Avaliação de equipes multiagentes
Anote sistemas multiagentes pela estrutura da equipe, e não por uma transcrição plana. O Potato adiciona um grafo de interação de agentes clicável, atribuição de falhas entre agentes, revisão de transferências, scorecards por agente e por equipe, uma linha do tempo de contenção de ferramentas e marcação de comportamento emergente.
Um sistema multiagente falha de forma diferente de um único agente: a quebra acontece entre agentes, em uma transferência ou na forma como a equipe foi organizada. Avaliá-lo significa atribuir resultados a qual agente, qual passo e qual transferência, não apenas pontuar uma transcrição plana. O Potato adiciona um conjunto de telas de anotação feitas para isso: um grafo de interação clicável, atribuição de falhas, revisão de transferências, scorecards por agente e por equipe, uma linha do tempo de contenção de ferramentas e marcação de comportamento emergente entre faixas.
Essas telas se apoiam na tela de trace do agente e na taxonomia de falhas MAST. Cada esquema deriva seus agentes, passos e transferências do próprio trace no momento da renderização, então o anotador escolhe entre o que de fato aconteceu na execução.
Grafo de interação (agent_interaction_graph)
A execução inteira é renderizada como um grafo dirigido: os nós são agentes, as arestas são as transições de mensagem e de transferência entre eles (arestas mais grossas significam maior frequência), dispostos automaticamente a partir do trace. O anotador clica em um nó para marcar o caminho crítico e clica em uma aresta para alterná-la entre normal → crítica → problemática. Esta é a resposta mais clara para "como eu vejo a estrutura de uma execução multiagente", e é uma tela que as ferramentas de anotação gerais não oferecem.
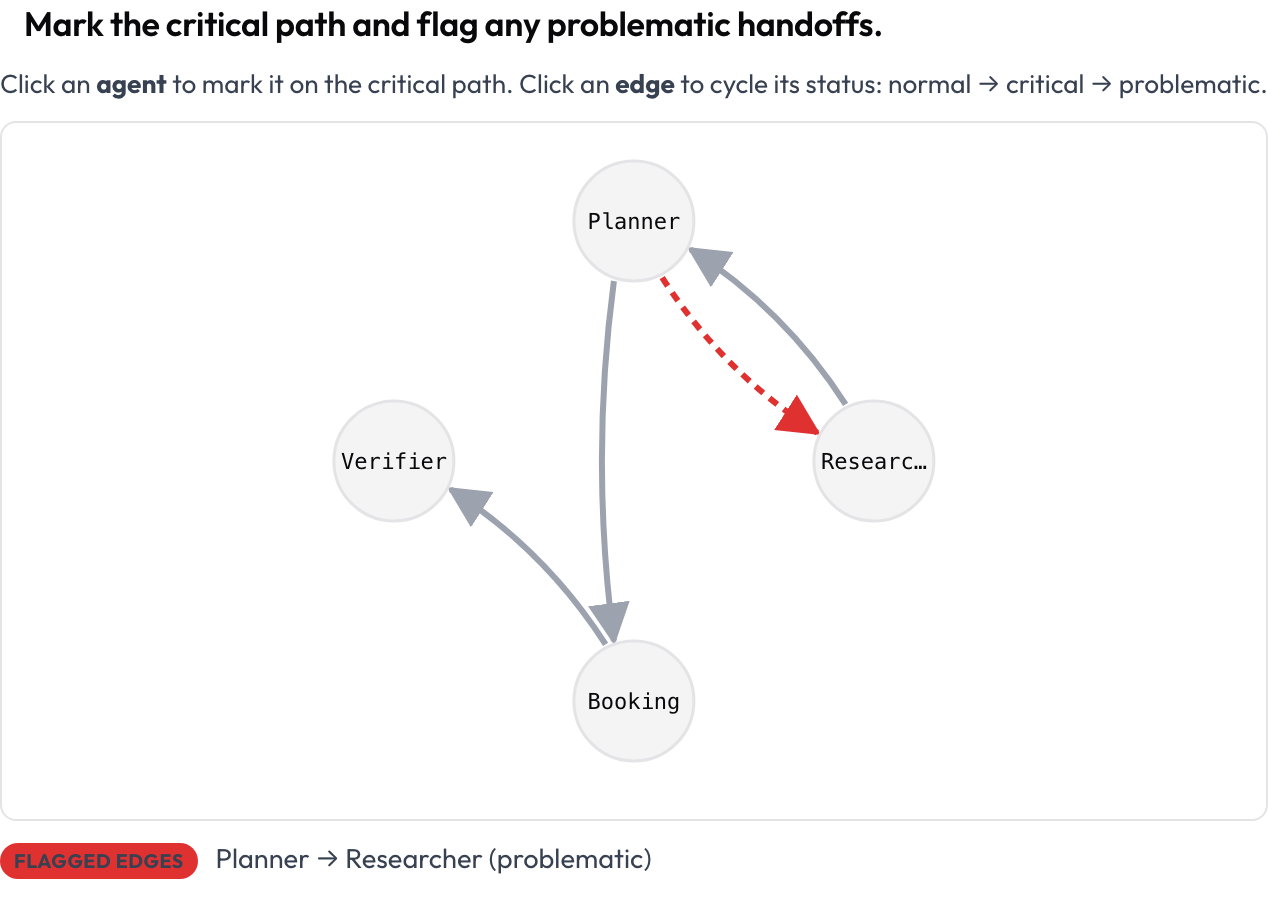 Marque o caminho crítico e sinalize transferências problemáticas em um grafo de interação de agentes clicável
