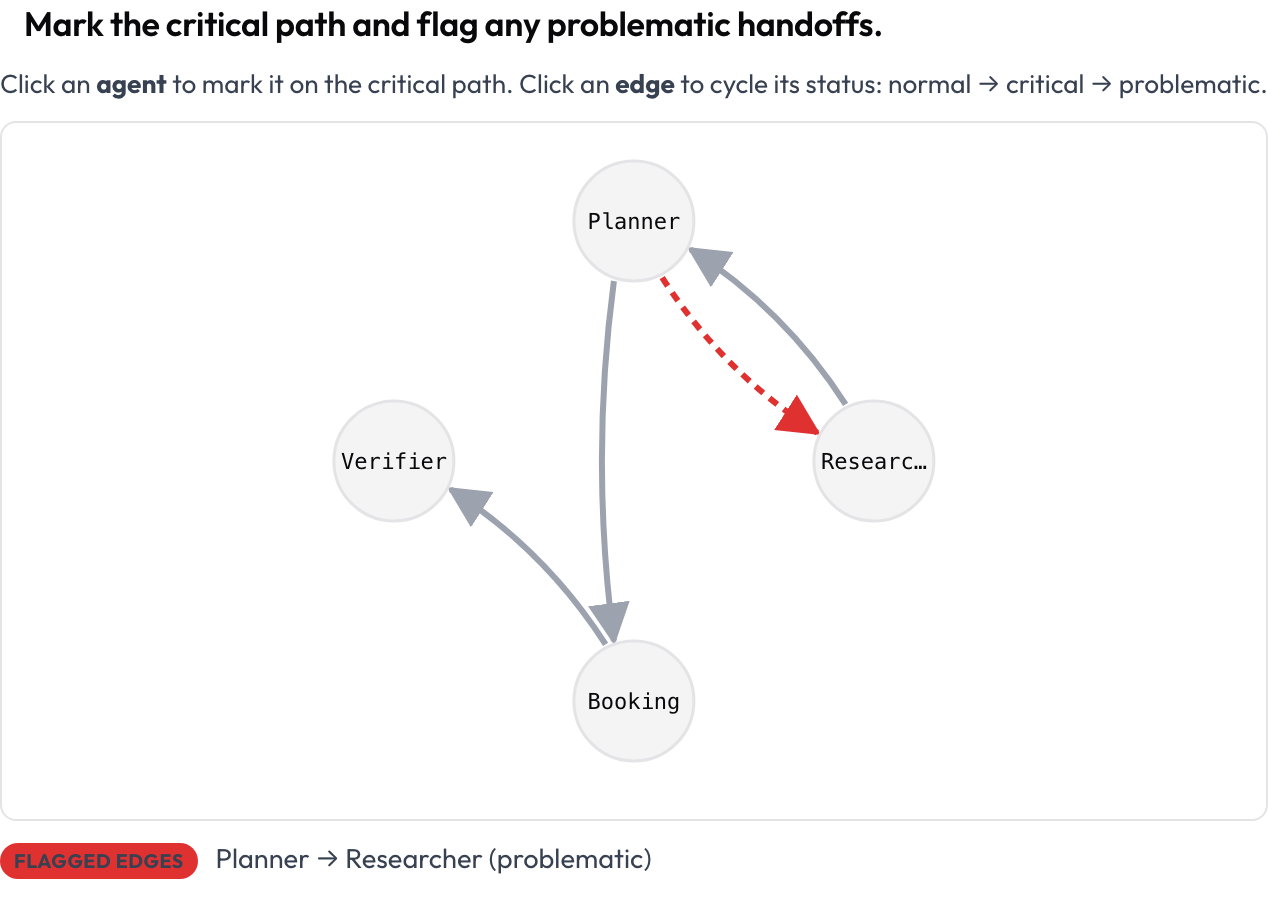 حدّد المسار الحرج ووسِم عمليات التسليم المُشكِلة على رسم تفاعل الوكلاء البياني القابل للنقر
حدّد المسار الحرج ووسِم عمليات التسليم المُشكِلة على رسم تفاعل الوكلاء البياني القابل للنقر
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentيُخزَّن على هيئة {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}. وكل عقدة وحافة قابلة للتركيز بلوحة المفاتيح، ويسرد ملخص نصي حي العُقد الحرجة والحواف الموسومة، فلا يُحمَّل المعنى باللون وحده أبدًا.
