मल्टी-एजेंट टीम मूल्यांकन
मल्टी-एजेंट सिस्टम को एक सपाट ट्रांसक्रिप्ट के बजाय टीम संरचना के आधार पर एनोटेट करें। Potato एक क्लिक करने योग्य एजेंट-इंटरैक्शन ग्राफ़, क्रॉस-एजेंट विफलता आरोपण, हैंडऑफ़ समीक्षा, प्रति-एजेंट और प्रति-टीम स्कोरकार्ड, एक टूल-कंटेंशन टाइमलाइन, और इमर्जेंट-व्यवहार टैगिंग जोड़ता है।
एक मल्टी-एजेंट सिस्टम एकल एजेंट से अलग तरीके से विफल होता है: टूटन एजेंटों के बीच, किसी हैंडऑफ़ पर, या जिस तरह टीम संगठित की गई थी उसमें होती है। ऐसे सिस्टम का मूल्यांकन करने का मतलब है परिणामों को इस आधार पर आरोपित करना कि कौन सा एजेंट, कौन सा चरण, और कौन सा हैंडऑफ़ ज़िम्मेदार था, न कि केवल एक सपाट ट्रांसक्रिप्ट को स्कोर करना। Potato इसके लिए बनाई गई एनोटेशन सतहों का एक समूह जोड़ता है: एक क्लिक करने योग्य इंटरैक्शन ग्राफ़, विफलता आरोपण, हैंडऑफ़ समीक्षा, प्रति-एजेंट और प्रति-टीम स्कोरकार्ड, एक टूल-कंटेंशन टाइमलाइन, और क्रॉस-लेन इमर्जेंट-व्यवहार टैगिंग।
ये एजेंट-ट्रेस डिस्प्ले और MAST विफलता वर्गीकरण पर आधारित हैं। प्रत्येक स्कीमा रेंडर के समय ट्रेस से ही अपने एजेंट, चरण और हैंडऑफ़ प्राप्त करती है, इसलिए एनोटेटर वही चुनता है जो रन में वास्तव में हुआ।