Marque o caminho crítico e sinalize transferências problemáticas em um grafo de interação de agentes clicável
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentArmazenado como {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}. Todo nó e aresta é focalizável pelo teclado e um resumo de texto ao vivo lista os nós críticos e as arestas sinalizadas, então o significado nunca é transmitido apenas pela cor.
Atribuição de falhas entre agentes (failure_attribution)
Quando uma equipe falha, o rótulo útil é a tripla (agente responsável, passo decisivo, motivo) da literatura de atribuição de falhas (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, o conjunto de dados Who&When). O menu suspenso de agentes e o seletor de passos são preenchidos a partir dos próprios turnos do trace, então o anotador atribui a falha a um agente real e a um passo real.
 Atribua uma falha multiagente ao agente responsável, ao passo decisivo e ao porquê
Atribua uma falha multiagente ao agente responsável, ao passo decisivo e ao porquê
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the traceArmazenado como {"responsible_agent", "decisive_step", "reason"}. Combine-o com um esquema de resultado radio (sucesso/falha) para que a atribuição só seja acionada em execuções que falharam.
Revisão de transferências (handoff_review)
Cada transferência, um agente passando o controle a outro, torna-se um objeto de primeira classe para anotar. Sempre que o agente ativo muda entre turnos consecutivos, o Potato emite um cartão de transferência A → B; o anotador sinaliza o desalinhamento entre agentes e avalia a qualidade da transferência. Os modos de falha são fundamentados na categoria de desalinhamento entre agentes do MAST e no fenômeno de "echoing" (Zhang et al., 2025).