عزو الإخفاق عبر الوكلاء (failure_attribution)
حين يُخفق فريق، يكون التصنيف المفيد هو الثلاثي (الوكيل المسؤول، الخطوة الحاسمة، السبب) المستمد من أدبيات عزو الإخفاق (Zhang وآخرون، Which Agent Causes Task Failures and When?، ICML 2025، مجموعة بيانات Who&When). تُملأ قائمة الوكلاء ومُنتقي الخطوة من أدوار الأثر نفسها، فيعزو المُعلّق الإخفاق إلى وكيل حقيقي وخطوة حقيقية.
 اعزُ إخفاق نظام متعدد الوكلاء إلى الوكيل المسؤول والخطوة الحاسمة والسبب
اعزُ إخفاق نظام متعدد الوكلاء إلى الوكيل المسؤول والخطوة الحاسمة والسبب
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the traceيُخزَّن على هيئة {"responsible_agent", "decisive_step", "reason"}. اقرنه بمخطط نتيجة radio (نجاح/إخفاق) كي لا يُفعَّل العزو إلا في التشغيلات المُخفِقة.
مراجعة عمليات التسليم (handoff_review)
تصير كل عملية تسليم، أي تمرير وكيل التحكمَ إلى آخر، كائنًا من الدرجة الأولى للتعليق عليه. حيثما يتغيّر الوكيل الفاعل بين دورين متتاليين، يُصدر Potato بطاقة تسليم A → B؛ ويضع المُعلّق علامة على عدم المواءمة بين الوكلاء ويقيّم جودة التسليم. وتستند أنماط الإخفاق إلى فئة عدم المواءمة بين الوكلاء في MAST وظاهرة «الترديد» (Zhang وآخرون، 2025).
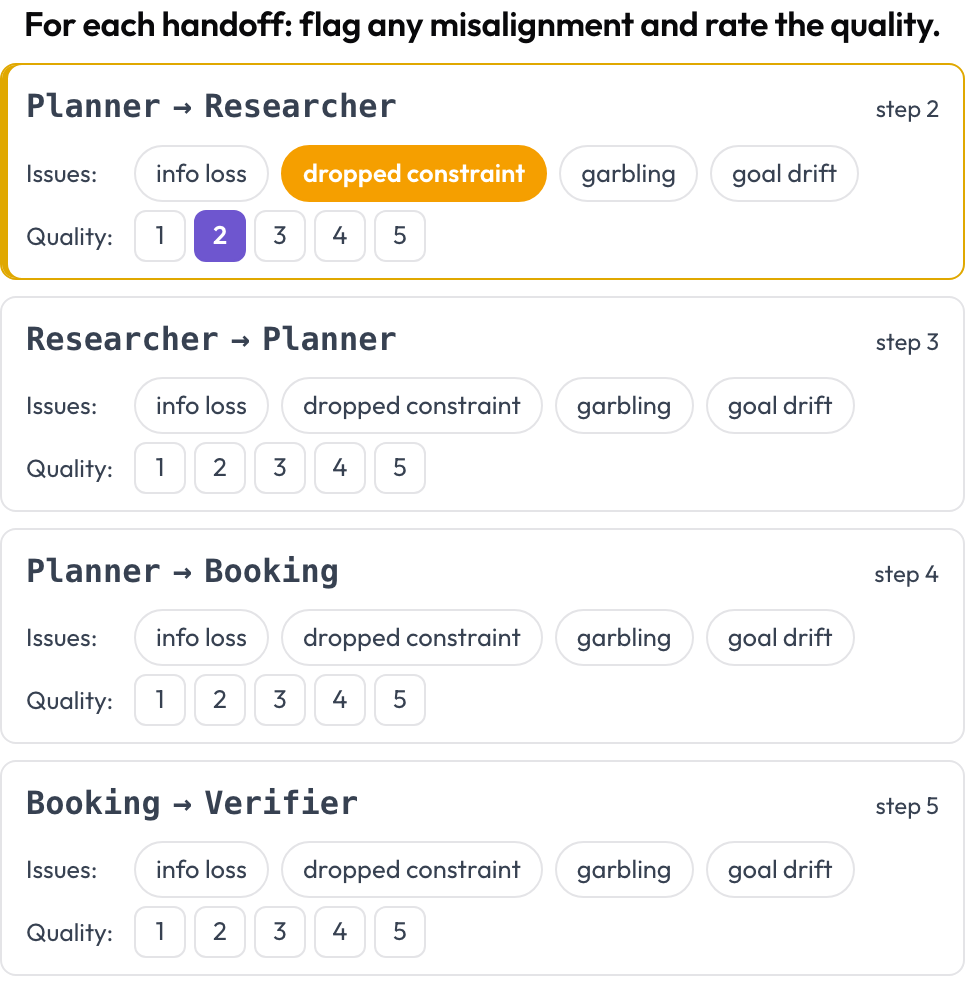 ضع علامة على عدم المواءمة بين الوكلاء في كل عملية تسليم وقيّم جودتها
ضع علامة على عدم المواءمة بين الوكلاء في كل عملية تسليم وقيّم جودتها
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5تُشتقّ عمليات التسليم من الأثر عند العرض، فلا حاجة إلى إعداد يدوي. وتُخزَّن قائمةً من {index, step, from, to, flags, quality}.
بطاقة تقييم لكل وكيل ولكل فريق (agent_scorecard)
