Évaluation des agents multimodaux
Évaluez les agents qui agissent au-delà du texte, agents d'usage informatique et GUI, assistants vocaux, vidéo et agents documentaires. Potato ajoute des schémas conçus sur mesure pour les trajectoires GUI avec ancrage du clic, les chronologies vocales en duplex intégral, l'ancrage temporel vidéo avec IoU en direct, le marquage d'erreurs de transcription, le raisonnement multimodal entrelacé et la structure de grille de tableau.
Les agents agissent de plus en plus dans des modalités au-delà du texte : ils pilotent des interfaces graphiques, regardent des vidéos et tiennent des conversations parlées. Chaque modalité nécessite une surface d'examen qu'un simple widget de texte ne peut fournir, une capture d'écran avec le clic de l'agent, une chronologie vocale à double piste, un curseur vidéo avec des intervalles de référence. Potato ajoute des schémas d'annotation conçus sur mesure pour ces traces, aux côtés de ses affichages existants pour l'image, l'audio et la vidéo.
Chaque schéma dérive ses étapes, ses tours ou ses segments de la trace au moment du rendu, et chacun est livré avec un exemple exécutable dans examples/agent-traces/.
Trajectoire GUI / usage informatique (gui_trajectory)
Évaluez un agent d'usage informatique, GUI ou OS étape par étape (OSWorld, NeurIPS 2024 ; ScreenSpot-Pro ; AndroidWorld). Chaque étape montre la capture d'écran que l'agent a vue et l'action qu'il a entreprise ; l'annotateur juge l'action (correcte / mauvais élément / mauvaise action / hallucinée). Lorsqu'une étape comporte des coordonnées de clic, un marqueur d'ancrage sur la capture d'écran indique si le clic a atterri sur le bon élément.
 Examinez chaque étape d'usage informatique : exactitude de l'action plus ancrage du clic sur la capture d'écran