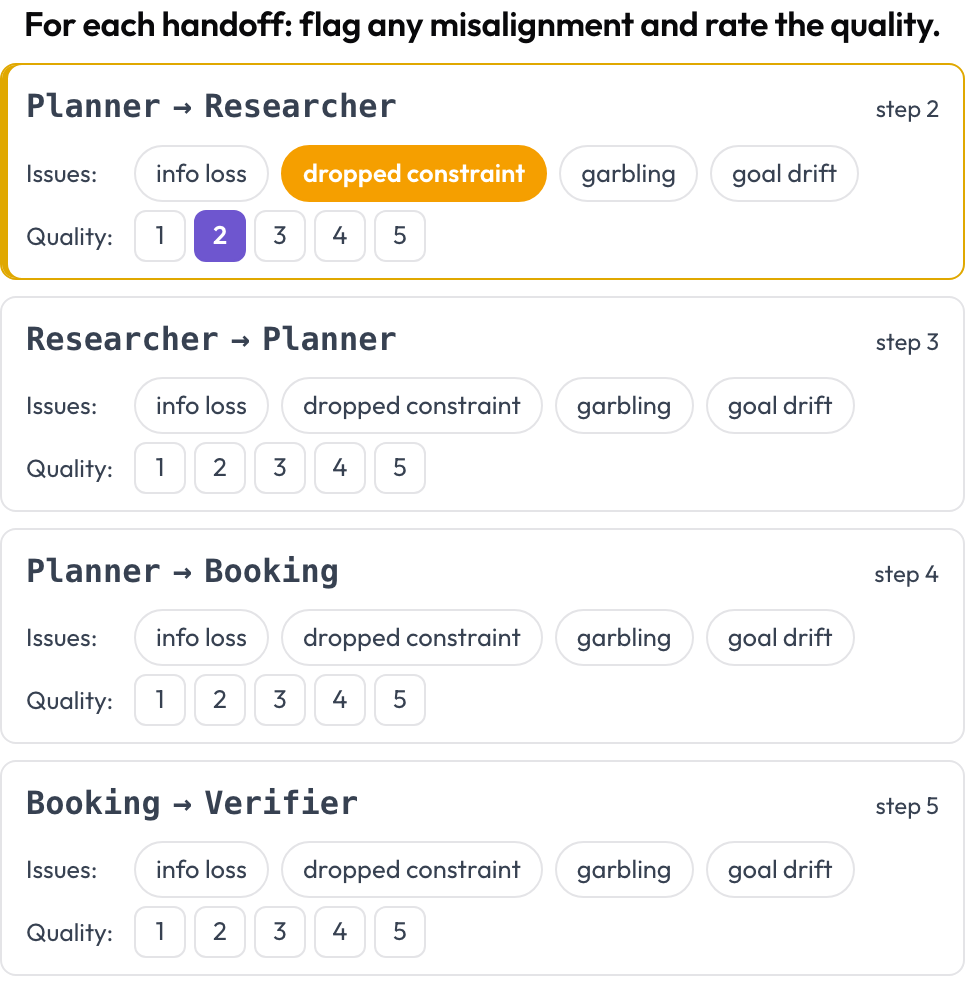 Sinalize o desalinhamento entre agentes em cada transferência e avalie sua qualidade
Sinalize o desalinhamento entre agentes em cada transferência e avalie sua qualidade
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5As transferências são derivadas do trace no momento da renderização, então não há configuração manual. Armazenado como uma lista de {index, step, from, to, flags, quality}.
Scorecard por agente e por equipe (agent_scorecard)
Pontue uma execução em dois níveis ao mesmo tempo (MultiAgentBench, Zhou et al., ACL 2025): cada agente recebe pontuações por dimensão (fidelidade ao papel, contribuição, coordenação), a equipe recebe pontuações nas dimensões compartilhadas e marcos opcionais são marcados. As linhas de agentes vêm dos próprios turnos do trace, então a matriz corresponde a quem de fato participou.
