Potato 2.6.2:一套完整的开源智能体评估工具
2.6.x 系列把 Potato 打造成一个完整、免费的智能体评估平台:支持从 OpenTelemetry、LangGraph、CrewAI 和 AutoGen 摄取轨迹,支持带可点击交互图的多智能体团队标注,支持面向 GUI、语音和视频的多模态智能体方案,外加模型竞技场、CI 门禁和数据筛选。
Potato 2.6 带来了智能体评估的第一波能力:LLM 作为评判者的校准、用于训练数据的轨迹编辑,以及三栏式的 eval_trace 展示。此后的 2.6.x 小版本补齐了其余部分。到 2.6.2 为止,Potato 已是一个完整的智能体评估平台:你可以从自己的智能体捕获轨迹,标注单个智能体、多智能体团队和多模态智能体,用你可以信赖的 LLM 来评判它们,在竞技场中给模型排名,并在 CI 中对发布设卡。这一切都用 YAML 配置,并始终运行在你自己的服务器上。
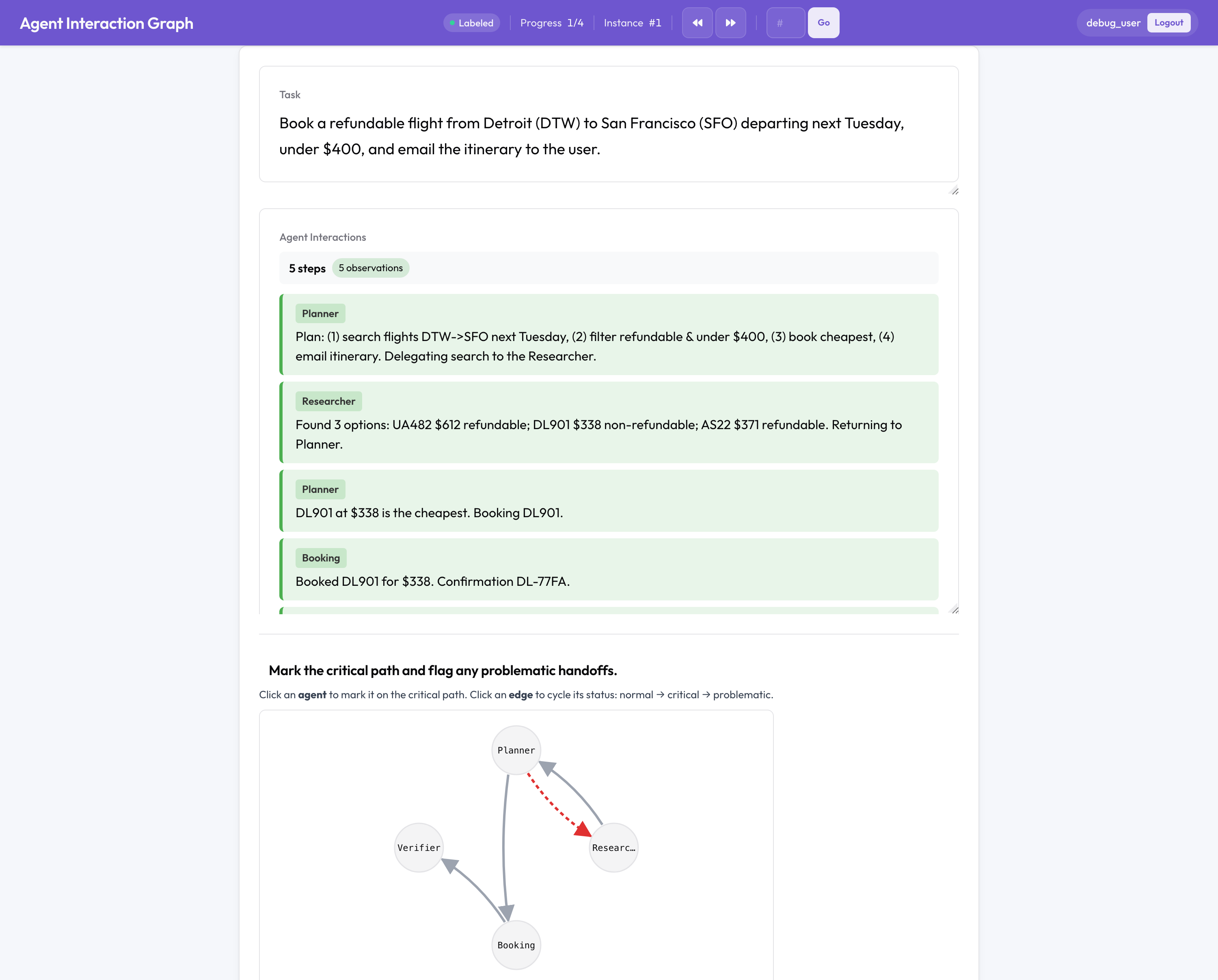 Potato 多智能体评估
Potato 多智能体评估
这些能力中,大多数都是人们如今要向托管平台付费才能获得的。Potato 免费提供,并且自托管。下面是 2.6.x 系列发布的全部内容。
 端到端的 2.6.x 智能体评估工具
端到端的 2.6.x 智能体评估工具
把轨迹接进来:一个捕获 SDK 与开放标准
评估始于真实的运行。新的 potato_trace SDK 可以为任何智能体埋点:用 @traceable 装饰一个函数(同步或异步),嵌套调用便会被捕获并发送到 Potato 的摄取端点,还可选择导出到 OpenTelemetry。Potato 同样能摄取 OpenTelemetry / OpenInference span,以及 LangGraph、CrewAI 和 AutoGen 的运行格式,因此你已经在用的框架产出的轨迹无需胶水代码就能进入标注队列。新轨迹可以通过 webhook、轮询器或被监视的目录到达,并在落地时就能分配给标注者。
看见整个团队:多智能体评估
这是没有开源对等物的部分。多智能体运行的失败方式与单个智能体不同:发生在智能体之间、在某次交接处、或在团队的组织方式里。所以 Potato 标注的是团队结构,而不是一份扁平的对话记录:
- 一张可点击的、由智能体与交接构成的交互图,你在上面标出关键路径并标记有问题的边。
- 失败归因:选出该负责的智能体、决定性的步骤和原因——即来自 Who&When 归因工作的(智能体、步骤、原因)三元组。
- 交接审查:每一次控制权转移都成为一张卡片,用来标记智能体间的不一致并给质量打分。
- 每个智能体与每个团队的记分卡:每个智能体的角色忠实度、贡献度和协作度,加上共享的团队维度与里程碑。
- 一条工具争用时间线,用来揭示多个智能体同时触碰同一资源时产生的死锁与竞态。
- 涌现行为标记,用于跨多个智能体与多个回合的共谋、群体思维和级联错误。
 失败归因:哪个智能体、哪一步、为什么