Examinez chaque étape d'usage informatique : exactitude de l'action plus ancrage du clic sur la capture d'écran
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot # field on each step holding an image URL / data-URI
action_key: action # field holding the action text
coord_space: normalized # normalized (0..1) | pixels — for the x/y grounding marker
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Chaque étape peut fournir screenshot, action, et un x/y facultatif (ou un click: {x, y} imbriqué). Stocké sous forme de liste de {index, step, verdict, notes}.
Interaction vocale / duplex intégral (voice_interaction)
Annotez une conversation parlée humain↔agent pour la prise de parole et la gestion des interruptions (Full-Duplex-Bench, 2025). Une chronologie à double piste (couloir utilisateur plus couloir agent) place chaque tour selon ses heures de début et de fin et met en évidence les régions de chevauchement où les deux interlocuteurs parlent en même temps. L'annotateur classe chaque chevauchement (l'agent devrait répondre / devrait reprendre / signal d'écoute / incertain) et évalue la prise de parole globale ; l'audio source est lu en ligne lorsqu'il est fourni.
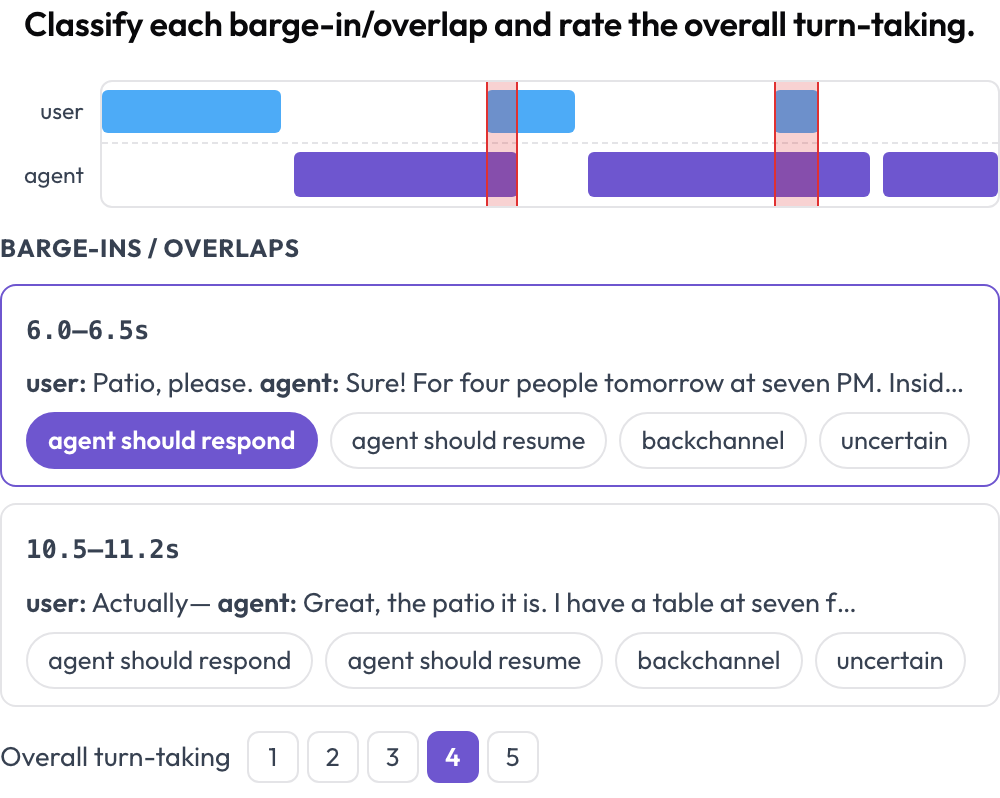 Une chronologie vocale à double piste avec détection des interruptions et évaluation de la prise de parole
Une chronologie vocale à double piste avec détection des interruptions et évaluation de la prise de parole
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns # list of {speaker, start, end, text} (seconds)
speaker_key: speaker
user_speakers: [user, human, caller] # everything else is treated as the agent
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5
# audio_key: audio # optional per-instance audio URL to enable the playerLes chevauchements entre tours de locuteurs différents sont calculés au moment du rendu. Stocké sous la forme {"overlaps": {idx: label}, "rating": int}.
Ancrage temporel vidéo (temporal_grounding)