इंटरैक्शन ग्राफ़ (agent_interaction_graph)
पूरा रन एक दिशात्मक ग्राफ़ के रूप में रेंडर होता है: नोड्स एजेंट हैं, एज उनके बीच के संदेश और हैंडऑफ़ संक्रमण हैं (मोटे एज का अर्थ है अधिक बार-बार), जो ट्रेस से स्वतः रूप से व्यवस्थित होते हैं। एनोटेटर क्रिटिकल पाथ को चिह्नित करने के लिए किसी नोड पर क्लिक करता है और किसी एज को normal → critical → problematic चक्रित करने के लिए उस पर क्लिक करता है। यह "मैं मल्टी-एजेंट रन की संरचना कैसे देखूँ" का सबसे स्पष्ट उत्तर है, और यह एक ऐसी सतह है जो सामान्य एनोटेशन टूल प्रदान नहीं करते।
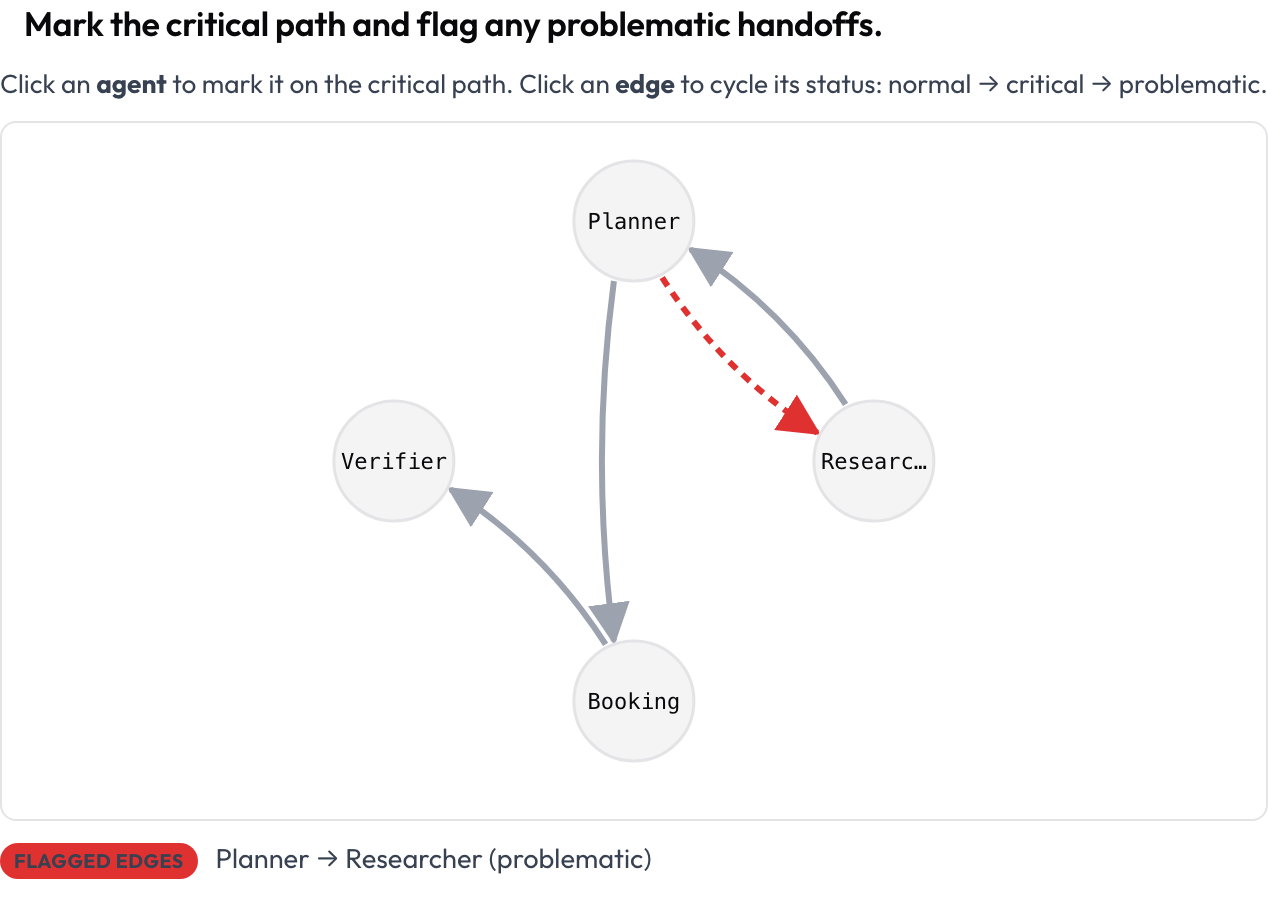 Mark the critical path and flag problematic handoffs on a clickable agent-interaction graph
Mark the critical path and flag problematic handoffs on a clickable agent-interaction graph
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agent{"critical_nodes": [...], "edges": {"A->B": "problematic", ...}} के रूप में संग्रहीत। प्रत्येक नोड और एज कीबोर्ड-फ़ोकस करने योग्य है और एक लाइव टेक्स्ट सारांश क्रिटिकल नोड्स और चिह्नित एज को सूचीबद्ध करता है, इसलिए अर्थ कभी केवल रंग से नहीं ले जाया जाता।
