Évaluation d'équipes multi-agents
Annotez les systèmes multi-agents par structure d'équipe, et non par une transcription à plat. Potato ajoute un graphe d'interaction des agents cliquable, l'attribution des échecs entre agents, l'examen des passations, des fiches de score par agent et par équipe, une chronologie de contention des outils et le marquage des comportements émergents.
Un système multi-agents échoue différemment d'un agent unique : la défaillance survient entre les agents, lors d'une passation, ou dans la façon dont l'équipe a été organisée. L'évaluer signifie attribuer les résultats à un agent, à une étape et à une passation précis, et non simplement noter une transcription à plat. Potato ajoute un ensemble de surfaces d'annotation conçues pour cela : un graphe d'interaction cliquable, l'attribution des échecs, l'examen des passations, des fiches de score par agent et par équipe, une chronologie de contention des outils et le marquage des comportements émergents entre couloirs.
Celles-ci s'appuient sur la vue de trace d'agent et la taxonomie d'échecs MAST. Chaque schéma dérive ses agents, ses étapes et ses passations de la trace elle-même au moment du rendu, de sorte que l'annotateur choisit parmi ce qui s'est réellement passé pendant l'exécution.
Graphe d'interaction (agent_interaction_graph)
L'exécution entière est rendue sous forme de graphe orienté : les nœuds sont les agents, les arêtes sont les transitions de messages et de passations entre eux (les arêtes plus épaisses signifient des transitions plus fréquentes), disposées automatiquement à partir de la trace. L'annotateur clique sur un nœud pour marquer le chemin critique et clique sur une arête pour la faire passer de normale → critique → problématique. C'est la réponse la plus claire à « comment voir la structure d'une exécution multi-agents », et c'est une surface que les outils d'annotation généralistes n'offrent pas.