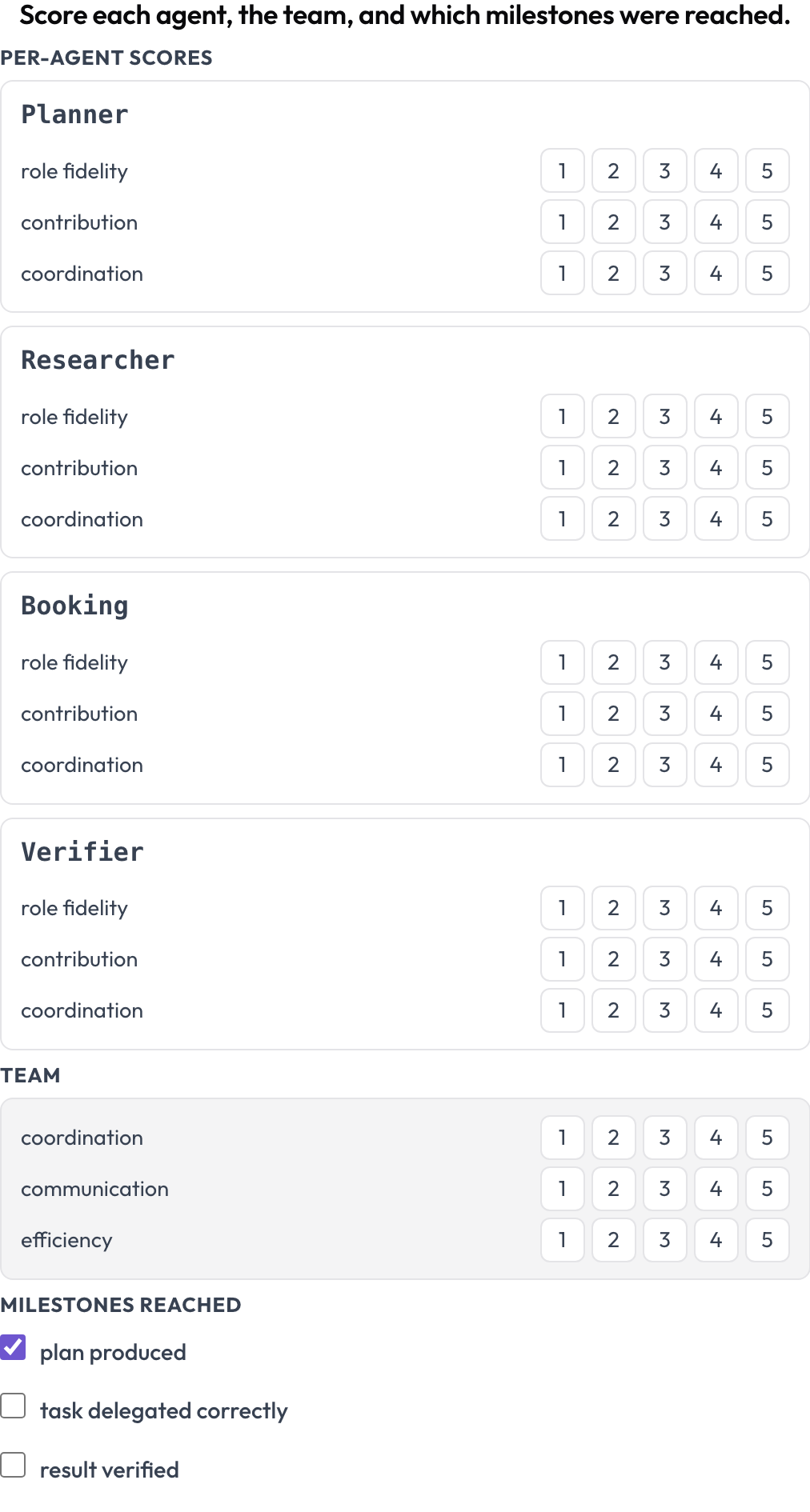 Pontue cada agente em fidelidade ao papel, contribuição e coordenação, além da equipe e dos marcos
Pontue cada agente em fidelidade ao papel, contribuição e coordenação, além da equipe e dos marcos
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optionalArmazenado como {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}.
Linha do tempo de contenção de ferramentas / recursos (tool_contention)
O uso concorrente de ferramentas e recursos entre agentes é renderizado em uma linha do tempo de múltiplas faixas, uma faixa por agente. As regiões em que duas chamadas tocam o mesmo recurso em tempos sobrepostos são destacadas entre as faixas e listadas para classificação: deadlock, espera circular, condição de corrida ou benigno (DPBench, 2026). É assim que você captura falhas de concorrência que uma transcrição por turno esconde.