Marquez les intervalles temporels d'événements dans une vidéo pour l'évaluation de l'ancrage temporel (TimeScope, 2025 ; ET-Bench). Pour chaque invite d'événement, l'annotateur fixe le [start, end] de référence, en capturant la tête de lecture ou en saisissant des secondes. Lorsque les données comportent un intervalle prédit par un modèle, un IoU en direct et une mini-chronologie à deux barres (prédit vs référence) se mettent à jour au fur et à mesure de vos ajustements. C'est conçu sur mesure pour la notation de localisation prédit-vs-référence, distincte de l'étiquetage de segments généraliste.
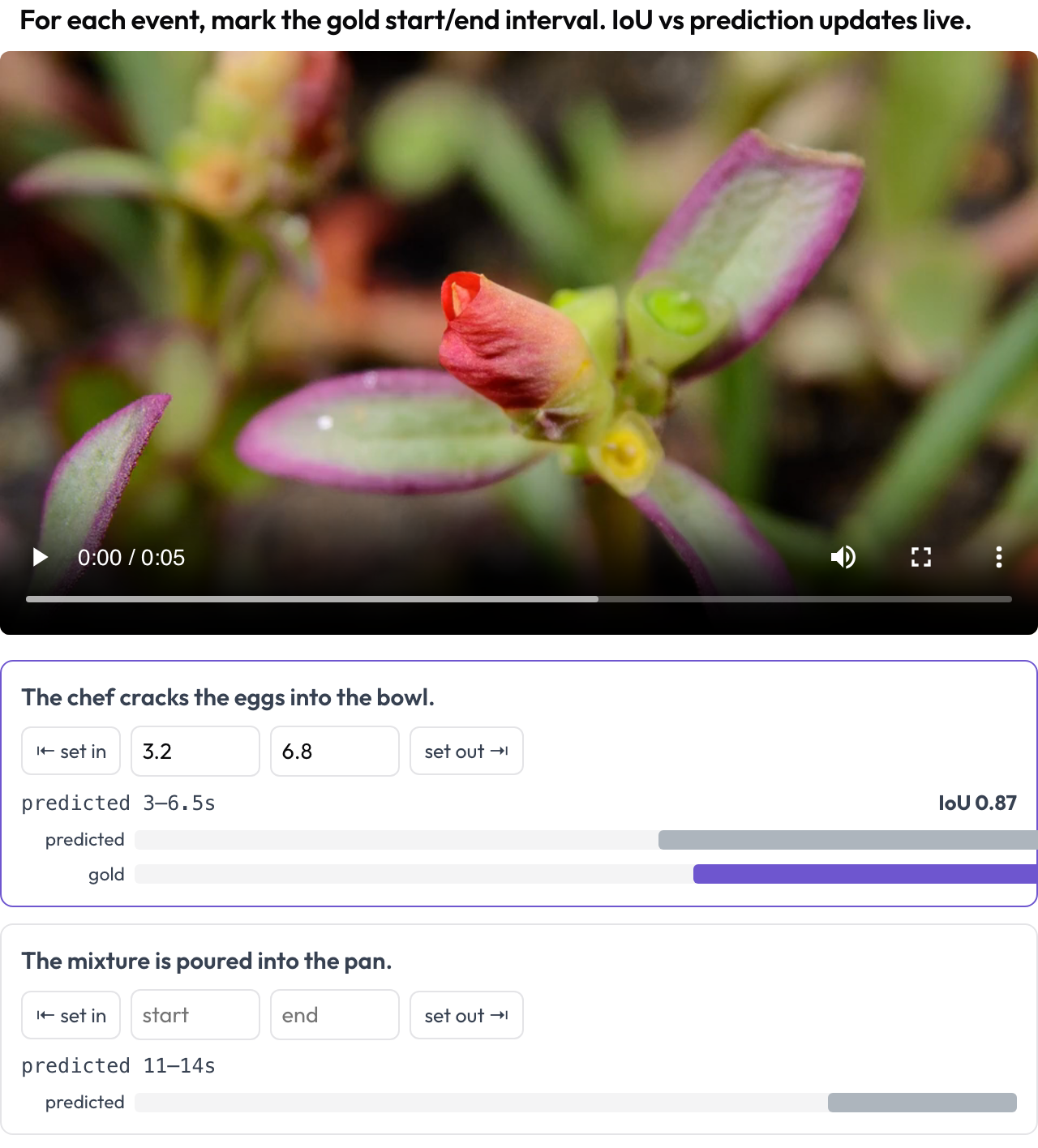 Marquez les intervalles d'événements de référence sur la vidéo avec un IoU en direct par rapport à la prédiction du modèle
Marquez les intervalles d'événements de référence sur la vidéo avec un IoU en direct par rapport à la prédiction du modèle
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video # per-instance video URL
events_key: events # list of {prompt, predicted: {start, end}} (predicted optional)
# duration: 120 # optional fixed timeline scale (else inferred from the video)Stocké sous la forme {"events": {idx: {start, end}}}.
Erreurs de parole sur transcription alignée (speech_transcript)
Annotez une transcription de parole alignée dans le temps, segment par segment, pour les erreurs d'ASR/TTS et de qualité de parole (Speak & Improve, 2025). Chaque segment {start, end, text, speaker?} est une carte affichant son horodatage et son texte ; l'annotateur marque les erreurs (erreur ASR / artefact TTS / erreur de prononciation / disfluence) et peut saisir la transcription corrigée. C'est le complément au niveau du segment de la vue de prise de parole dans voice_interaction.
