Alinhamento juiz ↔ humano
Meça o quão bem um juiz LLM concorda com seus rótulos de ouro humanos. O Potato executa o juiz sobre as instâncias anotadas, calcula o kappa de Cohen, uma matriz de confusão e uma lista de discordâncias, e acompanha a concordância à medida que você refina a rubrica.
O alinhamento do juiz mede e ajusta o quão bem um juiz LLM concorda com seus rótulos de ouro humanos. O Potato executa um LLM-as-a-judge configurável sobre as instâncias que seus anotadores já rotularam, calcula o κ de Cohen, uma matriz de confusão e uma lista de discordâncias, e acompanha κ à medida que você edita a rubrica do juiz. Com o modo embutido ativado, o veredito do juiz aparece ao lado do rótulo humano durante a anotação, com um κ em tempo real.
Esse é o ciclo padrão de «alinhe seu juiz a cerca de 100–200 rótulos de ouro» usado por ferramentas como LangSmith Align Evals e Evidently: colete rótulos humanos, execute o juiz, inspecione as discordâncias, refine a rubrica e execute novamente até que a concordância seja alta.
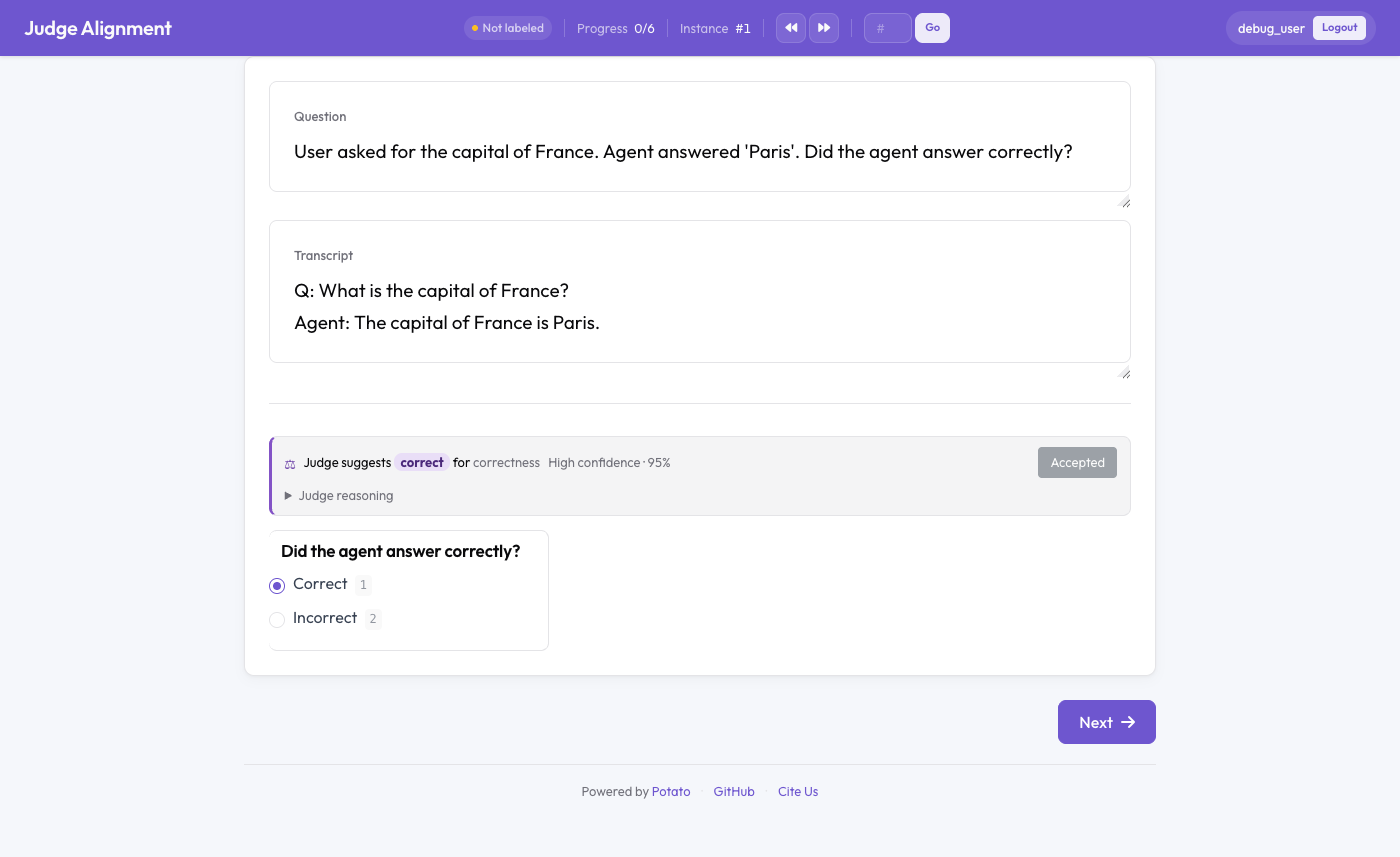 Veredito de um juiz LLM exibido ao lado da anotação humana com um kappa em tempo real
Veredito de um juiz LLM exibido ao lado da anotação humana com um kappa em tempo real
Configuração
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict existsO escopo abrange os esquemas categóricos de escolha única (radio, select, likert). Se judge_alignment.schemas estiver definido, apenas esses esquemas são julgados; caso contrário, todos os esquemas categóricos.
Executar o juiz
Execute o juiz a partir da API de administração. As previsões são armazenadas em cache por versão de prompt, então reexecuções são baratas:
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Para calibrar, passe uma rubrica editada. Isso cria uma nova versão do prompt, permitindo comparar κ entre as rodadas:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'O relatório de alinhamento
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
Envie o cabeçalho X-API-Key. Por esquema, o relatório mostra:
- O κ de Cohen com uma interpretação de Landis–Koch, a taxa de concordância e o número de instâncias comparadas.
- Uma matriz de confusão (as linhas são o ouro humano, as colunas são o juiz).
- Uma tabela de discordâncias com a instância, o rótulo humano, o rótulo do juiz, a confiança e o raciocínio do juiz.
- O histórico de versões do prompt com o κ médio por versão, de modo que o progresso da calibração fique visível.
O ouro humano é o voto da maioria entre os anotadores para cada instância.
Modo embutido
Com inline.enabled, cada página de anotação mostra o veredito em cache do juiz para a instância — seu rótulo, sua confiança e seu raciocínio expansível — ao lado de um κ em tempo real para a tarefa. «Aceitar» preenche a opção correspondente. Cada salvamento humano registra uma comparação humano↔juiz que alimenta a concordância em tempo real. Defina compute_on_demand: true para chamar o juiz ao vivo quando não houver um veredito em cache; caso contrário, execute o lote com antecedência, o que é mais rápido.
Notas e limitações
- Nesta versão, a calibração é manual: edite a rubrica e execute novamente. A otimização automática de prompts está fora do escopo.
- O escopo abrange os esquemas categóricos de escolha única. Julgar trechos (span) e texto livre é trabalho futuro.
- Execute o juiz sobre um conjunto de ouro focado de cerca de 100–200 instâncias rotuladas para obter um κ estável.
Relacionado
- Calibração de juiz LLM — calibração com vários juízes e cega para os humanos, com erro de calibração
- Fila de triagem — encaminhe primeiro aos humanos os itens mais informativos
- Guia de concordância entre anotadores — as métricas kappa em detalhe
Para detalhes de implementação, consulte a documentação de origem.