क्रॉस-एजेंट विफलता आरोपण (failure_attribution)
जब कोई टीम विफल होती है, तो उपयोगी लेबल विफलता-आरोपण साहित्य से (ज़िम्मेदार एजेंट, निर्णायक चरण, कारण) त्रिक होता है (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, Who&When डेटासेट)। एजेंट ड्रॉपडाउन और चरण चयनकर्ता ट्रेस के अपने टर्न से भरे जाते हैं, इसलिए एनोटेटर विफलता को एक वास्तविक एजेंट और एक वास्तविक चरण पर आरोपित करता है।
 Attribute a multi-agent failure to the responsible agent, the decisive step, and why
Attribute a multi-agent failure to the responsible agent, the decisive step, and why
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the trace{"responsible_agent", "decisive_step", "reason"} के रूप में संग्रहीत। इसे एक radio परिणाम स्कीमा (success/failure) के साथ जोड़ें ताकि आरोपण केवल विफल रन पर सक्रिय हो।
हैंडऑफ़ समीक्षा (handoff_review)
प्रत्येक हैंडऑफ़, जहाँ एक एजेंट नियंत्रण दूसरे को सौंपता है, एनोटेट करने के लिए एक प्रथम-श्रेणी की वस्तु बन जाता है। जहाँ भी लगातार टर्न के बीच कार्यरत एजेंट बदलता है, Potato एक हैंडऑफ़ कार्ड A → B उत्पन्न करता है; एनोटेटर इंटर-एजेंट गलत-संरेखण को चिह्नित करता है और हैंडऑफ़ की गुणवत्ता को रेट करता है। विफलता के तरीके MAST की इंटर-एजेंट श्रेणी और "echoing" परिघटना (Zhang et al., 2025) पर आधारित हैं।
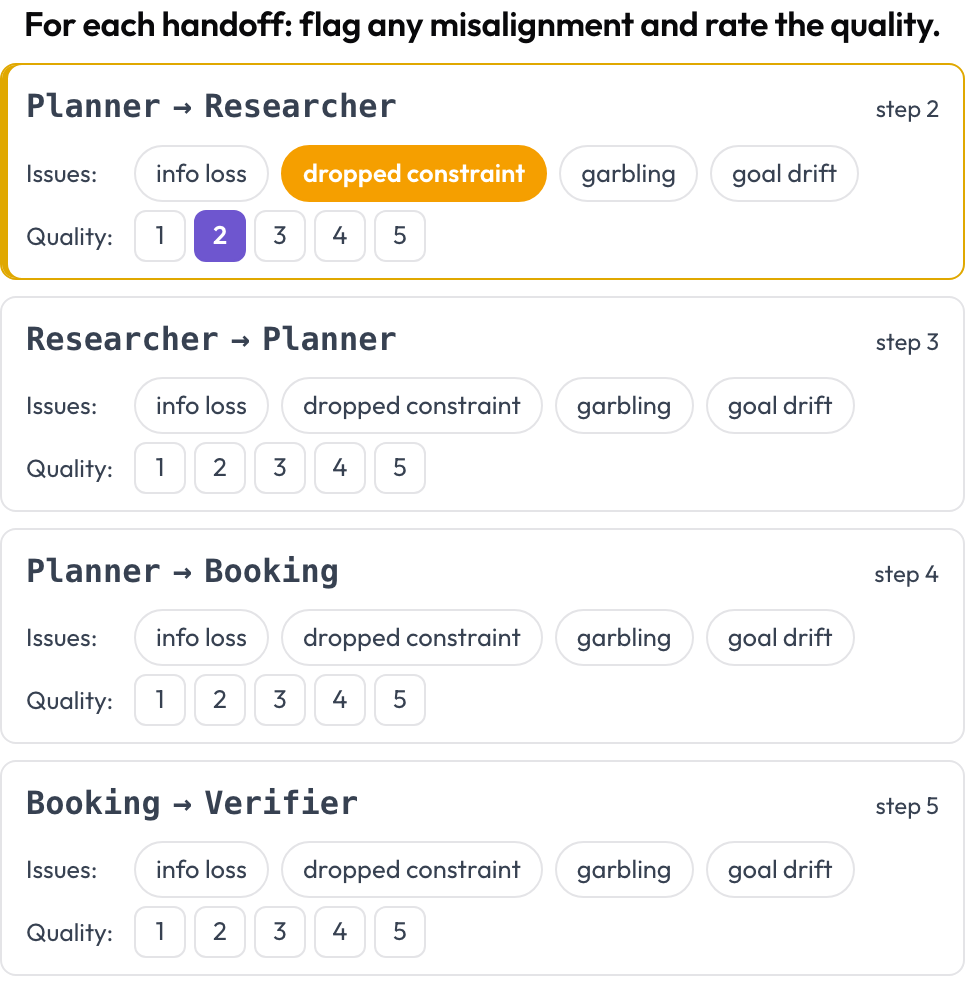 Flag inter-agent misalignment on every handoff and rate its quality
Flag inter-agent misalignment on every handoff and rate its quality
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5हैंडऑफ़ रेंडर के समय ट्रेस से प्राप्त किए जाते हैं, इसलिए कोई मैन्युअल सेटअप नहीं है। {index, step, from, to, flags, quality} की एक सूची के रूप में संग्रहीत।
प्रति-एजेंट और प्रति-टीम स्कोरकार्ड (agent_scorecard)
एक रन को एक साथ दो स्तरों पर स्कोर करें (MultiAgentBench, Zhou et al., ACL 2025): प्रत्येक एजेंट को प्रति-आयाम स्कोर मिलते हैं (role fidelity, contribution, coordination), टीम को साझा-आयाम स्कोर