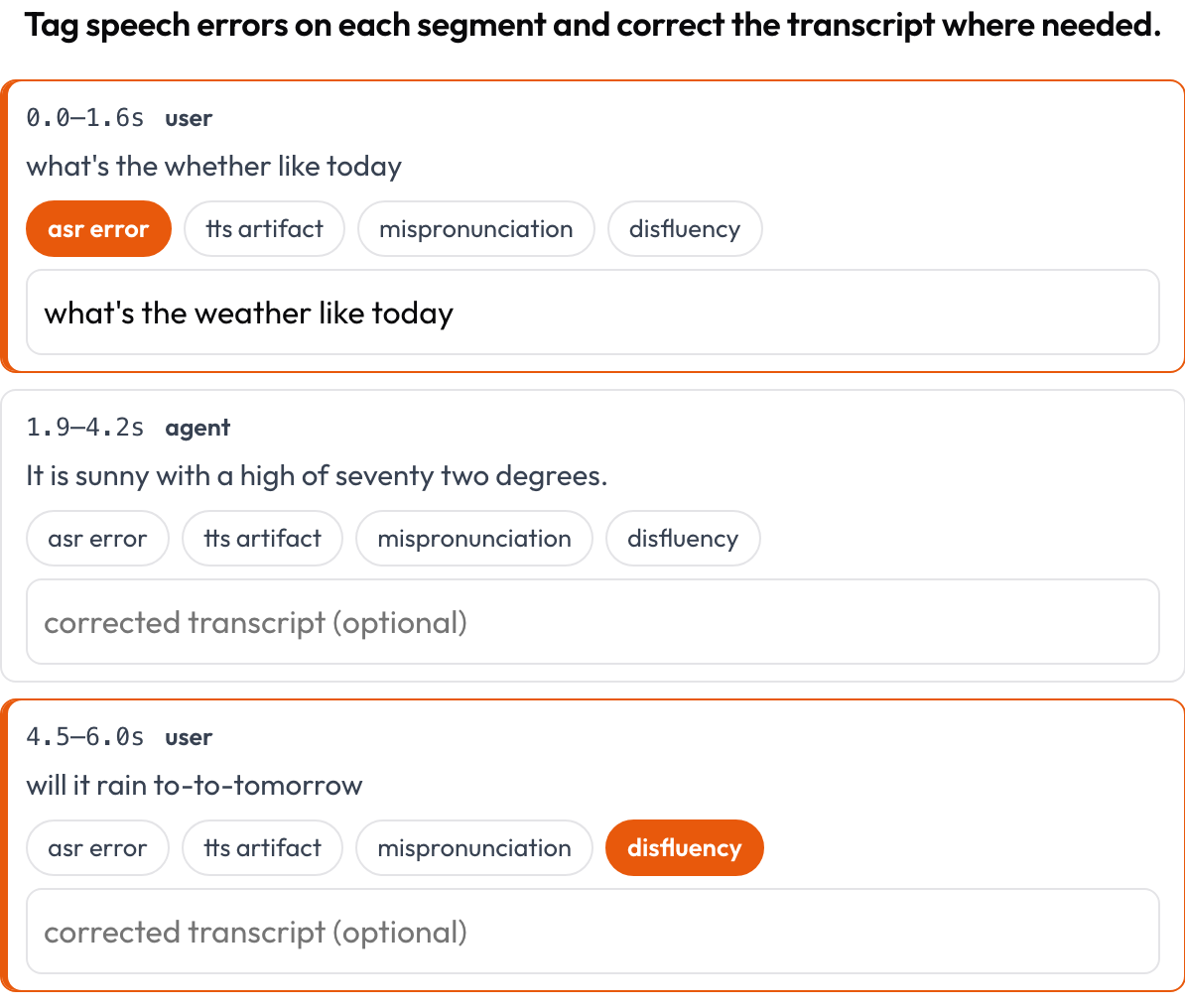 Marquez les erreurs d'ASR/TTS/prononciation par segment et corrigez la transcription en ligne
Marquez les erreurs d'ASR/TTS/prononciation par segment et corrigez la transcription en ligne
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments # list of {start, end, text, speaker?}
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true
# audio_key: audio # optional per-item audio URL to enable the playerStocké sous forme de liste de {index, start, end, errors, correction}.
Raisonnement multimodal entrelacé (multimodal_reasoning)
Évaluez une trace de raisonnement texte ↔ image ↔ outil ↔ action entrelacée, étape par étape (Multimodal RewardBench 2, 2025 ; Zebra-CoT). Chaque étape est un bloc typé, rendu en ligne selon son type ; l'annotateur juge la cohérence de chaque étape : le raisonnement découle-t-il de l'image et des étapes précédentes, ou le visuel est-il halluciné ?