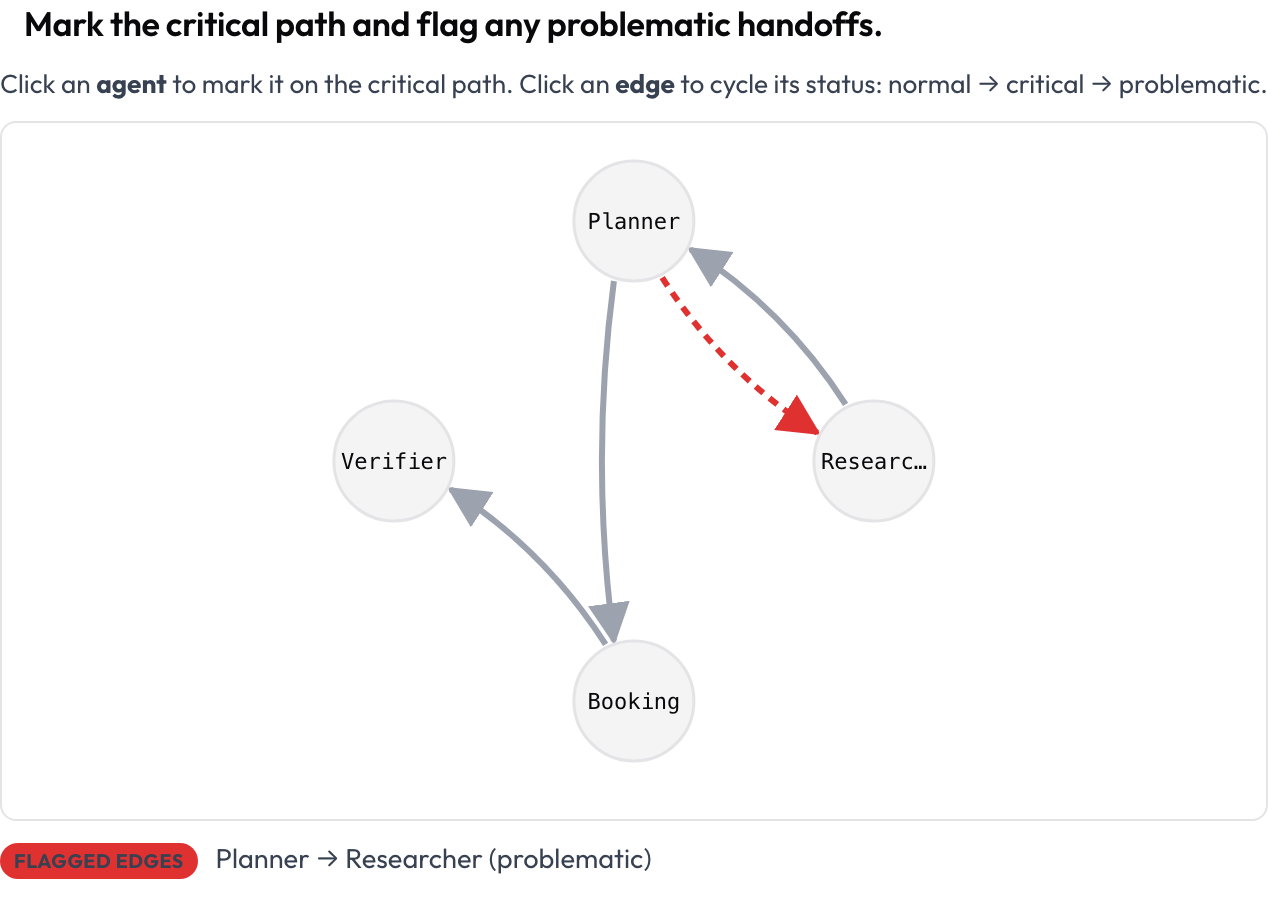 Marquez le chemin critique et signalez les passations problématiques sur un graphe d'interaction des agents cliquable
Marquez le chemin critique et signalez les passations problématiques sur un graphe d'interaction des agents cliquable
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentStocké sous la forme {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}. Chaque nœud et chaque arête peut recevoir le focus au clavier et un résumé textuel en direct liste les nœuds critiques et les arêtes signalées, de sorte que le sens n'est jamais porté par la couleur seule.
Attribution des échecs entre agents (failure_attribution)
Lorsqu'une équipe échoue, l'étiquette utile est le triplet (agent responsable, étape décisive, raison) issu de la littérature sur l'attribution des échecs (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, le jeu de données Who&When). La liste déroulante des agents et le sélecteur d'étapes sont renseignés à partir des tours de la trace elle-même, de sorte que l'annotateur attribue l'échec à un agent réel et à une étape réelle.
 Attribuez un échec multi-agents à l'agent responsable, à l'étape décisive et à la raison
Attribuez un échec multi-agents à l'agent responsable, à l'étape décisive et à la raison
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the traceStocké sous la forme {"responsible_agent", "decisive_step", "reason"}. Associez-le à un schéma radio de résultat (réussite/échec) pour que l'attribution ne se déclenche que sur les exécutions ayant échoué.
Examen des passations (handoff_review)
Chaque passation, un agent transmettant le contrôle à un autre, devient un objet à part entière à annoter. Partout où l'agent en action change entre deux tours consécutifs, Potato émet une carte de passation A → B ; l'annotateur signale les désalignements entre agents et évalue la qualité de la passation. Les modes d'échec sont ancrés dans la catégorie inter-agents de MAST et le phénomène d'« écho » (Zhang et al., 2025).
