Rubric Evaluation
Build multi-criteria evaluation grids in Potato for LLM output assessment, essay grading, translation quality, and any structured rubric-based annotation task.
The rubric evaluation annotation schema provides a structured grid interface for scoring content across multiple criteria on a defined scale. Use it for LLM output evaluation, essay grading, translation quality assessment, or any task that needs structured multi-dimensional scoring.
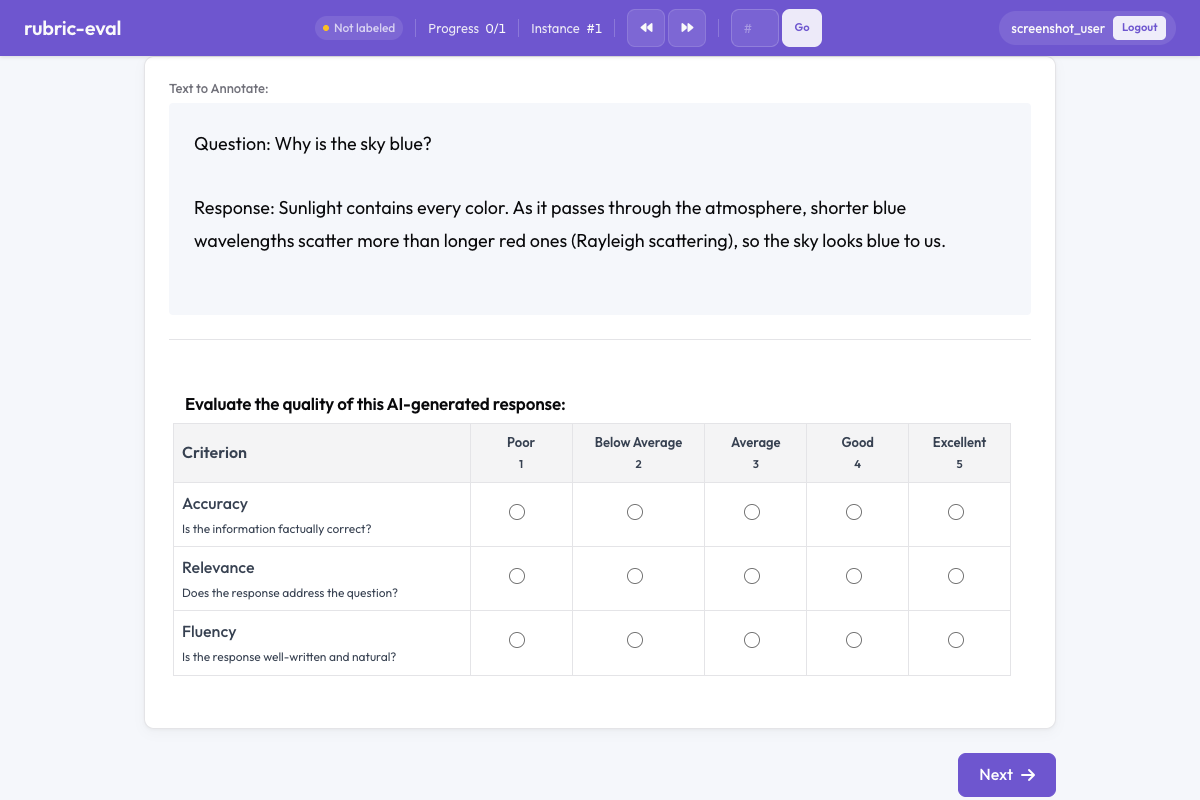 Rubric evaluation in Potato
Rubric evaluation in Potato
Overview
The rubric evaluation schema presents:
- A grid of criteria each with its own rating scale
- Scale labels ranging from Poor to Excellent (customizable)
- Optional overall score that summarizes across criteria
- Descriptions for each criterion to guide annotators
This is especially useful for structured human evaluation of generative AI outputs.
Quick Start
annotation_schemes:
- annotation_type: rubric_eval
name: response_quality
description: Evaluate the quality of this AI-generated response.
scale_points: 5
criteria:
- name: Accuracy
description: Is the information factually correct?
- name: Relevance
description: Does the response address the question?
- name: Fluency
description: Is the response well-written and natural?Configuration Options
| Field | Type | Default | Description |
|---|---|---|---|
annotation_type | string | Required | Must be "rubric_eval" |
name | string | Required | Unique identifier for this schema |
description | string | Required | Instructions displayed to annotators |
scale_points | integer | 5 | Number of points on the rating scale |
scale_labels | array | ["Poor", "Fair", "Average", "Good", "Excellent"] | Labels for each scale point (length must match scale_points) |
criteria | array | Required | List of criteria objects, each with name and optional description |
show_overall | boolean | false | Show an additional overall score row below the criteria |
Examples
LLM Output Evaluation
annotation_schemes:
- annotation_type: rubric_eval
name: llm_eval
description: Rate the quality of this model-generated response.
scale_points: 5
scale_labels:
- Poor
- Fair
- Average
- Good
- Excellent
show_overall: true
criteria:
- name: Helpfulness
description: Does the response provide useful and actionable information?
- name: Accuracy
description: Is the response factually correct and free of hallucinations?
- name: Harmlessness
description: Is the response free of harmful, biased, or inappropriate content?
- name: Coherence
description: Is the response logically structured and easy to follow?Essay Grading
annotation_schemes:
- annotation_type: rubric_eval
name: essay_grade
description: Grade this student essay using the rubric below.
scale_points: 4
scale_labels:
- Below Expectations
- Approaching
- Meets Expectations
- Exceeds Expectations
criteria:
- name: Thesis
description: Is there a clear and arguable thesis statement?
- name: Evidence
description: Does the essay use relevant evidence to support claims?
- name: Organization
description: Is the essay logically organized with clear transitions?
- name: Grammar
description: Is the writing free of grammatical and spelling errors?Translation Quality Assessment
annotation_schemes:
- annotation_type: rubric_eval
name: translation_quality
description: Evaluate the quality of this machine translation.
scale_points: 3
scale_labels:
- Unacceptable
- Acceptable
- Perfect
criteria:
- name: Adequacy
description: Does the translation convey the same meaning as the source?
- name: Fluency
description: Does the translation read naturally in the target language?
- name: Terminology
description: Are domain-specific terms translated correctly?Output Format
{
"response_quality": {
"labels": {
"Accuracy": 4,
"Relevance": 5,
"Fluency": 3
},
"overall": 4
}
}Each criterion maps to its selected scale value (1-indexed). The overall field is included only when show_overall is true.
Best Practices
- Keep criteria independent - each criterion should measure a distinct dimension to avoid redundant scoring
- Write clear descriptions - annotators should know exactly what each criterion measures without ambiguity
- Use 3-5 scale points - fewer points reduce cognitive load; more than 7 points rarely improves reliability
- Provide anchor examples - in the description, mention what constitutes each end of the scale
- Enable overall score for aggregation -
show_overallis useful when you need a single summary metric alongside detailed breakdowns
Further Reading
- Likert Scales - Single-dimension rating scales
- Pairwise Comparison - Side-by-side evaluation
- Quality Control - Attention checks and gold standards
For implementation details, see the source documentation.