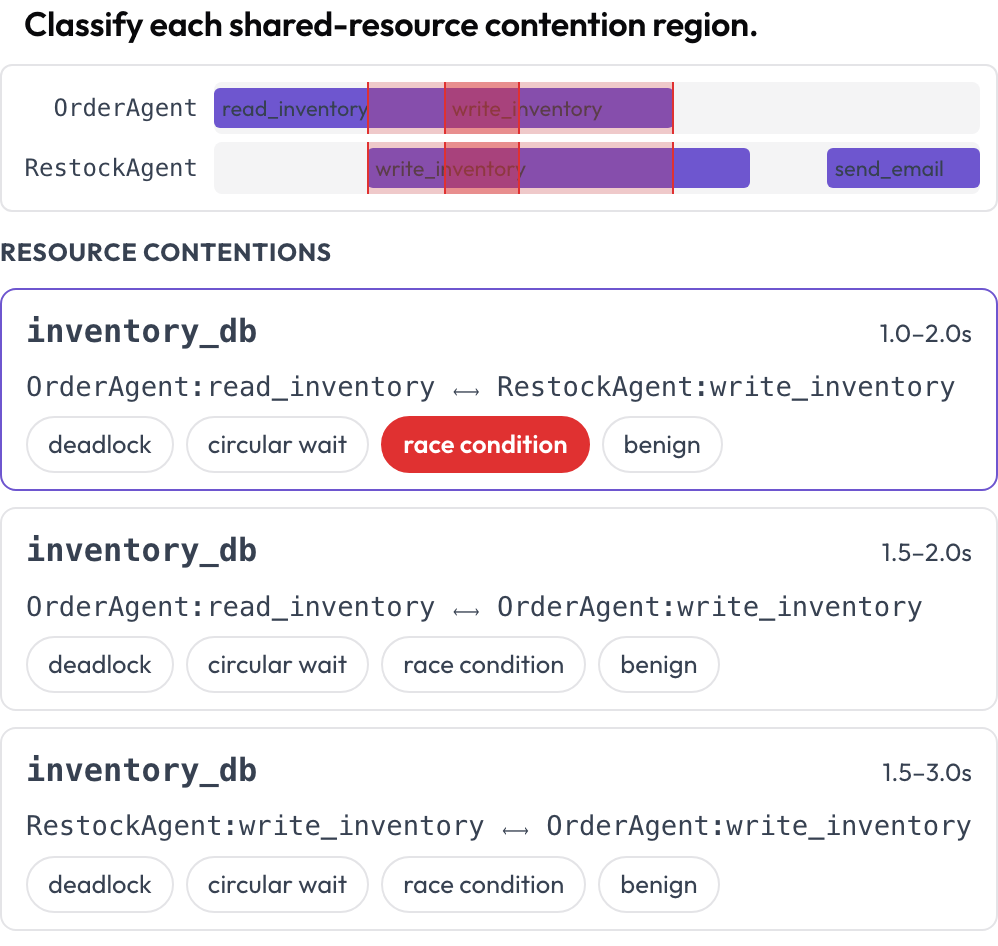 Identifique deadlocks e condições de corrida em uma linha do tempo de chamadas de ferramentas por agente
Identifique deadlocks e condições de corrida em uma linha do tempo de chamadas de ferramentas por agente
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]As regiões de contenção são calculadas no momento da renderização (mesmo resource, intervalo sobreposto). Armazenado como {"contentions": {idx: label}}.
Comportamento emergente entre faixas (emergent_behavior)
Algumas falhas são coletivas: conluio, pensamento de grupo, erros em cascata, desvio de papel. Um comportamento emergente não é um span de texto contíguo; é um conjunto de turnos participantes, possivelmente de agentes diferentes. Para cada comportamento, o anotador marca os turnos que participam e adiciona uma nota, um span entre faixas expresso como um conjunto de turnos.