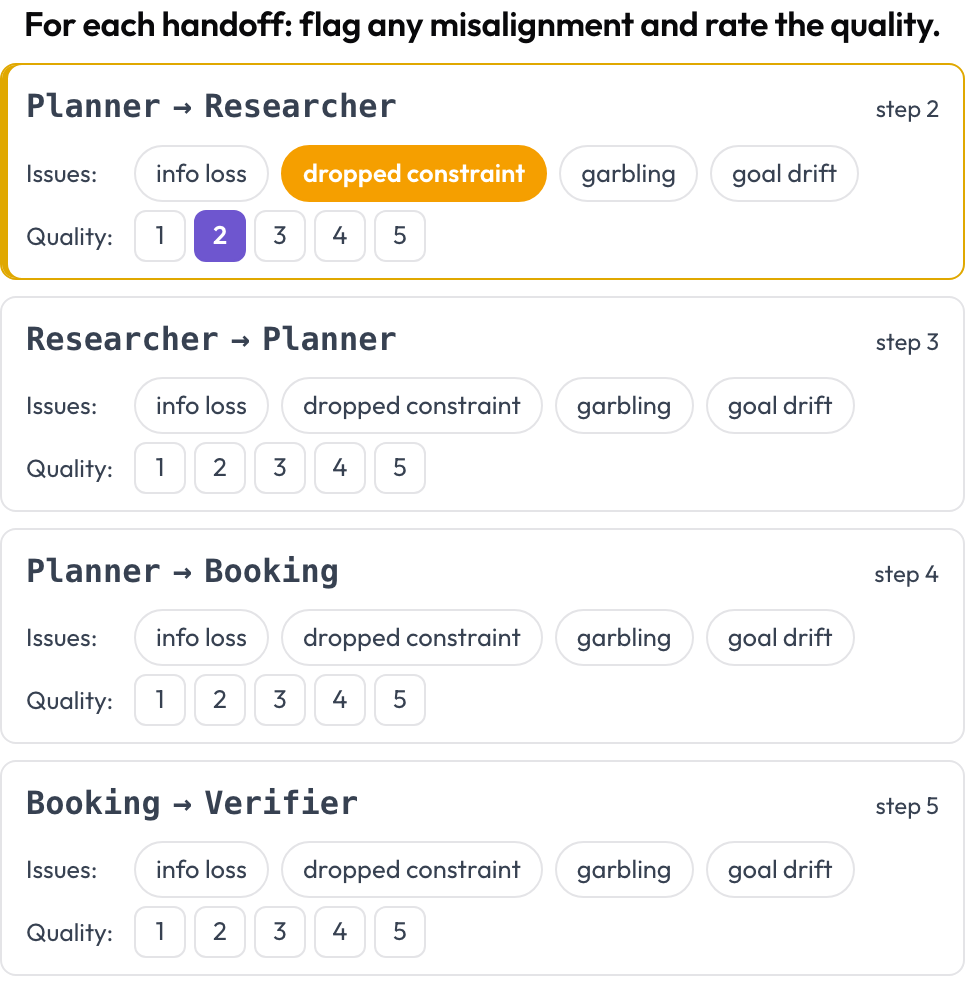 Signalez les désalignements entre agents à chaque passation et évaluez sa qualité
Signalez les désalignements entre agents à chaque passation et évaluez sa qualité
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Les passations sont dérivées de la trace au moment du rendu, il n'y a donc aucune configuration manuelle. Stocké sous forme de liste de {index, step, from, to, flags, quality}.
Fiche de score par agent et par équipe (agent_scorecard)
Notez une exécution sur deux niveaux à la fois (MultiAgentBench, Zhou et al., ACL 2025) : chaque agent reçoit des scores par dimension (fidélité au rôle, contribution, coordination), l'équipe reçoit des scores sur des dimensions partagées, et des jalons facultatifs sont cochés. Les lignes des agents proviennent des tours de la trace elle-même, de sorte que la matrice correspond à qui a réellement participé.