سجّل درجة التشغيل على مستويين في آنٍ واحد (MultiAgentBench، Zhou وآخرون، ACL 2025): يحصل كل وكيل على درجات لكل بُعد (الوفاء بالدور، الإسهام، التنسيق)، ويحصل الفريق على درجات للأبعاد المشتركة، وتُؤشَّر مراحل اختيارية إنجازها. تأتي صفوف الوكلاء من أدوار الأثر نفسها، فتطابق المصفوفةُ مَن شارك فعلًا.
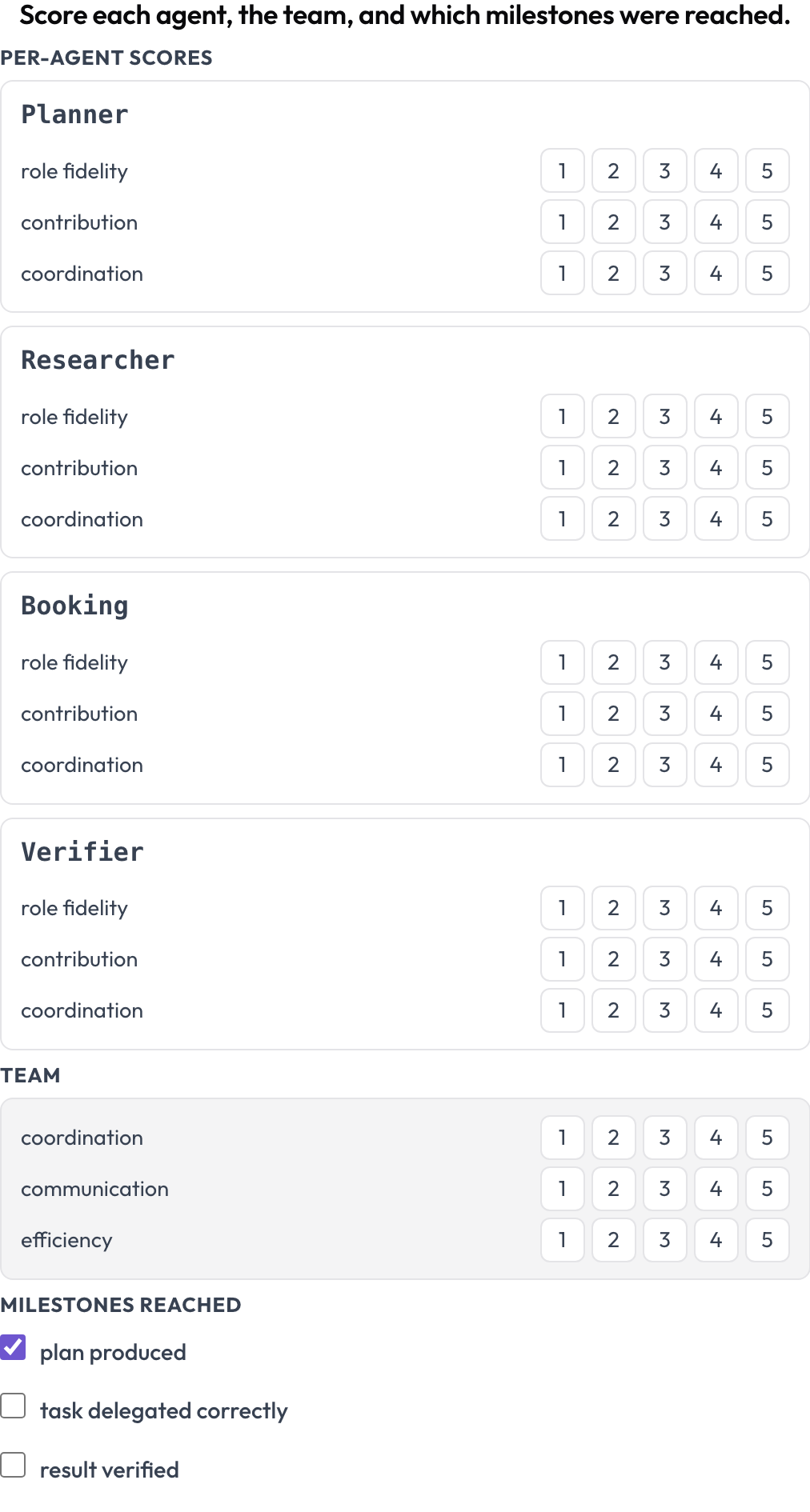 سجّل درجة كل وكيل في الوفاء بالدور والإسهام والتنسيق، إلى جانب الفريق والمراحل
سجّل درجة كل وكيل في الوفاء بالدور والإسهام والتنسيق، إلى جانب الفريق والمراحل
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optionalيُخزَّن على هيئة {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}.
الخط الزمني لتنازع الأدوات/الموارد (tool_contention)
يُعرض الاستخدام المتزامن للأدوات والموارد عبر الوكلاء على خط زمني متعدد المسارات، مسار لكل وكيل. وتُبرَز المناطق التي يلمس فيها استدعاءان المورد