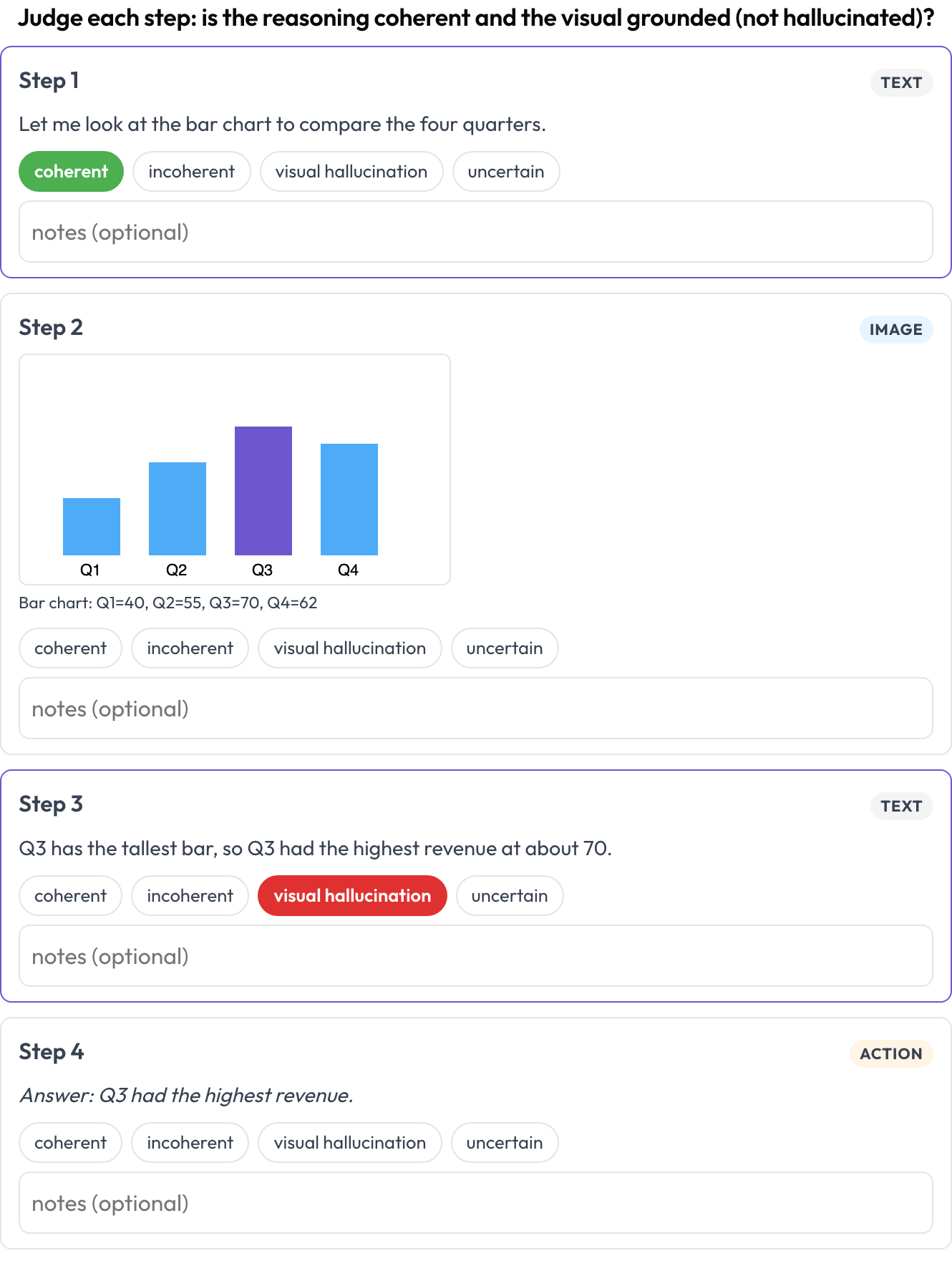 Évaluez chaque étape d'une trace de raisonnement texte-image-outil pour sa cohérence et son hallucination visuelle
Évaluez chaque étape d'une trace de raisonnement texte-image-outil pour sa cohérence et son hallucination visuelle
annotation_schemes:
- annotation_type: multimodal_reasoning
name: reasoning_review
description: "Judge each step: coherent reasoning and grounded visuals?"
steps_key: steps
type_key: type # each step's 'type': text | image | tool | action (inferred if absent)
verdict_options: [coherent, incoherent, visual_hallucination, uncertain]Chaque étape peut porter text/content, image/image_url (+caption), ou tool/args. Stocké sous forme de liste de {index, step, type, verdict, notes}.
Structure de grille de tableau (table_grid)
Annotez la structure des cellules d'une image de tableau, l'élément propre au document que de simples boîtes englobantes ne peuvent capturer (OmniDocBench, CVPR 2025 ; RealHiTBench). L'annotateur fixe les dimensions de la grille et clique sur les cellules pour marquer leur rôle (donnée / en-tête de colonne / en-tête de ligne / vide). Les boîtes de région par page sont déjà couvertes en exécutant l'annotation d'image par page, donc ce schéma se concentre sur la structure que ces boîtes ne peuvent exprimer.