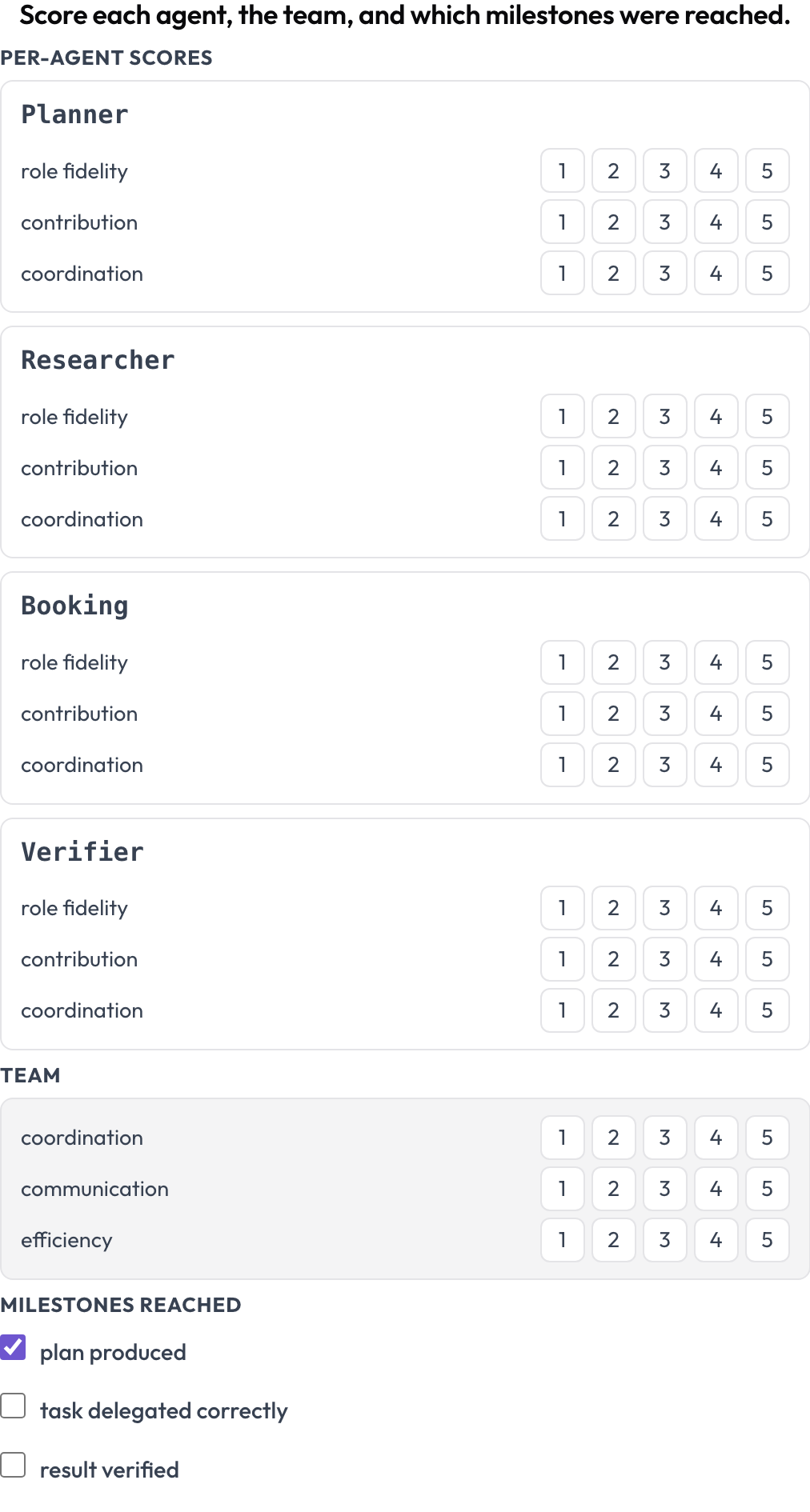 Notez chaque agent sur la fidélité au rôle, la contribution et la coordination, plus l'équipe et les jalons
Notez chaque agent sur la fidélité au rôle, la contribution et la coordination, plus l'équipe et les jalons
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optionalStocké sous la forme {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}.
Chronologie de contention des outils / ressources (tool_contention)
L'usage concurrent d'outils et de ressources entre agents est rendu sur une chronologie multi-couloirs, un couloir par agent. Les régions où deux appels touchent la même ressource sur des plages temporelles qui se chevauchent sont mises en évidence à travers les couloirs et listées pour classification : interblocage, attente circulaire, condition de concurrence ou bénigne (DPBench, 2026). C'est ainsi que vous détectez les défaillances de concurrence qu'une transcription par tour masque.
