Alignement juge ↔ humain
Mesurez à quel point un juge LLM s'accorde avec vos étiquettes de référence humaines. Potato exécute le juge sur les instances annotées, calcule le kappa de Cohen, une matrice de confusion et une liste de désaccords, et suit l'accord à mesure que vous affinez la grille.
L'alignement du juge mesure et ajuste à quel point un juge LLM s'accorde avec vos étiquettes de référence humaines. Potato exécute un LLM-as-a-judge configurable sur les instances que vos annotateurs ont déjà étiquetées, calcule le κ de Cohen, une matrice de confusion et une liste de désaccords, et suit κ à mesure que vous modifiez la grille du juge. Avec le mode en ligne activé, le verdict du juge apparaît à côté de l'étiquette humaine pendant l'annotation, accompagné d'un κ en temps réel.
C'est la boucle standard « alignez votre juge sur environ 100 à 200 étiquettes de référence » utilisée par des outils comme LangSmith Align Evals et Evidently : collectez les étiquettes humaines, exécutez le juge, inspectez les désaccords, affinez la grille, puis relancez jusqu'à ce que l'accord soit élevé.
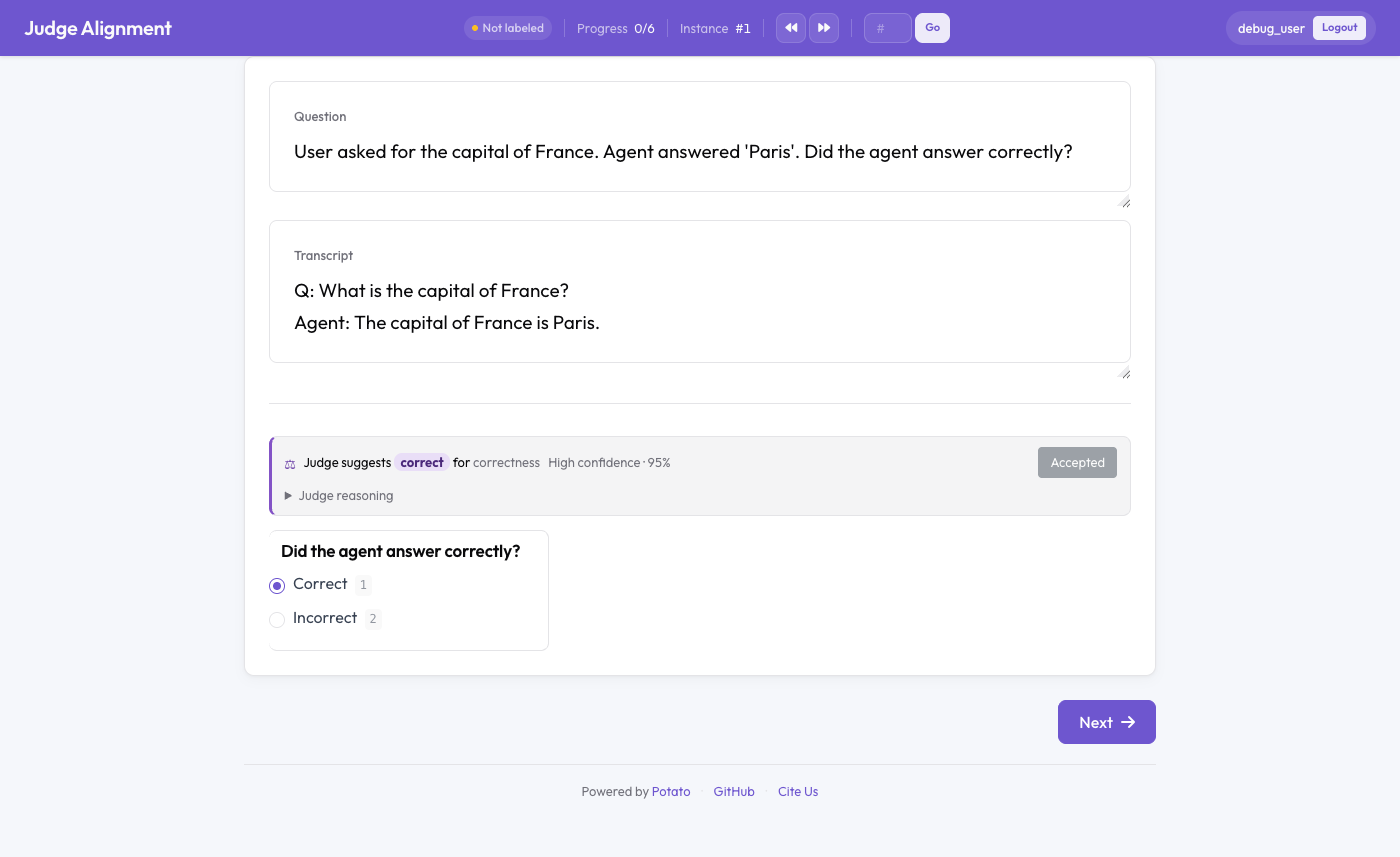 Verdict d'un juge LLM affiché à côté de l'annotation humaine avec un kappa en temps réel
Verdict d'un juge LLM affiché à côté de l'annotation humaine avec un kappa en temps réel
Configuration
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict existsLe périmètre couvre les schémas catégoriels à choix unique (radio, select, likert). Si judge_alignment.schemas est défini, seuls ces schémas sont jugés ; sinon, tous les schémas catégoriels le sont.
Exécuter le juge
Exécutez le juge depuis l'API d'administration. Les prédictions sont mises en cache par version de prompt, si bien que les réexécutions sont peu coûteuses :
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Pour calibrer, passez une grille modifiée. Cela crée une nouvelle version du prompt, ce qui vous permet de comparer κ d'un tour à l'autre :
