Avaliação multimodal de agentes
Avalie agentes que atuam além do texto: agentes de uso de computador e GUI, assistentes de voz, vídeo e agentes de documentos. O Potato adiciona esquemas feitos sob medida para trajetórias de GUI com ancoragem de cliques, linhas do tempo de voz full-duplex, ancoragem temporal de vídeo com IoU ao vivo, marcação de erros em transcrições de fala, raciocínio multimodal intercalado e estrutura de grade de tabela.
Os agentes atuam cada vez mais em modalidades além do texto: eles controlam GUIs, assistem a vídeos e mantêm conversas faladas. Cada modalidade precisa de uma tela de revisão que um widget de texto simples não consegue fornecer, uma captura de tela com o clique do agente, uma linha do tempo de voz de faixa dupla, um controle de avanço de vídeo com intervalos de referência. O Potato adiciona esquemas de anotação feitos sob medida para esses traces, ao lado de suas telas existentes de imagem, áudio e vídeo.
Cada esquema deriva seus passos, turnos ou segmentos do trace no momento da renderização, e cada um vem com um exemplo executável em examples/agent-traces/.
Trajetória de GUI / uso de computador (gui_trajectory)
Avalie um agente de uso de computador, GUI ou SO passo a passo (OSWorld, NeurIPS 2024; ScreenSpot-Pro; AndroidWorld). Cada passo mostra a captura de tela que o agente viu e a ação que ele realizou; o anotador julga a ação (correta / elemento errado / ação errada / alucinada). Quando um passo carrega coordenadas de clique, um marcador de ancoragem na captura de tela mostra se o clique acertou o elemento certo.
 Revise cada passo de uso de computador: correção da ação mais ancoragem do clique na captura de tela
Revise cada passo de uso de computador: correção da ação mais ancoragem do clique na captura de tela