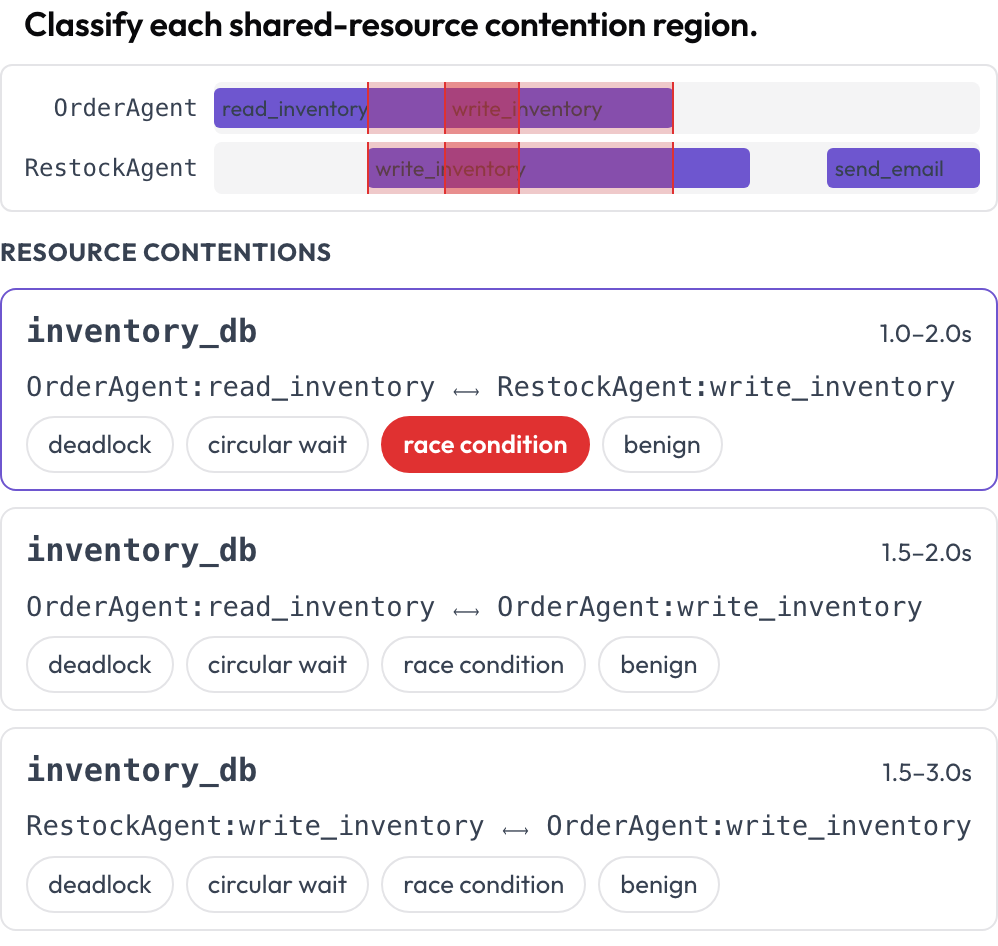 Repérez les interblocages et les conditions de concurrence sur une chronologie des appels d'outils par agent
Repérez les interblocages et les conditions de concurrence sur une chronologie des appels d'outils par agent
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]Les régions de contention sont calculées au moment du rendu (même resource, intervalle qui se chevauche). Stocké sous la forme {"contentions": {idx: label}}.
Comportement émergent entre couloirs (emergent_behavior)
Certains échecs sont collectifs : collusion, pensée de groupe, erreurs en cascade, dérive de rôle. Un comportement émergent n'est pas un span de texte contigu ; c'est un ensemble de tours participants, éventuellement issus d'agents différents. Pour chaque comportement, l'annotateur coche les tours qui y participent et ajoute une note, un span entre couloirs exprimé sous forme d'ensemble de tours.