نفسه في أوقات متداخلة عبر المسارات وتُسرَد للتصنيف: deadlock، أو circular wait، أو race condition، أو حميدة (DPBench، 2026). هكذا تلتقط إخفاقات التزامن التي يخفيها النص المرتب حسب الأدوار.
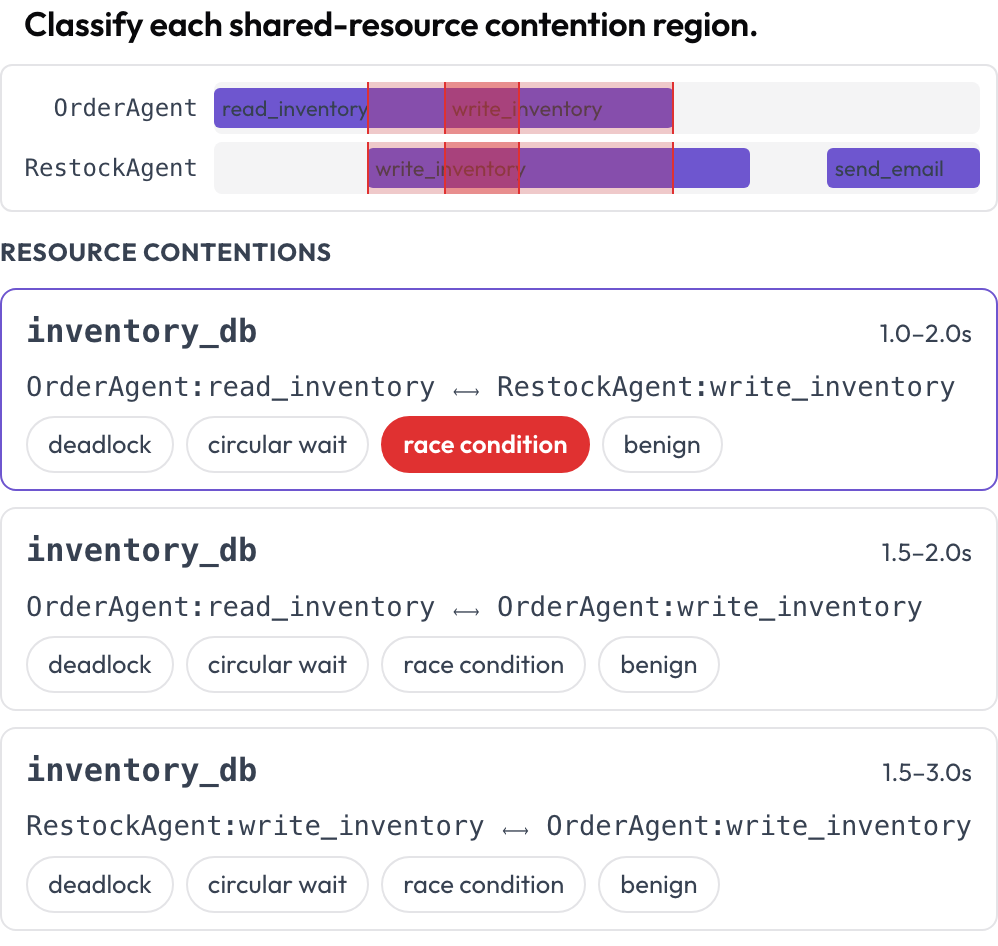 اكشِف حالات الـ deadlock وسباقات الوصول على خط زمني لاستدعاءات الأدوات لكل وكيل
اكشِف حالات الـ deadlock وسباقات الوصول على خط زمني لاستدعاءات الأدوات لكل وكيل
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]تُحسب مناطق التنازع عند العرض (resource نفسه، فترة متداخلة). وتُخزَّن على هيئة {"contentions": {idx: label}}.
السلوك الناشئ عبر المسارات (emergent_behavior)
بعض الإخفاقات جماعية: التواطؤ، والتفكير الجمعي، والأخطاء المتتالية، وانحراف الدور. والسلوك الناشئ ليس نطاقًا نصيًّا متصلًا؛ بل هو مجموعة من الأدوار المشاركة، قد تأتي من وكلاء مختلفين. ولكل سلوك يؤشّر المُعلّق الأدوار المشاركة ويضيف ملاحظة، أي نطاقًا عابرًا للمسارات يُعبَّر عنه بمجموعة أدوار.