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot # field on each step holding an image URL / data-URI
action_key: action # field holding the action text
coord_space: normalized # normalized (0..1) | pixels — for the x/y grounding marker
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Cada passo pode fornecer screenshot, action e, opcionalmente, x/y (ou um click: {x, y} aninhado). Armazenado como uma lista de {index, step, verdict, notes}.
Interação de voz / full-duplex (voice_interaction)
Anote uma conversa falada humano↔agente quanto à alternância de turnos e ao tratamento de interrupções (Full-Duplex-Bench, 2025). Uma linha do tempo de faixa dupla (faixa do usuário mais faixa do agente) posiciona cada turno por seus tempos de início e fim e destaca as regiões de sobreposição em que ambos os falantes falam ao mesmo tempo. O anotador classifica cada sobreposição (o agente deveria responder / deveria retomar / backchannel / incerto) e avalia a alternância de turnos geral; o áudio de origem é reproduzido em linha quando fornecido.
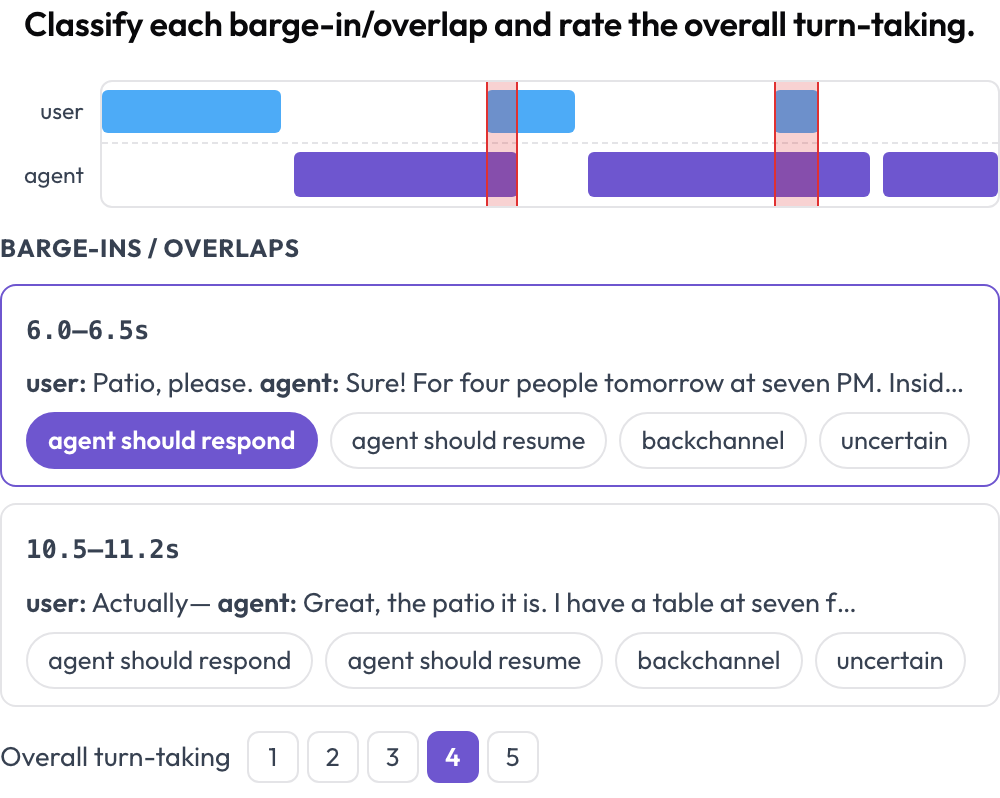 Uma linha do tempo de voz de faixa dupla com detecção de interrupções e pontuação de alternância de turnos
Uma linha do tempo de voz de faixa dupla com detecção de interrupções e pontuação de alternância de turnos
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns # list of {speaker, start, end, text} (seconds)
speaker_key: speaker
user_speakers: [user, human, caller] # everything else is treated as the agent
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5
# audio_key: audio # optional per-instance audio URL to enable the playerAs sobreposições entre turnos de falantes diferentes são calculadas no momento da renderização. Armazenado como {"overlaps": {idx: label}, "rating": int}.
Ancoragem temporal de vídeo (temporal_grounding)