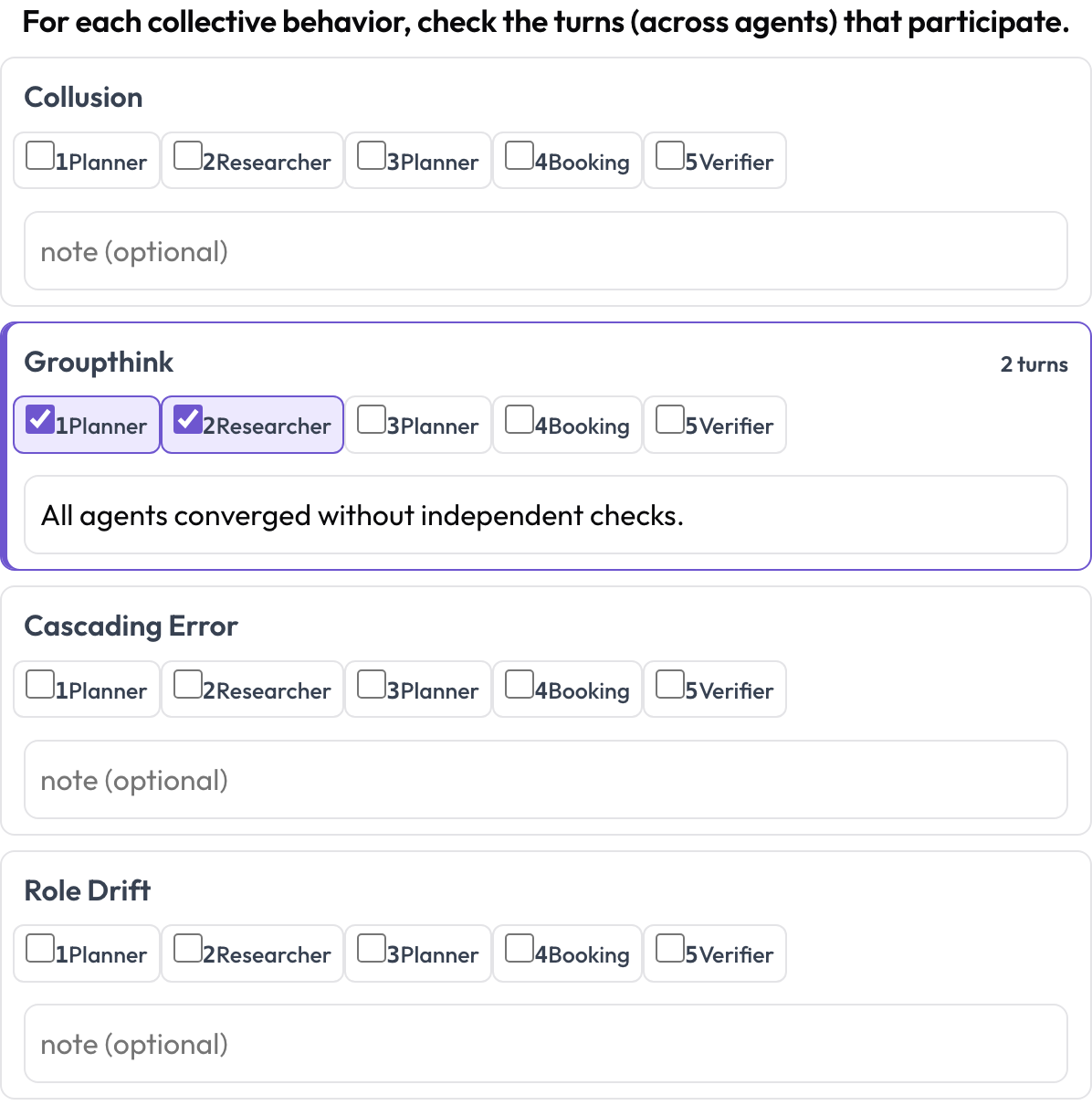 Marquez la collusion, la pensée de groupe et les erreurs en cascade à travers les agents et les tours
Marquez la collusion, la pensée de groupe et les erreurs en cascade à travers les agents et les tours
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueStocké sous la forme {behavior: {turns: [idx...], note}}, en ne conservant que les comportements non vides.
Examen des appels d'outils (tool_call_review)
Jugez chaque appel d'outil ou de fonction individuellement : le bon outil a-t-il été choisi, les arguments étaient-ils corrects, l'ordre était-il correct (à l'image de BFCL v4 / MCPMark) ? Les appels d'outils sont extraits des étapes de la trace au moment du rendu ; les champs tool_calls, tool_call ou action de chaque étape deviennent une carte avec le nom de l'outil et les arguments mis en forme.
