Avaliação por Rubrica
Crie grades de avaliação por múltiplos critérios no Potato para avaliar saídas de LLM, corrigir redações, medir qualidade de tradução e qualquer tarefa de anotação estruturada baseada em rubrica.
O esquema de anotação de avaliação por rubrica oferece uma interface de grade estruturada para pontuar conteúdo segundo múltiplos critérios em uma escala definida. Esse esquema é ideal para avaliação de saídas de LLM, correção de redações, avaliação de qualidade de tradução e qualquer tarefa que exija pontuação sistemática em múltiplas dimensões.
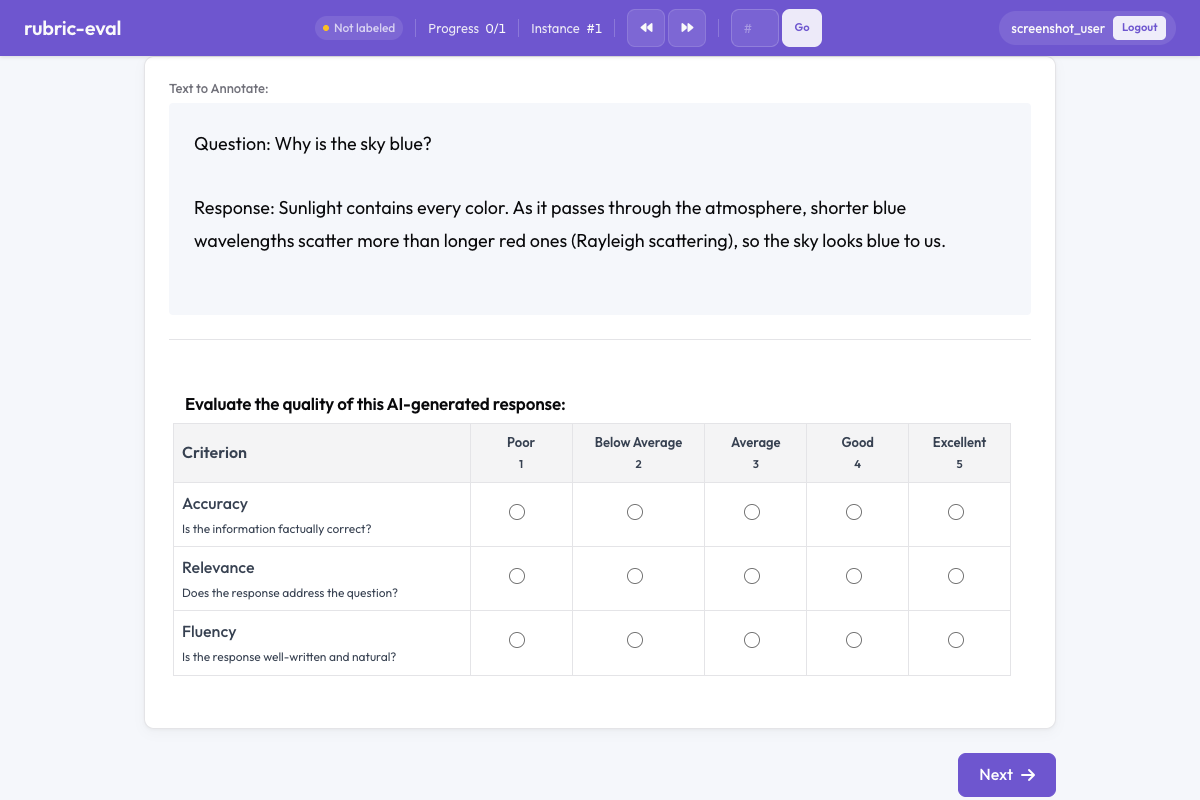 Avaliação por rubrica no Potato
Avaliação por rubrica no Potato
Visão Geral
O esquema de avaliação por rubrica apresenta:
- Uma grade de critérios, cada um com sua própria escala de avaliação
- Rótulos de escala que vão de Ruim a Excelente (personalizáveis)
- Pontuação geral opcional que resume os critérios
- Descrições para cada critério, a fim de orientar os anotadores
Isso é especialmente útil para avaliação humana estruturada de saídas de IA generativa.