Marque intervalos de tempo de eventos em um vídeo para avaliação de ancoragem temporal (TimeScope, 2025; ET-Bench). Para cada prompt de evento, o anotador define o [start, end] de referência, capturando a posição de reprodução ou digitando os segundos. Quando os dados carregam um intervalo previsto pelo modelo, uma IoU ao vivo e uma minilinha do tempo de duas barras (previsto vs. referência) são atualizadas conforme você ajusta. Isto é feito sob medida para a pontuação de localização previsto-vs-referência, distinta da rotulagem geral de segmentos.
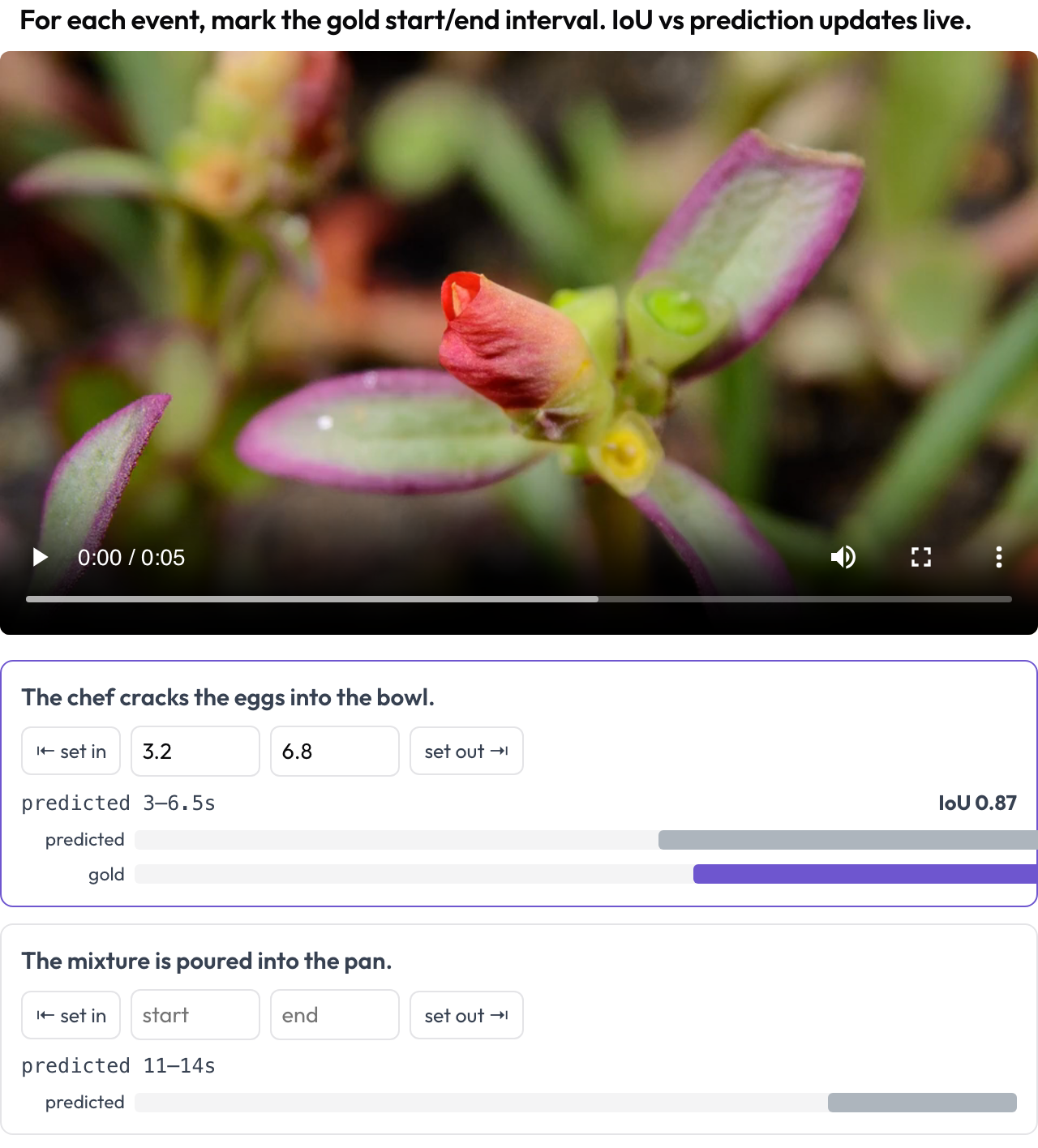 Marque intervalos de eventos de referência em vídeo com uma IoU ao vivo em relação à previsão do modelo
Marque intervalos de eventos de referência em vídeo com uma IoU ao vivo em relação à previsão do modelo
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video # per-instance video URL
events_key: events # list of {prompt, predicted: {start, end}} (predicted optional)
# duration: 120 # optional fixed timeline scale (else inferred from the video)Armazenado como {"events": {idx: {start, end}}}.
Erros de fala em transcrição alinhada (speech_transcript)
Anote uma transcrição de fala alinhada no tempo, segmento por segmento, quanto a erros de ASR/TTS e de qualidade de fala (Speak & Improve, 2025). Cada segmento {start, end, text, speaker?} é um cartão mostrando seu timestamp e texto; o anotador marca erros (erro de ASR / artefato de TTS / pronúncia errada / disfluência) e pode digitar a transcrição corrigida. Este é o complemento em nível de segmento da visão de alternância de turnos em voice_interaction.
