जज ↔ मानव संरेखण
मापें कि एक LLM जज आपके मानव गोल्ड लेबल से कितनी अच्छी तरह सहमत होता है। Potato एनोटेट किए गए उदाहरणों पर जज को चलाता है, Cohen's kappa, एक भ्रम आव्यूह और असहमति सूची की गणना करता है, और जैसे-जैसे आप रूब्रिक को परिष्कृत करते हैं, सहमति को ट्रैक करता है।
जज संरेखण मापता है और ट्यून करता है कि एक LLM जज आपके मानव गोल्ड लेबल से कितनी अच्छी तरह सहमत होता है। Potato उन उदाहरणों पर एक कॉन्फ़िगर करने योग्य LLM-as-a-judge चलाता है जिन्हें आपके एनोटेटर पहले ही लेबल कर चुके हैं, Cohen's κ, एक भ्रम आव्यूह और असहमति सूची की गणना करता है, और जैसे-जैसे आप जज की रूब्रिक संपादित करते हैं, κ को ट्रैक करता है। इनलाइन मोड चालू होने पर, एनोटेशन के दौरान जज का फ़ैसला मानव लेबल के बगल में दिखाई देता है, साथ में एक चालू κ भी।
यह वही मानक "अपने जज को लगभग 100–200 गोल्ड लेबल के साथ संरेखित करें" लूप है जिसका उपयोग LangSmith Align Evals और Evidently जैसे उपकरण करते हैं: मानव लेबल इकट्ठा करें, जज चलाएँ, असहमतियों का निरीक्षण करें, रूब्रिक परिष्कृत करें, और तब तक फिर से चलाएँ जब तक सहमति ऊँची न हो जाए।
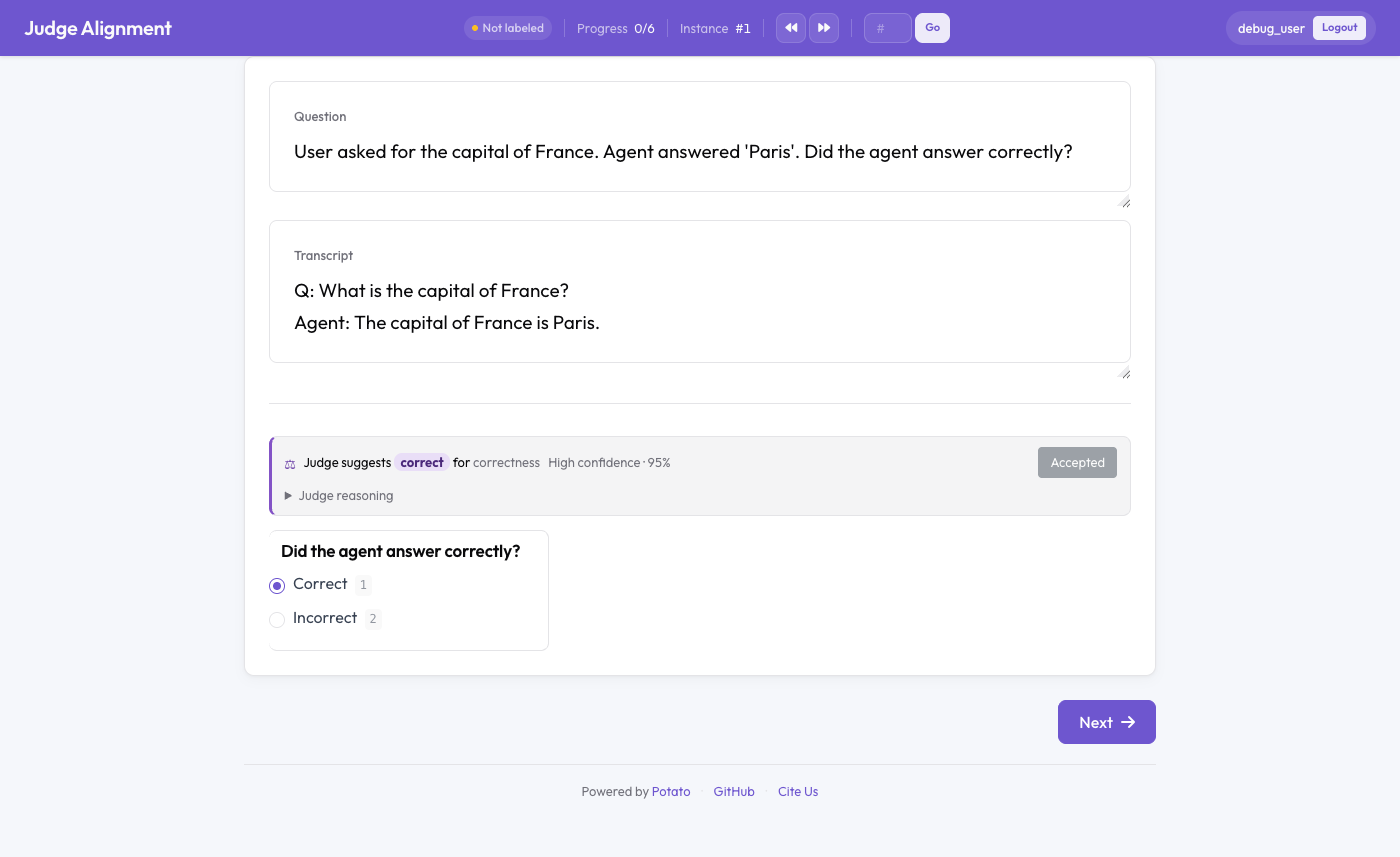 मानव एनोटेशन के बगल में एक चालू kappa के साथ दिखाया गया LLM जज का फ़ैसला
मानव एनोटेशन के बगल में एक चालू kappa के साथ दिखाया गया LLM जज का फ़ैसला
कॉन्फ़िगरेशन
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict existsदायरा एकल-चयन श्रेणीगत योजनाओं (radio, select, likert) तक सीमित है। यदि judge_alignment.schemas सेट किया गया है, तो केवल उन्हीं योजनाओं का मूल्यांकन किया जाता है; अन्यथा सभी श्रेणीगत योजनाओं का।
जज चलाना
जज को एडमिन API से चलाएँ। पूर्वानुमान प्रति प्रॉम्प्ट संस्करण कैश किए जाते हैं, इसलिए दोबारा चलाना सस्ता पड़ता है:
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'कैलिब्रेट करने के लिए, एक संपादित रूब्रिक पास करें। इससे एक नया प्रॉम्प्ट संस्करण बनता है, ताकि आप विभिन्न दौरों में κ की तुलना कर सकें:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'संरेखण रिपोर्ट
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
X-API-Key हेडर भेजें। प्रत्येक योजना के लिए, रिपोर्ट यह दिखाती है:
- Cohen's κ एक Landis–Koch व्याख्या, सहमति दर, और तुलना किए गए उदाहरणों की संख्या के साथ।
- एक भ्रम आव्यूह (पंक्तियाँ मानव गोल्ड हैं, स्तंभ जज हैं)।
- एक असहमति तालिका जिसमें उदाहरण, मानव लेबल, जज लेबल, विश्वास, और जज का तर्क शामिल है।
- प्रॉम्प्ट-संस्करण इतिहास प्रति संस्करण औसत κ के साथ, ताकि कैलिब्रेशन की प्रगति दिखाई दे।
मानव गोल्ड प्रत्येक उदाहरण के लिए एनोटेटरों के बीच बहुमत मत होता है।
इनलाइन मोड
inline.enabled के साथ, प्रत्येक एनोटेशन पृष्ठ उस उदाहरण के लिए जज का कैश किया गया फ़ैसला दिखाता है — उसका लेबल, विश्वास, और विस्तार-योग्य तर्क — साथ में कार्य के लिए एक चालू κ। "Accept" मिलते-जुलते विकल्प को भर देता है। प्रत्येक मानव सेव एक मानव↔जज तुलना दर्ज करता है जो चालू सहमति में योगदान देता है। जब कोई कैश किया गया फ़ैसला मौजूद न हो तो जज को लाइव कॉल करने के लिए compute_on_demand: true सेट करें; अन्यथा बैच को पहले से चलाएँ, जो तेज़ होता है।
नोट्स और सीमाएँ
- इस संस्करण में कैलिब्रेशन मैनुअल है: रूब्रिक संपादित करें और दोबारा चलाएँ। स्वचालित प्रॉम्प्ट अनुकूलन दायरे से बाहर है।
- दायरा एकल-चयन श्रेणीगत योजनाओं तक सीमित है। स्पैन और मुक्त-पाठ का मूल्यांकन भविष्य का कार्य है।
- एक स्थिर κ के लिए जज को लगभग 100–200 लेबल किए गए उदाहरणों के एक केंद्रित गोल्ड सेट पर चलाएँ।
संबंधित
- LLM-as-Judge कैलिब्रेशन — कैलिब्रेशन त्रुटि के साथ बहु-जज, मानव-अंधा कैलिब्रेशन
- ट्रायेज क़तार — सबसे जानकारीपूर्ण वस्तुओं को पहले मनुष्यों तक पहुँचाएँ
- एनोटेटर-अंतर सहमति गाइड — kappa मापदंड विस्तार से
कार्यान्वयन विवरण के लिए, स्रोत दस्तावेज़ीकरण देखें।