Início Rápido
annotation_schemes:
- annotation_type: rubric_eval
name: response_quality
description: Evaluate the quality of this AI-generated response.
scale_points: 5
criteria:
- name: Accuracy
description: Is the information factually correct?
- name: Relevance
description: Does the response address the question?
- name: Fluency
description: Is the response well-written and natural?Opções de Configuração
| Campo | Tipo | Padrão | Descrição |
|---|---|---|---|
annotation_type | string | Obrigatório | Deve ser "rubric_eval" |
name | string | Obrigatório | Identificador único para este esquema |
description | string | Obrigatório | Instruções exibidas aos anotadores |
scale_points | integer | 5 | Número de pontos na escala de avaliação |
scale_labels | array | ["Poor", "Fair", "Average", "Good", "Excellent"] | Rótulos para cada ponto da escala (o tamanho deve corresponder a scale_points) |
criteria | array | Obrigatório | Lista de objetos de critério, cada um com name e description opcional |
show_overall | boolean | false | Exibe uma linha adicional de pontuação geral abaixo dos critérios |
Exemplos
Avaliação de Saída de LLM
annotation_schemes:
- annotation_type: rubric_eval
name: llm_eval
description: Rate the quality of this model-generated response.
scale_points: 5
scale_labels:
- Poor
- Fair
- Average
- Good
- Excellent
show_overall: true
criteria:
- name: Helpfulness
description: Does the response provide useful and actionable information?
- name: Accuracy
description: Is the response factually correct and free of hallucinations?
- name: Harmlessness
description: Is the response free of harmful, biased, or inappropriate content?
- name: Coherence
description: Is the response logically structured and easy to follow?Correção de Redação
annotation_schemes:
- annotation_type: rubric_eval
name: essay_grade
description: Grade this student essay using the rubric below.
scale_points: 4
scale_labels:
- Below Expectations
- Approaching
- Meets Expectations
- Exceeds Expectations
criteria:
- name: Thesis
description: Is there a clear and arguable thesis statement?
- name: Evidence
description: Does the essay use relevant evidence to support claims?
- name: Organization
description: Is the essay logically organized with clear transitions?
- name: Grammar
description: Is the writing free of grammatical and spelling errors?Avaliação de Qualidade de Tradução
annotation_schemes:
- annotation_type: rubric_eval
name: translation_quality
description: Evaluate the quality of this machine translation.
scale_points: 3
scale_labels:
- Unacceptable
- Acceptable
- Perfect
criteria:
- name: Adequacy
description: Does the translation convey the same meaning as the source?
- name: Fluency
description: Does the translation read naturally in the target language?
- name: Terminology
description: Are domain-specific terms translated correctly?Formato de Saída
{
"response_quality": {
"labels": {
"Accuracy": 4,
"Relevance": 5,
"Fluency": 3
},
"overall": 4
}
}Cada critério é mapeado para o valor de escala selecionado (indexado a partir de 1). O campo overall é incluído somente quando show_overall é true.
Boas Práticas
- Mantenha os critérios independentes - cada critério deve medir uma dimensão distinta para evitar pontuação redundante
- Escreva descrições claras - os anotadores devem saber exatamente o que cada critério mede, sem ambiguidade
- Use de 3 a 5 pontos de escala - menos pontos reduzem a carga cognitiva; mais de 7 pontos raramente melhoram a confiabilidade
- Forneça exemplos de referência - na descrição, mencione o que caracteriza cada extremidade da escala
- Ative a pontuação geral para agregação -
show_overallé útil quando você precisa de uma única métrica de resumo ao lado de detalhamentos detalhados
Leitura Complementar
- Escalas Likert - Escalas de avaliação de dimensão única
- Comparação Pareada - Avaliação lado a lado
- Controle de Qualidade - Verificações de atenção e padrões-ouro
Para detalhes de implementação, consulte a documentação de origem.