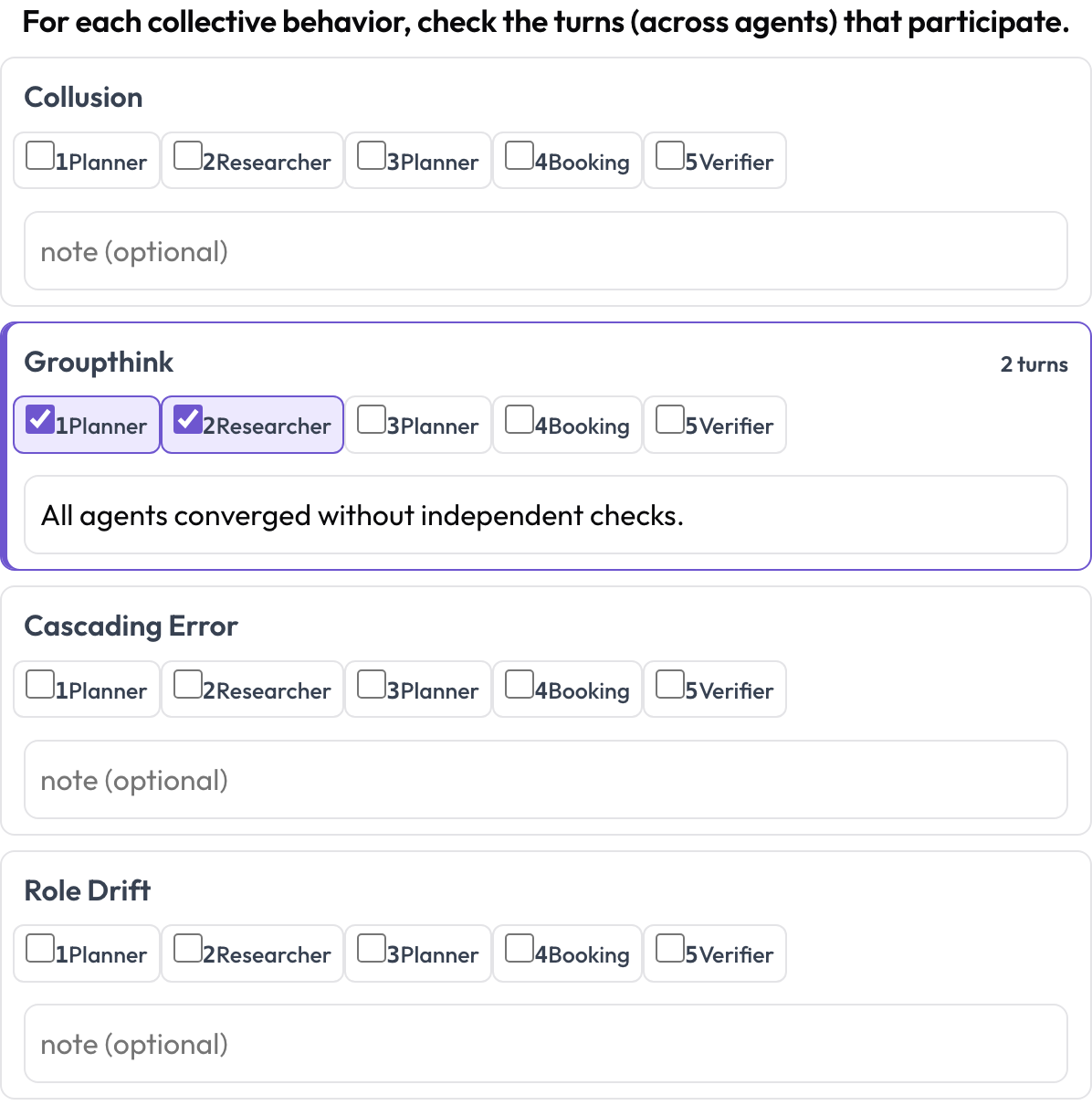 Marque conluio, pensamento de grupo e erros em cascata entre agentes e turnos
Marque conluio, pensamento de grupo e erros em cascata entre agentes e turnos
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueArmazenado como {behavior: {turns: [idx...], note}}, mantendo apenas os comportamentos não vazios.
Revisão de chamadas de ferramentas (tool_call_review)
Julgue cada chamada de ferramenta ou função individualmente: a ferramenta certa foi escolhida, os argumentos estavam corretos, a ordem estava certa (espelhando o BFCL v4 / MCPMark)? As chamadas de ferramentas são extraídas dos passos do trace no momento da renderização; o tool_calls, tool_call ou action de cada passo se torna um cartão com o nome da ferramenta e os argumentos formatados.