मिलते हैं, और वैकल्पिक माइलस्टोन की जाँच की जाती है। एजेंट पंक्तियाँ ट्रेस के अपने टर्न से आती हैं, इसलिए मैट्रिक्स उससे मेल खाता है जिसने वास्तव में भाग लिया।
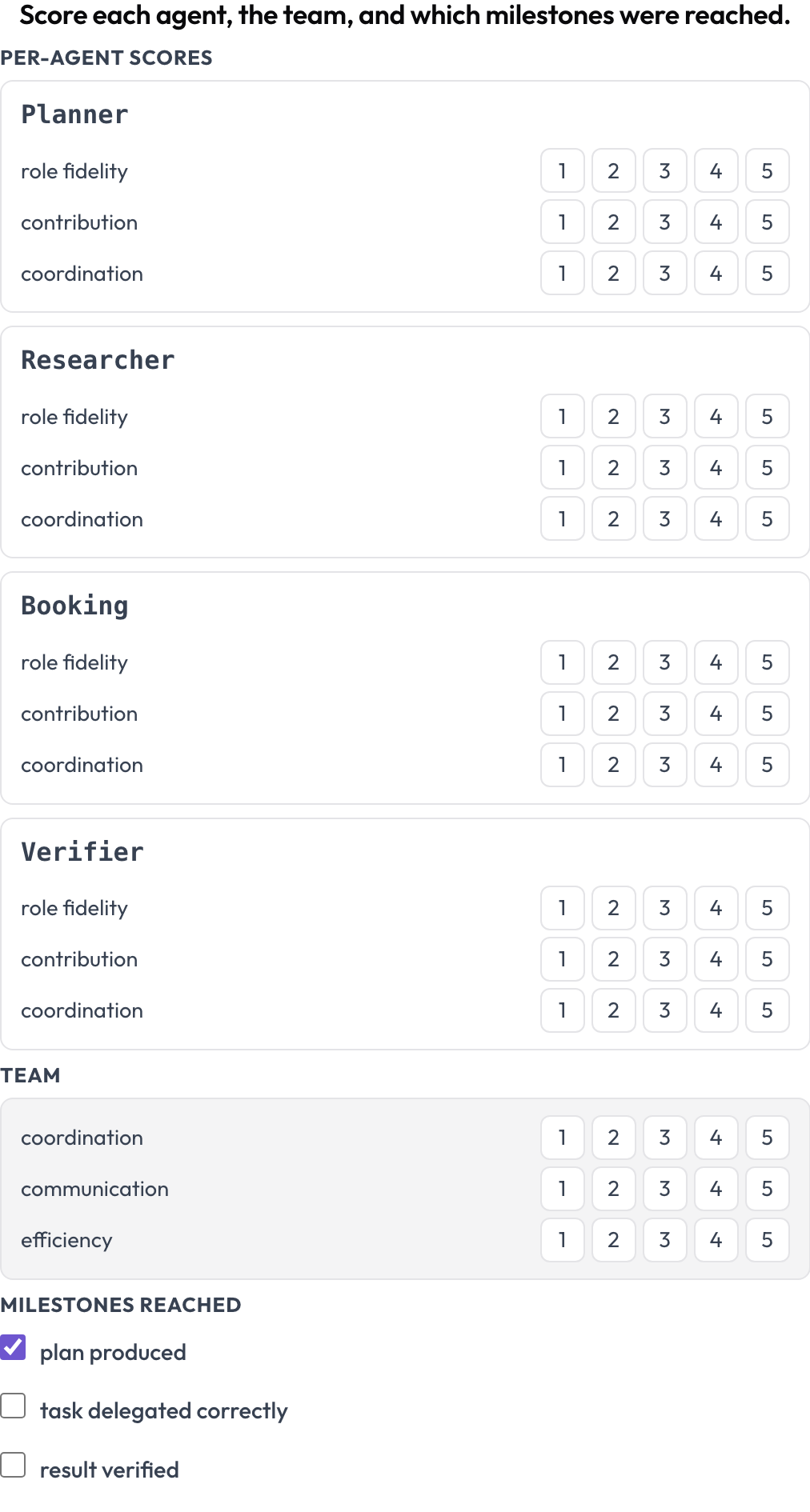 Score every agent on role fidelity, contribution, and coordination, plus the team and milestones
Score every agent on role fidelity, contribution, and coordination, plus the team and milestones
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optional{"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}} के रूप में संग्रहीत।
टूल / संसाधन-कंटेंशन टाइमलाइन (tool_contention)
एजेंटों के बीच समवर्ती टूल और संसाधन उपयोग एक बहु-लेन टाइमलाइन पर रेंडर होता है, प्रति एजेंट एक लेन। जहाँ दो कॉल एक ही संसाधन को अतिव्यापी समय पर स्पर्श करती हैं, वे क्षेत्र लेन के पार हाइलाइट किए जाते हैं और वर्गीकरण के लिए सूचीबद्ध किए जाते हैं: deadlock, circular wait, race condition, या benign (DPBench, 2026)। इसी तरह आप समवर्ती विफलताओं को पकड़ते हैं जिन्हें प्रति-टर्न ट्रांसक्रिप्ट छिपा देता है।