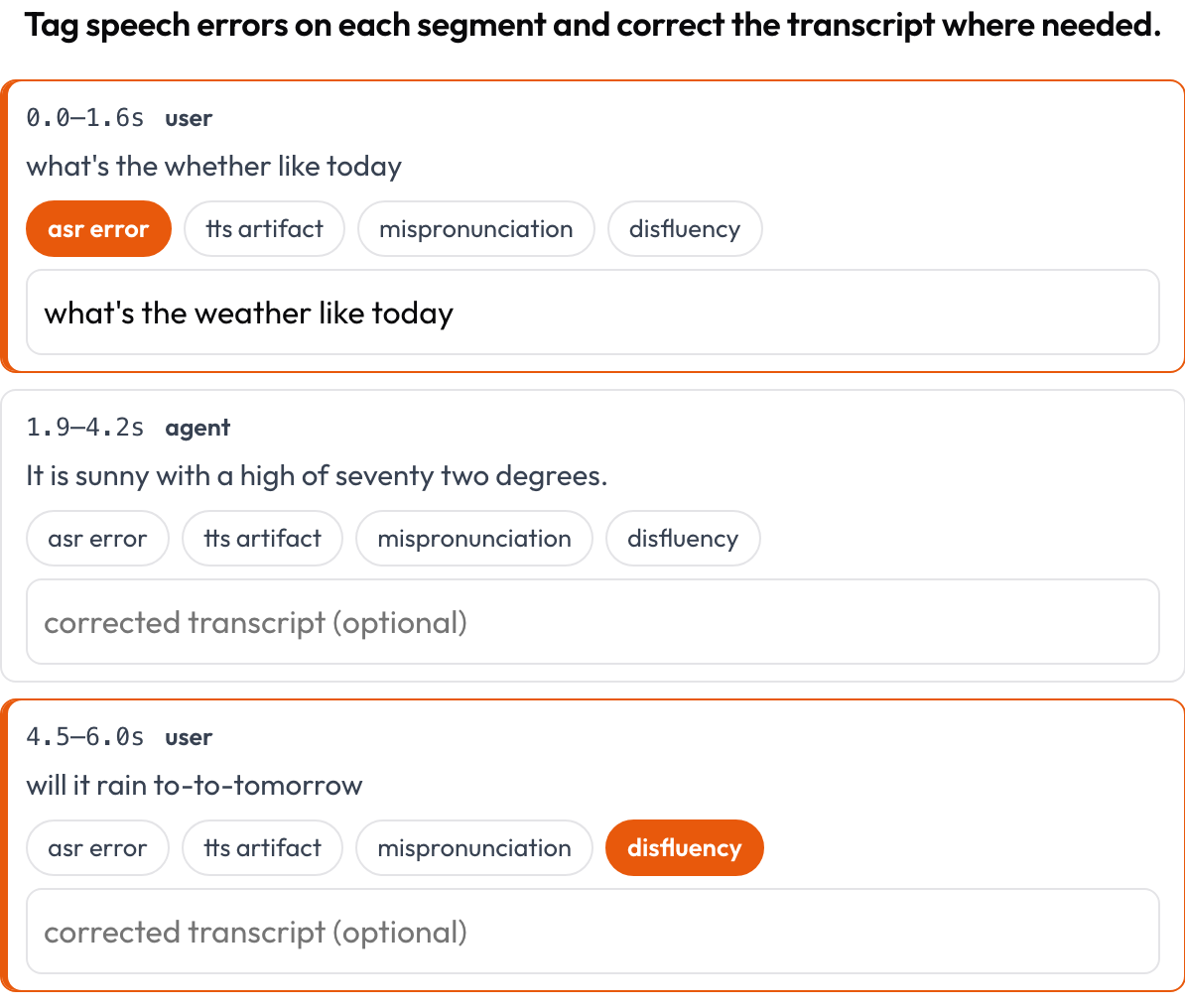 Marque erros de ASR/TTS/pronúncia por segmento e corrija a transcrição em linha
Marque erros de ASR/TTS/pronúncia por segmento e corrija a transcrição em linha
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments # list of {start, end, text, speaker?}
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true
# audio_key: audio # optional per-item audio URL to enable the playerArmazenado como uma lista de {index, start, end, errors, correction}.
Raciocínio multimodal intercalado (multimodal_reasoning)
Avalie um trace de raciocínio texto ↔ imagem ↔ ferramenta ↔ ação intercalado, passo a passo (Multimodal RewardBench 2, 2025; Zebra-CoT). Cada passo é um bloco tipado, renderizado em linha por seu tipo; o anotador julga a coerência de cada passo, o raciocínio decorre da imagem e dos passos anteriores, ou o visual é alucinado?