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'Le rapport d'alignement
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
Envoyez l'en-tête X-API-Key. Pour chaque schéma, le rapport affiche :
- Le κ de Cohen avec une interprétation Landis–Koch, le taux d'accord et le nombre d'instances comparées.
- Une matrice de confusion (les lignes sont la référence humaine, les colonnes le juge).
- Une table des désaccords avec l'instance, l'étiquette humaine, l'étiquette du juge, la confiance et le raisonnement du juge.
- L'historique des versions du prompt avec le κ moyen par version, de sorte que la progression de la calibration soit visible.
La référence humaine est le vote majoritaire des annotateurs pour chaque instance.
Mode en ligne
Avec inline.enabled, chaque page d'annotation affiche le verdict du juge mis en cache pour l'instance — son étiquette, sa confiance et son raisonnement déployable — aux côtés d'un κ en temps réel pour la tâche. « Accepter » remplit le choix correspondant. Chaque sauvegarde humaine enregistre une comparaison humain↔juge qui alimente l'accord en temps réel. Réglez compute_on_demand: true pour appeler le juge en direct lorsqu'aucun verdict en cache n'existe ; sinon, exécutez le lot à l'avance, ce qui est plus rapide.
Notes et limites
- Dans cette version, la calibration est manuelle : modifiez la grille et relancez. L'optimisation automatique du prompt sort du périmètre.
- Le périmètre couvre les schémas catégoriels à choix unique. Le jugement des segments (span) et du texte libre est un travail futur.
- Exécutez le juge sur un ensemble de référence ciblé d'environ 100 à 200 instances étiquetées pour obtenir un κ stable.
Voir aussi
- Calibration des juges LLM — calibration multi-juges et à l'aveugle des humains avec erreur de calibration
- File de triage — orientez en priorité les éléments les plus informatifs vers les humains
- Guide de l'accord inter-annotateurs — les métriques kappa en détail
Pour les détails d'implémentation, consultez la documentation source.