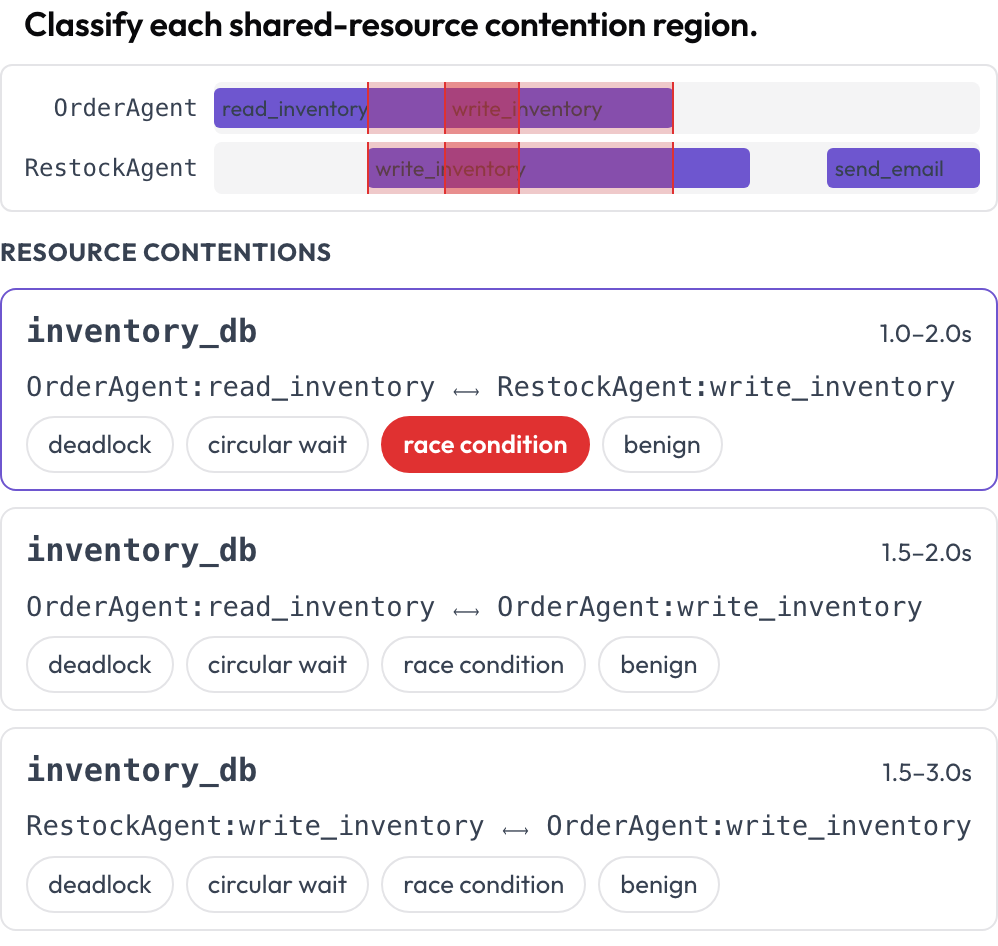 Spot deadlocks and race conditions on a per-agent tool-call timeline
Spot deadlocks and race conditions on a per-agent tool-call timeline
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]कंटेंशन क्षेत्र रेंडर के समय गणना किए जाते हैं (समान resource, अतिव्यापी अंतराल)। {"contentions": {idx: label}} के रूप में संग्रहीत।
क्रॉस-लेन इमर्जेंट व्यवहार (emergent_behavior)
कुछ विफलताएँ सामूहिक होती हैं: collusion, groupthink, cascading errors, role drift। एक इमर्जेंट व्यवहार एक सतत टेक्स्ट स्पैन नहीं है; यह भाग लेने वाले टर्न का एक समूह है, संभवतः अलग-अलग एजेंटों से। प्रत्येक व्यवहार के लिए एनोटेटर उन टर्न की जाँच करता है जो भाग लेते हैं और एक नोट जोड़ता है, एक क्रॉस-लेन स्पैन जिसे टर्न-समूह के रूप में व्यक्त किया जाता है।
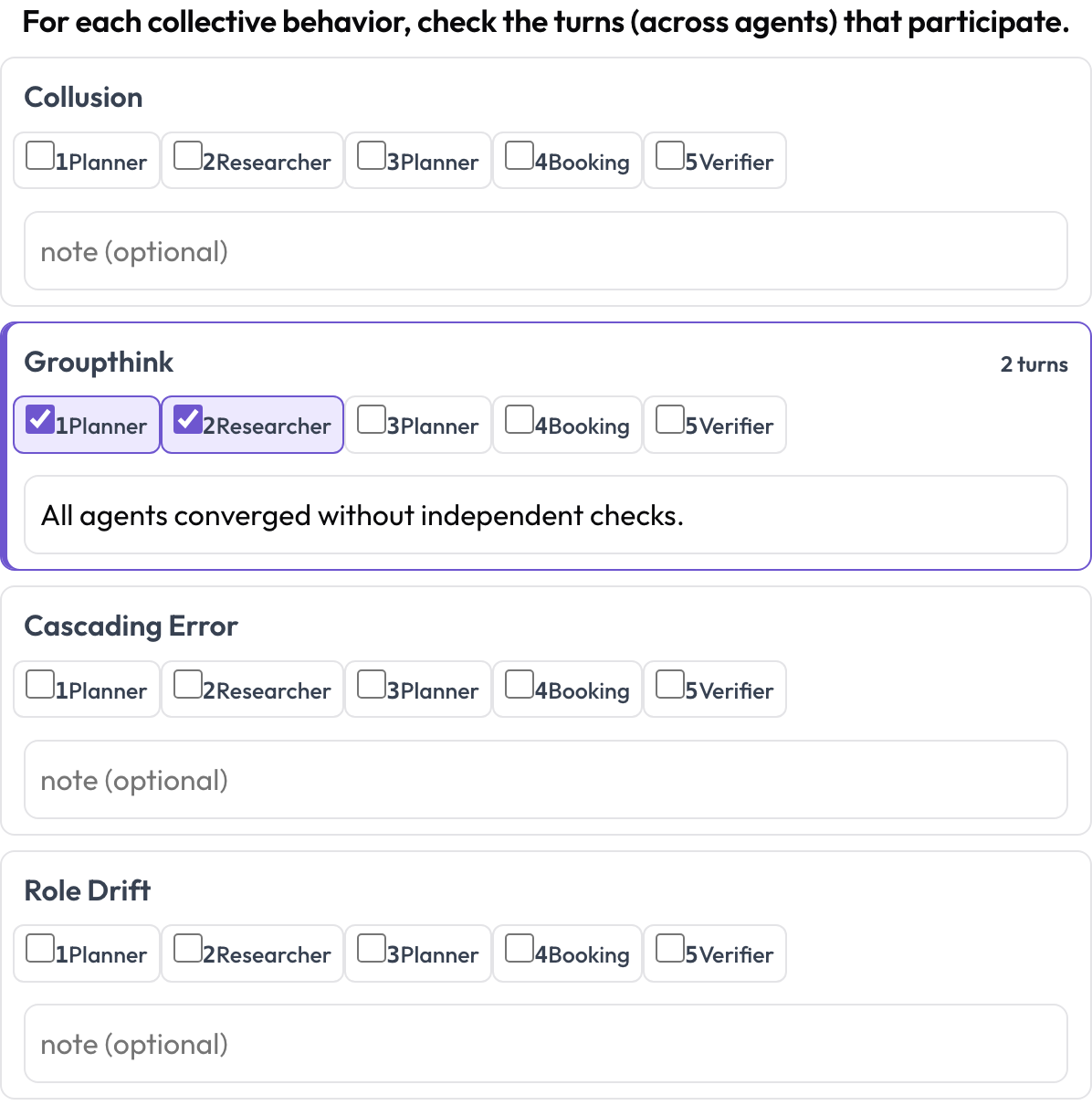 Tag collusion, groupthink, and cascading errors across agents and turns
Tag collusion, groupthink, and cascading errors across agents and turns