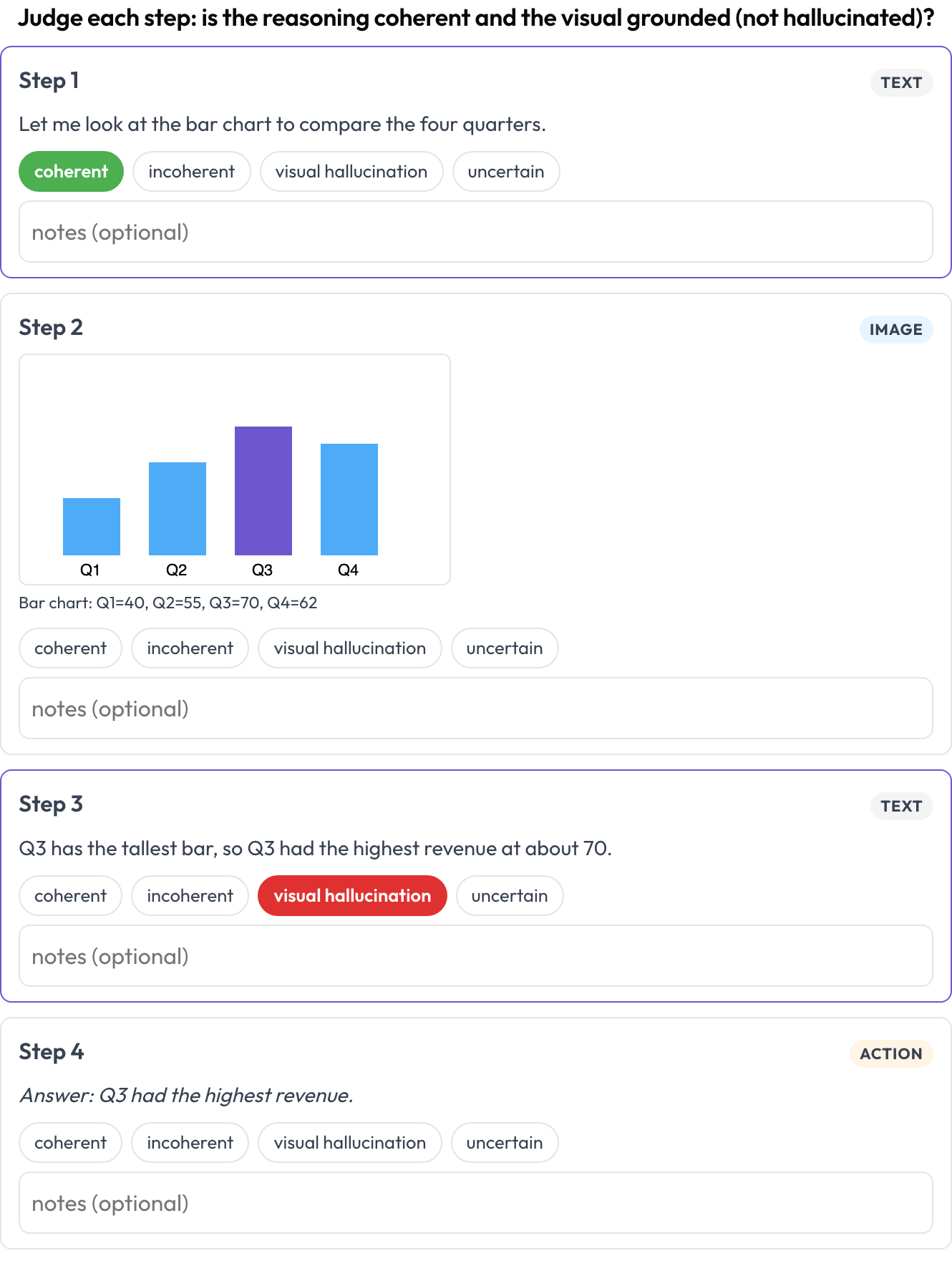 Avalie cada passo de um trace de raciocínio texto-imagem-ferramenta quanto à coerência e à alucinação visual
Avalie cada passo de um trace de raciocínio texto-imagem-ferramenta quanto à coerência e à alucinação visual
annotation_schemes:
- annotation_type: multimodal_reasoning
name: reasoning_review
description: "Judge each step: coherent reasoning and grounded visuals?"
steps_key: steps
type_key: type # each step's 'type': text | image | tool | action (inferred if absent)
verdict_options: [coherent, incoherent, visual_hallucination, uncertain]Cada passo pode carregar text/content, image/image_url (+caption) ou tool/args. Armazenado como uma lista de {index, step, type, verdict, notes}.
Estrutura de grade de tabela (table_grid)
Anote a estrutura de células de uma imagem de tabela, a parte específica de documentos que caixas delimitadoras simples não conseguem capturar (OmniDocBench, CVPR 2025; RealHiTBench). O anotador define as dimensões da grade e clica nas células para marcar seu papel (dados / cabeçalho de coluna / cabeçalho de linha / vazia). As caixas de região por página já são cobertas executando a anotação de imagem por página, então este esquema foca na estrutura que essas caixas não conseguem expressar.