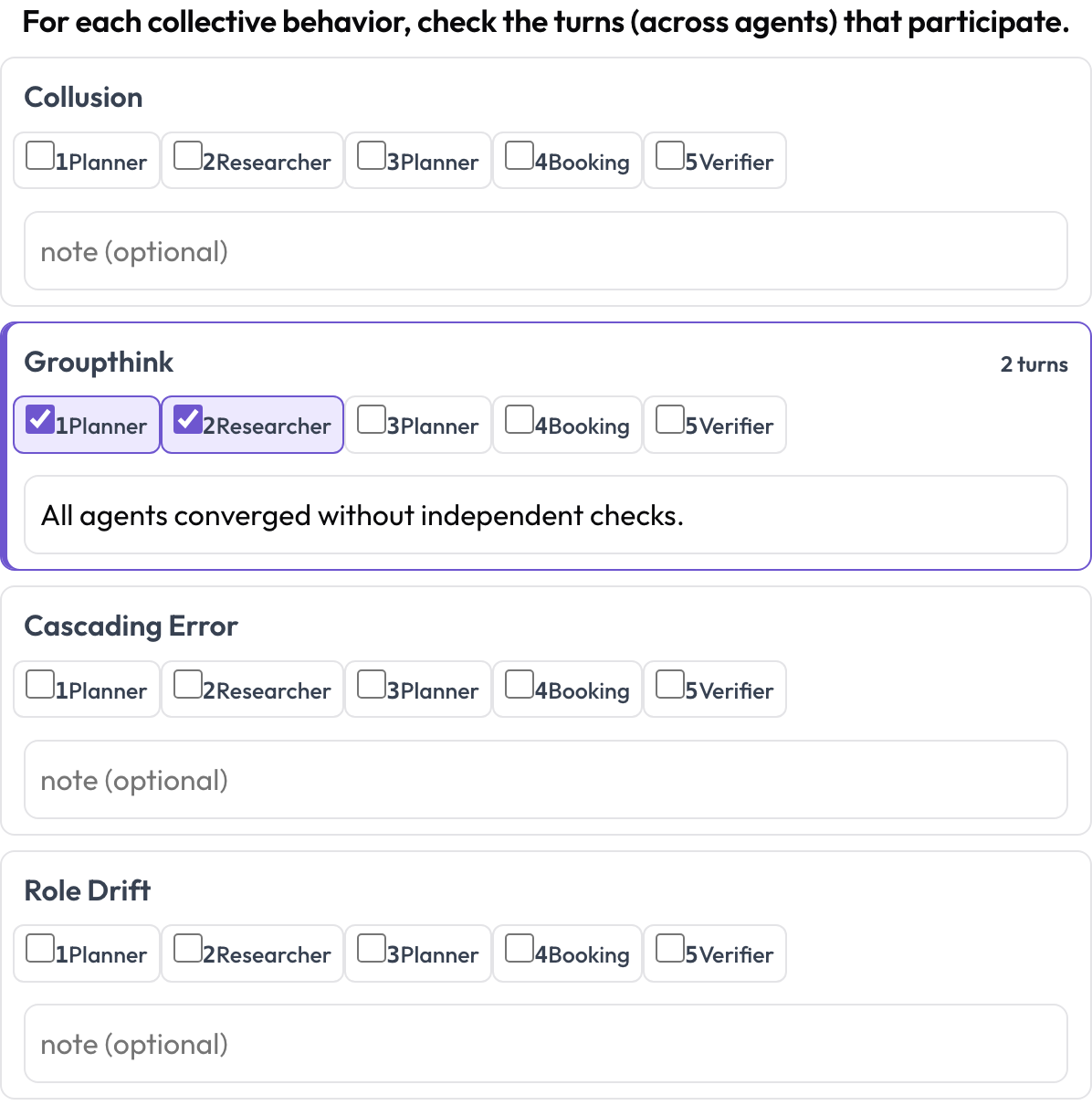 وسِم التواطؤ والتفكير الجمعي والأخطاء المتتالية عبر الوكلاء والأدوار
وسِم التواطؤ والتفكير الجمعي والأخطاء المتتالية عبر الوكلاء والأدوار
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueيُخزَّن على هيئة {behavior: {turns: [idx...], note}}، مع الإبقاء على السلوكيات غير الفارغة فقط.
مراجعة استدعاءات الأدوات (tool_call_review)
احكم على كل استدعاء أداة أو دالة على حِدة: هل اختير الأداة الصحيحة، وهل كانت الوسائط صحيحة، وهل كان الترتيب سليمًا (على غرار BFCL v4 / MCPMark)؟ تُستخرج استدعاءات الأدوات من خطوات الأثر عند العرض؛ ويصير tool_calls أو tool_call أو action في كل خطوة بطاقةً تحمل اسم الأداة ووسائطها المنسَّقة بوضوح.