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: true{behavior: {turns: [idx...], note}} के रूप में संग्रहीत, केवल गैर-रिक्त व्यवहारों को रखते हुए।
टूल-कॉल समीक्षा (tool_call_review)
प्रत्येक टूल या फ़ंक्शन कॉल को अलग-अलग आँकें: क्या सही टूल चुना गया, क्या तर्क सही थे, क्या क्रम सही था (BFCL v4 / MCPMark को प्रतिबिंबित करते हुए)? टूल कॉल रेंडर के समय ट्रेस चरणों से निकाले जाते हैं; प्रत्येक चरण के tool_calls, tool_call, या action टूल नाम और सुंदर रूप से मुद्रित तर्कों के साथ एक कार्ड बन जाते हैं।
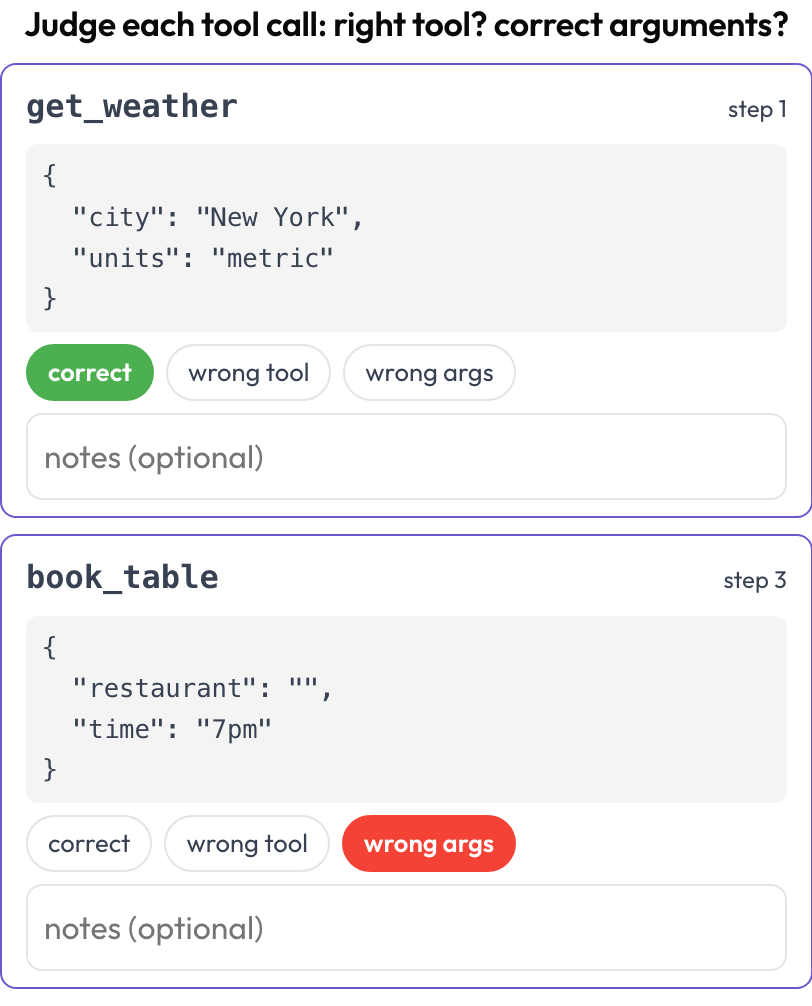 Judge every tool call: right tool, correct arguments, right order
Judge every tool call: right tool, correct arguments, right order
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizable{index, step, tool, verdict, notes} की एक सूची के रूप में संग्रहीत।
चरण-स्तर पर MAST टैगिंग
14-मोड MAST विफलता वर्गीकरण (Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025) को उस सटीक चरण (और इसलिए कार्यरत एजेंट) से बाँधने के लिए आपको एक नई स्कीमा की आवश्यकता नहीं है जहाँ विफलता हुई। मौजूदा प्रति-चरण