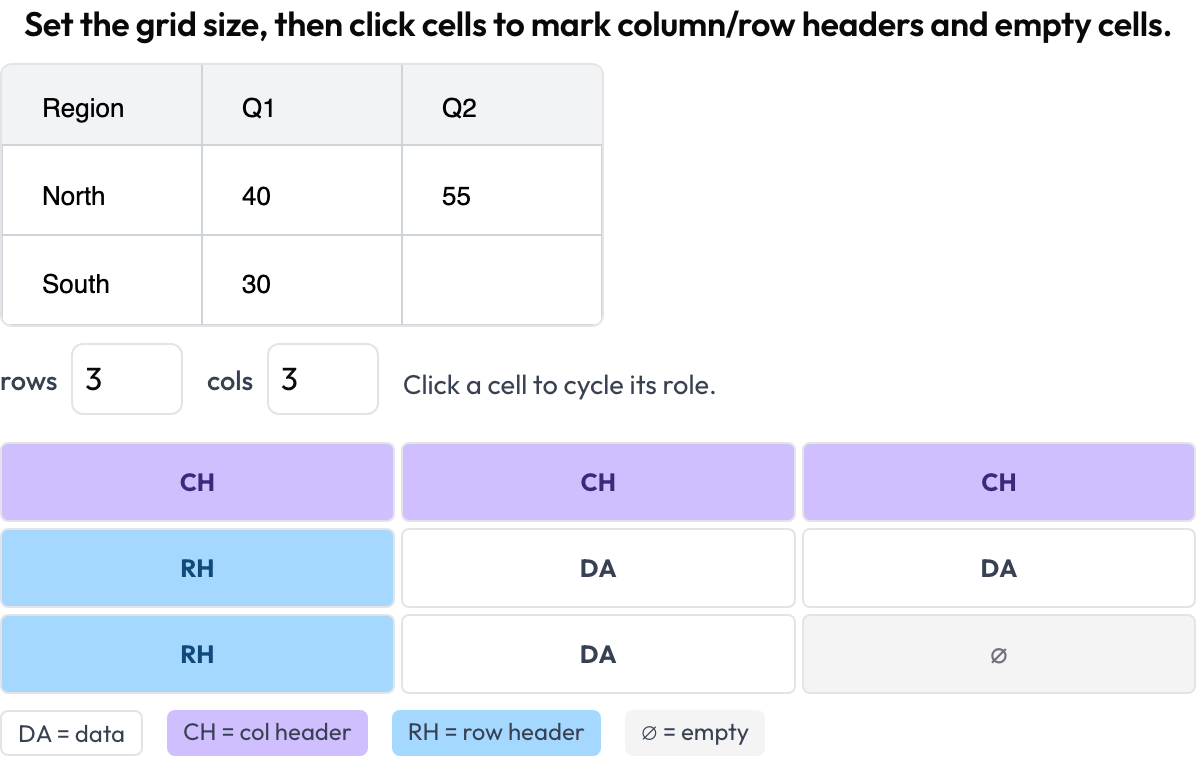 Anote a estrutura de células de tabela de documento: cabeçalhos de coluna e de linha, dados e células vazias
Anote a estrutura de células de tabela de documento: cabeçalhos de coluna e de linha, dados e células vazias
annotation_schemes:
- annotation_type: table_grid
name: structure
description: "Set the grid size, then click cells to mark headers and empty cells."
image_key: image # per-instance table image URL / data-URI
rows_key: rows # optional initial dims from the data
cols_key: cols
roles: [data, col_header, row_header, empty] # click cycles through theseArmazenado como {rows, cols, cells: {"r,c": role}}, mantendo apenas as células que não são data.
Relacionado
- Avaliação de equipes multiagentes — grafo de interação, transferências e scorecards de equipe
- Avaliação de agentes web — agentes web de captura de tela e ação
- Como avaliar agentes de IA — os níveis de avaliação de agentes
- Anotação agêntica — configuração e ingestão da tela de trace
Para detalhes de implementação, consulte a documentação de origem.