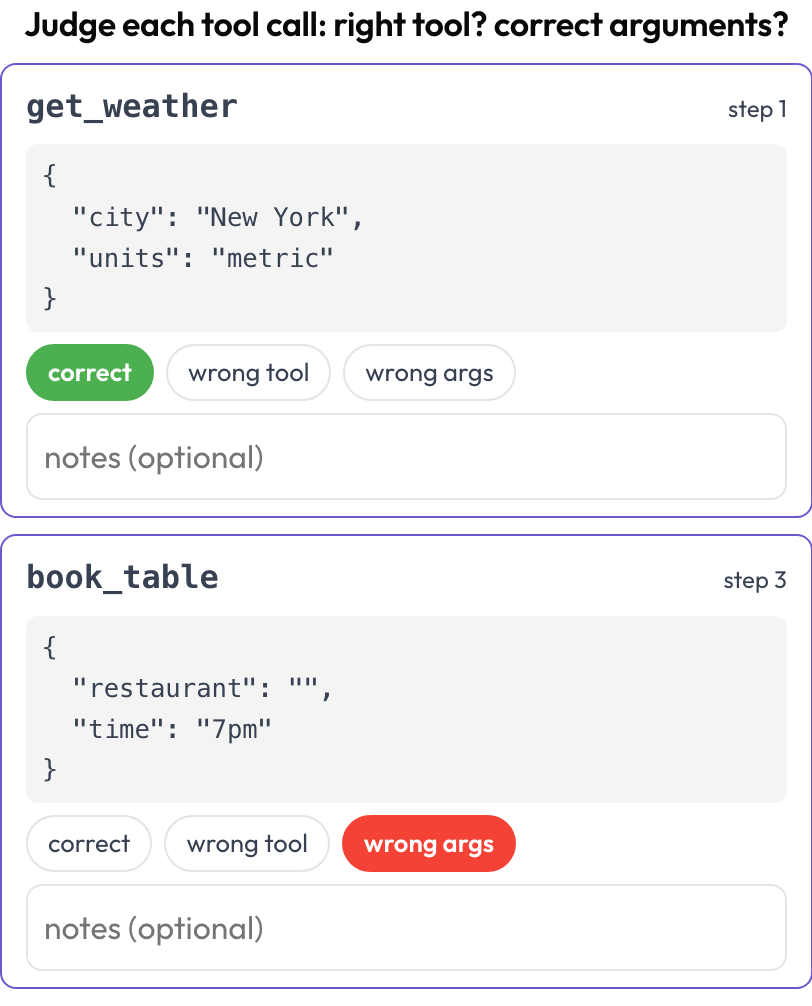 Jugez chaque appel d'outil : bon outil, arguments corrects, bon ordre
Jugez chaque appel d'outil : bon outil, arguments corrects, bon ordre
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizableStocké sous forme de liste de {index, step, tool, verdict, notes}.
Marquage MAST à la granularité de l'étape
Vous n'avez pas besoin d'un nouveau schéma pour relier la taxonomie d'échecs MAST à 14 modes (Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025) à l'étape exacte (et donc à l'agent en action) où l'échec s'est produit. Configurez le schéma existant par étape trajectory_eval avec les modes MAST comme error_types, regroupés par les trois catégories MAST. Associez-le à failure_attribution et handoff_review pour une couverture complète.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]Choisir l'angle d'orchestration
L'architecture d'orchestration domine souvent le résultat d'une exécution, il vaut donc la peine de la capturer comme une étiquette à part entière. Aucun nouveau schéma n'est nécessaire : un radio confirme ou corrige le modèle de l'exécution, qui guide ensuite à la fois l'angle d'évaluation et la façon dont la trace est disposée (séquentiel → couloirs, hiérarchique → arbre, discussion de groupe → tableau).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueVoir aussi
- Évaluation des agents multimodaux — schémas pour les agents GUI, vocaux, vidéo et documentaires
- Annoter les trajectoires d'agents — annotation d'erreurs par étape
- Comment évaluer les agents d'IA — les niveaux d'évaluation des agents
- Annotation agentique — configuration de l'affichage des traces et ingestion
Pour les détails d'implémentation, voir la documentation source.