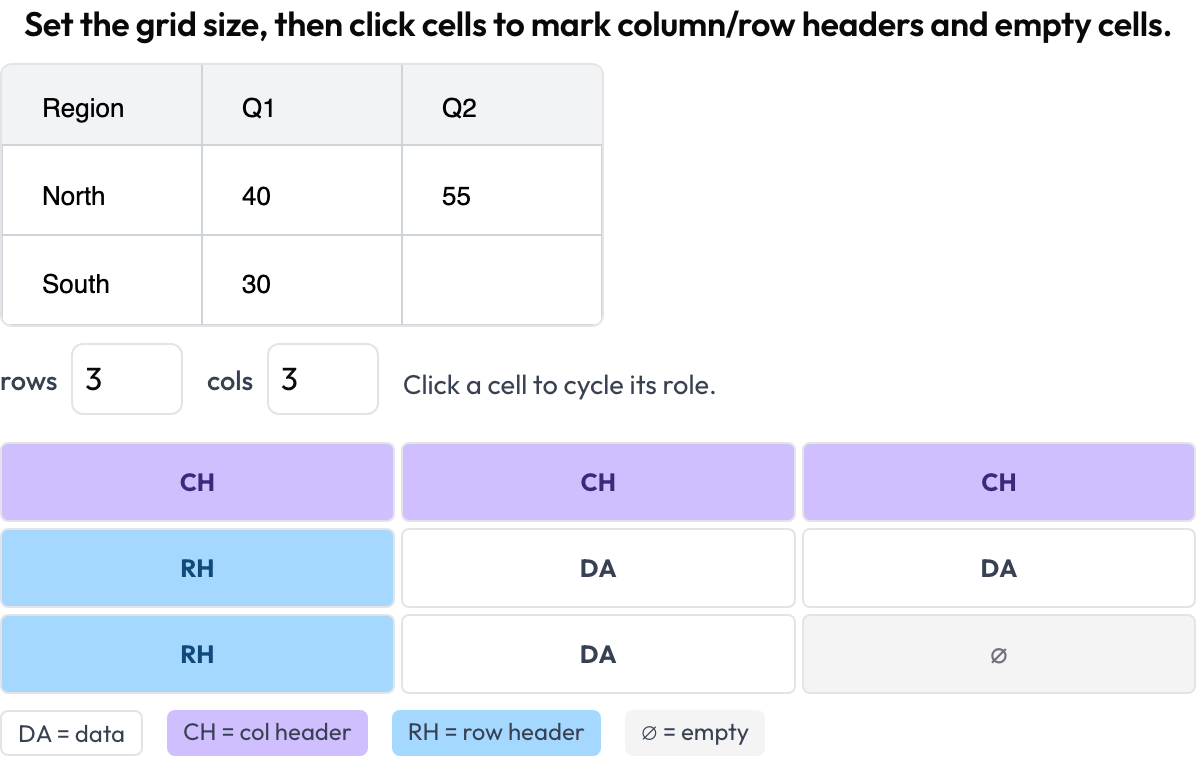 Annotez la structure des cellules d'un tableau documentaire : en-têtes de colonne et de ligne, données et cellules vides
Annotez la structure des cellules d'un tableau documentaire : en-têtes de colonne et de ligne, données et cellules vides
annotation_schemes:
- annotation_type: table_grid
name: structure
description: "Set the grid size, then click cells to mark headers and empty cells."
image_key: image # per-instance table image URL / data-URI
rows_key: rows # optional initial dims from the data
cols_key: cols
roles: [data, col_header, row_header, empty] # click cycles through theseStocké sous la forme {rows, cols, cells: {"r,c": role}}, en ne conservant que les cellules non data.
Voir aussi
- Évaluation d'équipes multi-agents — graphe d'interaction, passations et fiches de score d'équipe
- Évaluation des agents web — agents web à captures d'écran et actions
- Comment évaluer les agents d'IA — les niveaux d'évaluation des agents
- Annotation agentique — configuration de l'affichage des traces et ingestion
Pour les détails d'implémentation, voir la documentation source.