trajectory_eval स्कीमा को MAST मोड के साथ इसके error_types के रूप में कॉन्फ़िगर करें, जो तीन MAST श्रेणियों द्वारा समूहीकृत हों। पूर्ण कवरेज के लिए इसे failure_attribution और handoff_review के साथ जोड़ें।
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]ऑर्केस्ट्रेशन लेंस चुनना
ऑर्केस्ट्रेशन आर्किटेक्चर अक्सर एक रन के परिणाम पर हावी होता है, इसलिए इसे एक प्रथम-श्रेणी के लेबल के रूप में पकड़ना सार्थक है। किसी नई स्कीमा की आवश्यकता नहीं है: एक radio रन के पैटर्न की पुष्टि या सुधार करता है, जो फिर मूल्यांकन लेंस और ट्रेस के लेआउट दोनों का मार्गदर्शन करता है (sequential → lanes, hierarchical → tree, group-chat → board)।
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueसंबंधित
- मल्टीमॉडल-एजेंट मूल्यांकन — GUI, voice, video, और document-agent स्कीमा
- एजेंट ट्रेजेक्टरी एनोटेट करना — प्रति-चरण त्रुटि एनोटेशन
- AI एजेंटों का मूल्यांकन कैसे करें — एजेंट मूल्यांकन के स्तर
- एजेंटिक एनोटेशन — ट्रेस-डिस्प्ले कॉन्फ़िगरेशन और इन्जेशन
कार्यान्वयन विवरण के लिए, स्रोत दस्तावेज़ीकरण देखें।