Edição de trajetórias para SFT/DPO
Os anotadores reescrevem os passos de um rastro de agente para corrigir um passo de raciocínio errado, ajustar uma chamada de ferramenta ou reforçar a resposta final, e o Potato exporta cada par original/corrigido como alvos de ajuste fino supervisionado e pares de preferência DPO.
O esquema trajectory_edit permite que os anotadores reescrevam os passos de um rastro de agente e exporta cada correção como dados de treinamento. Corrija um passo de raciocínio errado, ajuste uma chamada de ferramenta com um erro de digitação ou reforce a resposta final, e o Potato salva a trajetória corrigida ao lado da original. Em seguida, o exportador trajectory_correction transforma cada par (original, corrected) em alvos de ajuste fino supervisionado (SFT) e pares de preferência de otimização direta de preferências (DPO).
Isso torna o Potato uma ferramenta de produção de dados de treinamento, e não apenas de avaliação. É a contraparte de edição da pontuação em nível de passo: em vez de classificar uma trajetória, os anotadores a reparam, e o reparo se torna um sinal de aprendizado.
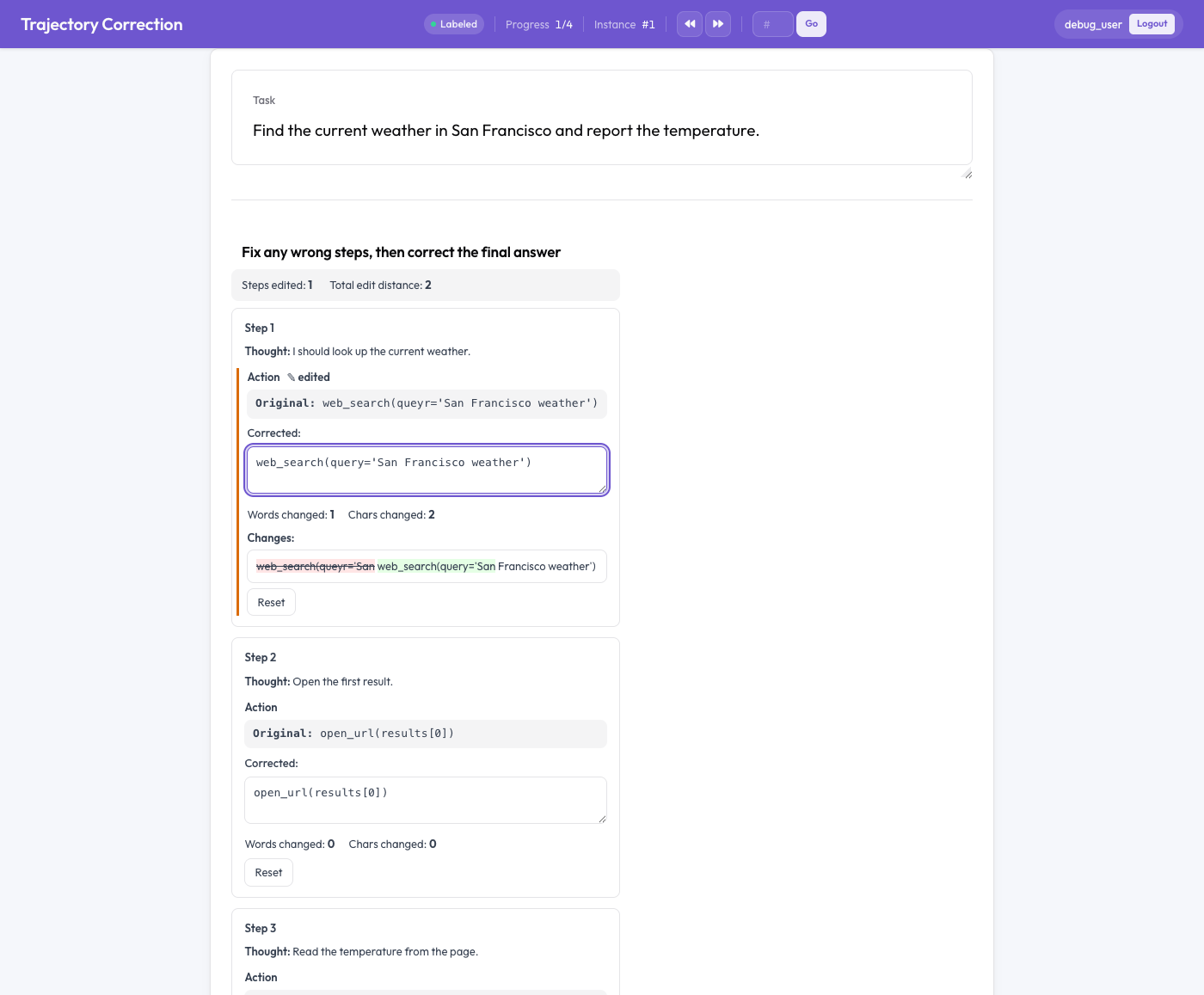 Um passo de agente exibido com um original somente leitura e uma caixa corrigida editável com um diff em nível de palavra
Um passo de agente exibido com um original somente leitura e uma caixa corrigida editável com um diff em nível de palavra
Início rápido
Execute o exemplo incluído a partir da raiz do repositório:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000Como funciona
Cada passo de agente é renderizado como um cartão que exibe o texto original (somente leitura) e uma caixa corrigida editável pré-preenchida com o original. À medida que o anotador digita:
- um diff ao vivo em nível de palavra destaca as inserções (em verde) e as exclusões (riscado em vermelho),
- as palavras e os caracteres alterados são contados, e
- uma marca de «editado» aparece nos campos alterados.
Um botão «Redefinir» restaura o original por campo. Com edit_final_answer: true, a resposta final ganha seu próprio editor. Nada é obrigatório: um rastro não editado simplesmente não produz nenhum par de treinamento.
Configuração
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer| Opção | Padrão | Descrição |
|---|---|---|
steps_key | steps | Campo da instância que contém a lista de passos. |