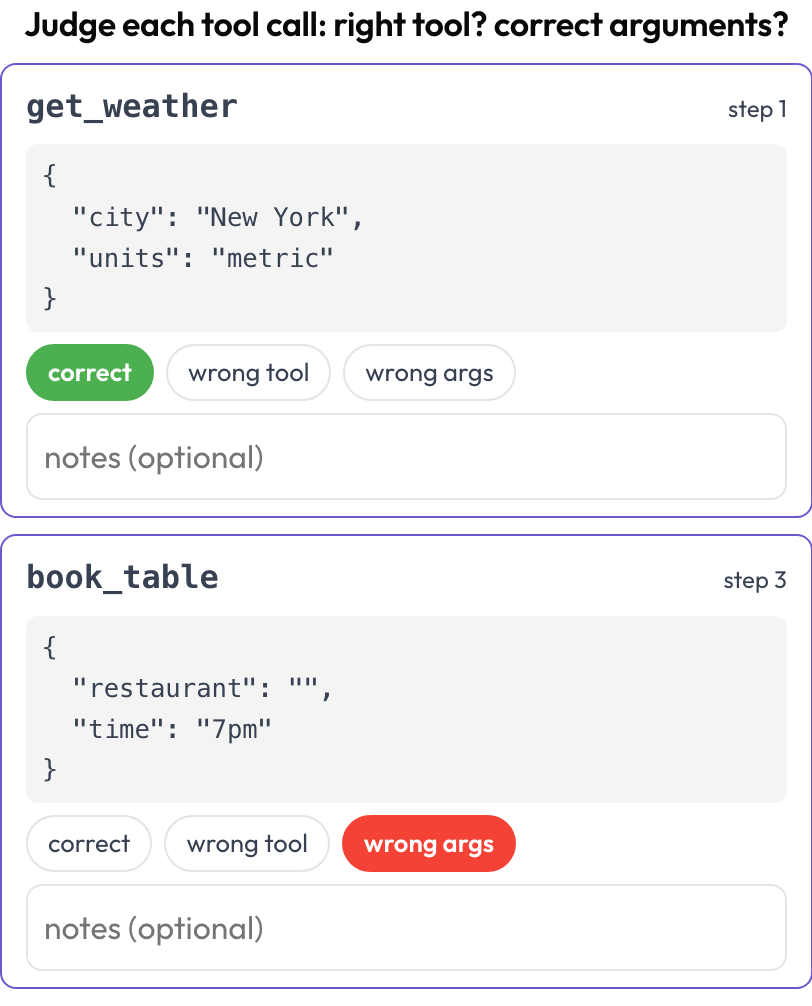 Julgue cada chamada de ferramenta: ferramenta certa, argumentos corretos, ordem certa
Julgue cada chamada de ferramenta: ferramenta certa, argumentos corretos, ordem certa
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizableArmazenado como uma lista de {index, step, tool, verdict, notes}.
Marcação MAST com granularidade de passo
Você não precisa de um novo esquema para vincular a taxonomia de falhas MAST de 14 modos (Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025) ao passo exato (e, portanto, ao agente ativo) em que uma falha ocorreu. Configure o esquema trajectory_eval por passo já existente com os modos MAST como seus error_types, agrupados pelas três categorias MAST. Combine-o com failure_attribution e handoff_review para uma cobertura completa.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]Escolhendo a lente de orquestração
A arquitetura de orquestração muitas vezes domina o resultado de uma execução, então vale capturá-la como um rótulo de primeira classe. Nenhum esquema novo é necessário: um radio confirma ou corrige o padrão da execução, que então guia tanto a lente de avaliação quanto a forma como o trace é disposto (sequencial → faixas, hierárquico → árvore, group-chat → quadro).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueRelacionado
- Avaliação multimodal de agentes — esquemas de GUI, voz, vídeo e agentes de documentos
- Anotar trajetórias de agentes — anotação de erros por passo
- Como avaliar agentes de IA — os níveis de avaliação de agentes
- Anotação agêntica — configuração e ingestão da tela de trace
Para detalhes de implementação, consulte a documentação de origem.