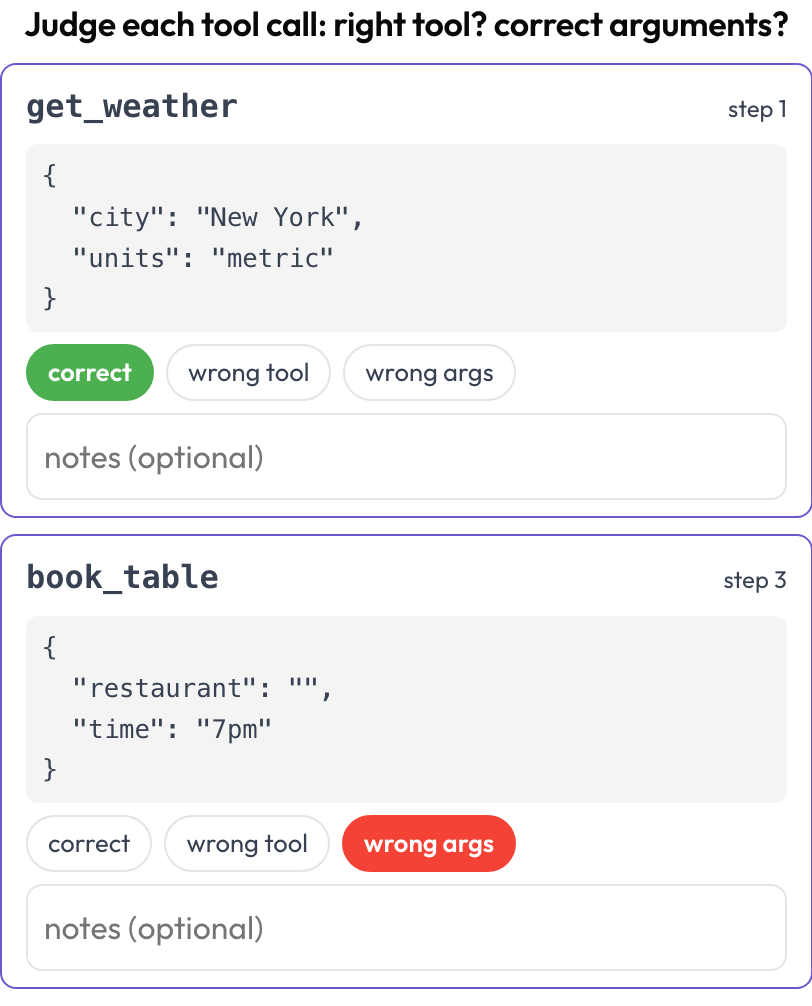 احكم على كل استدعاء أداة: الأداة الصحيحة، والوسائط الصحيحة، والترتيب الصحيح
احكم على كل استدعاء أداة: الأداة الصحيحة، والوسائط الصحيحة، والترتيب الصحيح
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizableيُخزَّن قائمةً من {index, step, tool, verdict, notes}.
وسم MAST بدقّة الخطوة
لا تحتاج إلى مخطط جديد لربط تصنيف الإخفاق MAST بأنماطه الأربعة عشر (Cemri وآخرون، Why Do Multi-Agent LLM Systems Fail?، 2025) بالخطوة المحددة (ومن ثَمّ بالوكيل الفاعل) التي وقع فيها الإخفاق. هيّئ مخطط trajectory_eval لكل خطوة القائمَ أصلًا بأنماط MAST بوصفها error_types، مجمَّعةً وفق فئات MAST الثلاث. اقرنه بـ failure_attribution وhandoff_review لتغطية كاملة.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]اختيار عدسة التنسيق
كثيرًا ما تهيمن بنية التنسيق على نتيجة التشغيل، فيستحق التقاطها بوصفها تصنيفًا من الدرجة الأولى. ولا حاجة إلى مخطط جديد: يؤكّد radio نمط التشغيل أو يصححه، فيوجّه ذلك بعدُ عدسةَ التقييم وطريقةَ ترتيب الأثر (تتابعي → مسارات، هرمي → شجرة، دردشة جماعية → لوحة).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueذات صلة
- تقييم الوكلاء متعدد الوسائط — مخططات وكلاء الـ GUI والصوت والفيديو والمستندات
- تعليق مسارات الوكلاء — تعليق الأخطاء لكل خطوة
- كيفية تقييم وكلاء الذكاء الاصطناعي — مستويات تقييم الوكلاء
- التعليق الوكيلي — تهيئة عرض الأثر واستيعابه
للاطلاع على تفاصيل التنفيذ، انظر التوثيق المصدري.