Semantic Differential
Configure semantic differential scales in Potato for measuring attitudes using bipolar adjective pairs with configurable scale points.
The semantic differential annotation schema presents annotators with bipolar adjective scales for measuring attitudes, perceptions, or connotative meanings. Each scale has opposing adjectives at either end (e.g., "Good" vs. "Bad") and annotators select a point along the spectrum to indicate where the item falls.
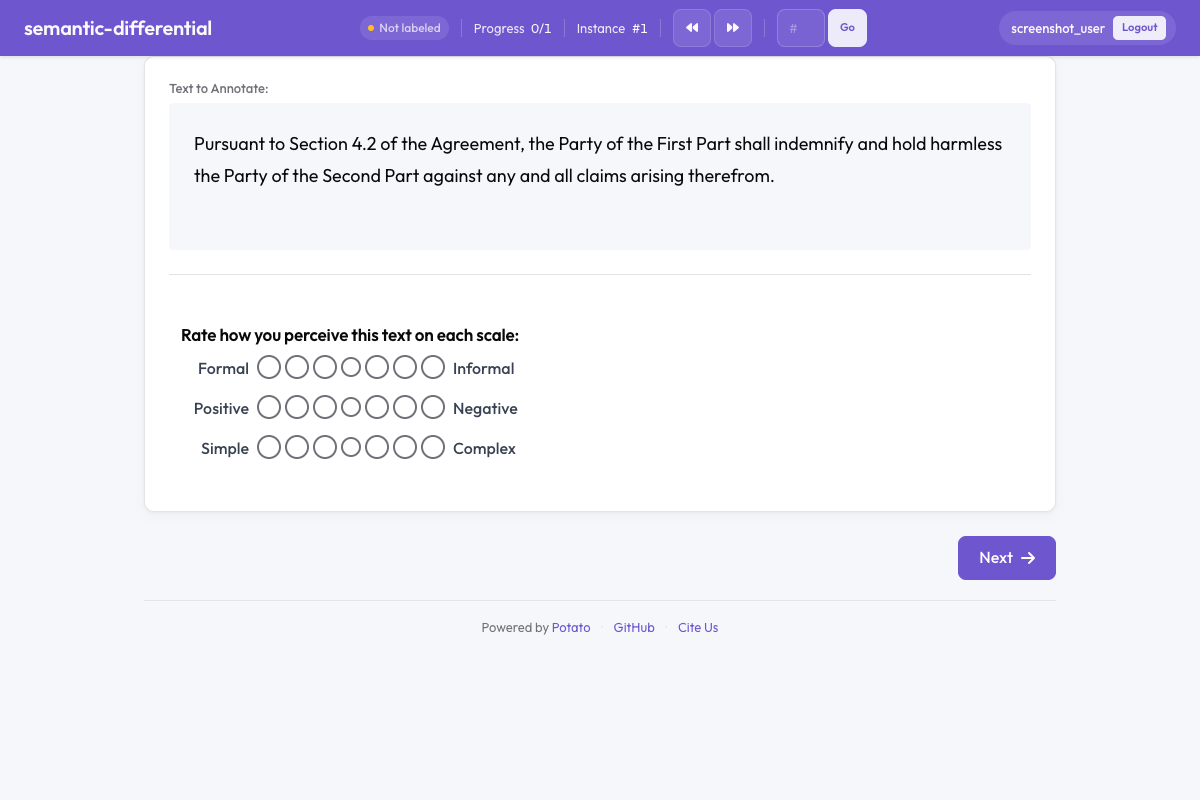 Semantic differential in Potato
Semantic differential in Potato
Overview
Developed by Charles Osgood in the 1950s, semantic differential scales are a well-established method in psychology and social science for measuring the connotative meaning of concepts. In annotation tasks, they are useful for capturing nuanced, multi-dimensional perceptions that cannot be expressed with a single rating scale.
Quick Start
annotation_schemes:
- annotation_type: semantic_differential
name: text_perception
description: Rate how you perceive this text on each scale.
pairs:
- ["Formal", "Informal"]
- ["Positive", "Negative"]
- ["Simple", "Complex"]
scale_points: 7Configuration Options
| Field | Type | Default | Description |
|---|---|---|---|
annotation_type | string | Required | Must be "semantic_differential" |
name | string | Required | Unique identifier for this schema |
description | string | Required | Instructions displayed to annotators |
pairs | array | Required | List of [left_adjective, right_adjective] pairs |
scale_points | integer | 7 | Number of points on each bipolar scale (typically 5 or 7) |
show_center_label | boolean | true | Display a "Neutral" label at the center of the scale |
label_requirement.required | boolean | false | Whether all scales must be rated before moving on |
Examples
Text Style Assessment
annotation_schemes:
- annotation_type: semantic_differential
name: writing_style
description: Rate the writing style of this text on each dimension.
pairs:
- ["Formal", "Informal"]
- ["Objective", "Subjective"]
- ["Concise", "Verbose"]
- ["Clear", "Ambiguous"]
scale_points: 7
show_center_label: trueSpeaker Perception
annotation_schemes:
- annotation_type: semantic_differential
name: speaker_impression
description: Rate your impression of the speaker on each dimension.
pairs:
- ["Competent", "Incompetent"]
- ["Warm", "Cold"]
- ["Trustworthy", "Untrustworthy"]
- ["Dominant", "Submissive"]
scale_points: 7
label_requirement:
required: trueProduct Evaluation
annotation_schemes:
- annotation_type: semantic_differential
name: product_perception
description: How do you perceive this product?
pairs:
- ["Innovative", "Traditional"]
- ["Affordable", "Expensive"]
- ["Reliable", "Unreliable"]
- ["Simple", "Complex"]
scale_points: 5
show_center_label: trueEmotion Dimensions (EPA)
The classic Evaluation-Potency-Activity framework:
annotation_schemes:
- annotation_type: semantic_differential
name: epa_rating
description: Rate this concept on each dimension.
pairs:
- ["Good", "Bad"]
- ["Powerful", "Weak"]
- ["Active", "Passive"]
scale_points: 7
show_center_label: true
label_requirement:
required: trueOutput Format
{
"text_perception": {
"labels": {
"Formal-Informal": 5,
"Positive-Negative": 2,
"Simple-Complex": 4
}
}
}Values range from 1 (left adjective) to scale_points (right adjective), with the midpoint representing neutral.
Best Practices
- Use 7-point scales by default - the standard in semantic differential research and provides sufficient granularity
- Balance polarity across pairs - mix which side has the "positive" adjective to prevent response sets
- Limit pairs to 5-8 per item - too many scales causes fatigue and reduces data quality
- Use established adjective pairs - reuse validated pairs from existing research when available
- Keep the center label - the neutral midpoint is an important reference for annotators
- Randomize pair order - if possible, vary the presentation order to reduce anchoring effects
Further Reading
- Likert Scales - Ordinal rating scales for agreement/frequency
- Slider - Continuous value annotation
- Pairwise Comparison - Comparing two items directly
For implementation details, see the source documentation.