step_text_key | action | Campo editável padrão por passo. |
editable_fields | [step_text_key] | Quais campos do passo recebem um editor, p. ex. [action, thought]. |
show_diff | true | Exibe o diff ao vivo em nível de palavra. |
show_edit_distance | true | Exibe as palavras e os caracteres alterados. |
allow_reset | true | Botão «Redefinir para o original» por campo. |
require_reason_on_edit | false | Campo de entrada «motivo da edição» por campo. |
edit_final_answer | false | Adiciona um editor para a resposta final. |
final_answer_key | final_answer | Campo da instância que contém a resposta final. |
Formato dos dados
O esquema lê os passos da instância sob steps_key. Cada passo é um objeto cujos campos (action, thought e assim por diante) podem ser editados; passos de string simples são editados como o campo step_text_key.
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}Exportação
Execute o exportador trajectory_correction. Ele grava três arquivos:
trajectory_corrections.json— cada registro: ooriginal_trace, ocorrected_tracereconstruído e, por campo, aseditscom distâncias de edição e motivos.trajectory_sft.jsonl— uma linha por rastro editado:{"prompt": <task>, "completion": <corrected_trace>}.trajectory_dpo.jsonl— uma linha por rastro editado:{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}.
Os rastros não editados são contados, mas excluídos do SFT/DPO, pois treinar em uma trajetória inalterada não acrescenta nada; a contagem dos ignorados aparece nas estatísticas de exportação. Com vários anotadores, cada anotador que editou um rastro gera um registro SFT/DPO.
Notas e limitações
- O diff é em nível de palavra. Para chamadas de ferramentas semelhantes a código e sem espaços, um único token pode aparecer como totalmente alterado mesmo em uma correção de um único caractere; o contador de distância de caracteres é o sinal preciso.
- Combine-o com a pontuação em nível de passo se você também quiser correção por passo ou uma taxonomia de erros sobre o mesmo rastro.
Relacionados
- Avaliação de rastro em três painéis — visualização somente leitura de raciocínio, chamadas e resposta
- Anotação agêntica — padrões de exibição e avaliação de rastros de agente
- Formatos de exportação — a referência completa do exportador
Para detalhes de implementação, consulte a documentação fonte.