失败归因:哪个智能体、哪一步、为什么
包含各自 YAML 的完整集合见 多智能体团队评估,深入解析 调试多智能体失败 会逐一走完每个界面。指南 如何评估多智能体系统 讲解了何时该用哪一种。
超越文本:多模态智能体评估
智能体如今会操作 GUI、观看视频、进行口语对话,而每一种都需要文本控件无法提供的审查界面:
- GUI / 计算机操作轨迹:每一步的截图与动作、一个动作裁定,以及一个点击落点标记,用来显示点击是否落在了正确的元素上。
- 全双工语音时间线:一条双轨用户/智能体时间线,带打断检测与轮流发言评分。
- 视频时间定位:标出黄金事件区间,并对模型预测区间实时计算 IoU。
- 语音转写错误标记、带视觉幻觉标记的交错多模态推理,以及文档表格网格结构。
 计算机操作审查:动作正确性加上点击落点
计算机操作审查:动作正确性加上点击落点
两篇深入解析会逐一讲解这些内容:评估计算机操作智能体 针对 GUI 和操作系统智能体,评估语音与视频智能体 针对口语、视频和文档智能体。参考文档是 多模态智能体评估,指南是 评估计算机操作与多模态智能体。
你可以信赖的评判者,以及一个竞技场
用 LLM 给输出打分早已是家常便饭;2.6.x 的工作在于搞清楚能信它到什么程度。评判者校准 让人在不知模型标签的情况下盲标一遍,并报告准确率、kappa 和期望校准误差(ECE)。评判者对齐 针对你的黄金标签来调一个评判者。而程序化评估器 无需服务器运行即可自动给轨迹和文本打分(轨迹匹配、工具使用正确性、无参照的 LLM 作为评判者,以及启发式规则)。
要做正面对决,模型竞技场 把同一个提示发给多个模型,收集偏好,并在 OpenAI、Anthropic、Gemini、Ollama 和 vLLM 之间构建一张胜率排行榜。
把评估当软件来对待
这些运维部件让评估可重复:
- 数据集与实验:带版本的评估集、切分,以及带回归差值的并排实验对比。
- CI 评估:一个 pytest 插件,当某次提示或模型改动让智能体质量回退超过阈值时让构建失败。
- 自动化规则:按规则把进入的生产轨迹路由到数据集、评估器或标注队列。
- 语义筛选:一个嵌入索引,用于“找出和这次失败相似的轨迹”,以及可保存的动态切片。
如何获取
pip install --upgrade potato-annotation每个新界面都在 examples/agent-traces/ 下附带一个可运行示例,包括 interaction-graph/、failure-attribution/、gui-trajectory/ 和 temporal-grounding/。让 Potato 指向其中之一,就能看到方案运行起来:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000如果你在权衡工具选型,Potato 对比 LangSmith 与 Langfuse 中的对照,以及指南 开源标注工具对比,都梳理了各自适合的场景。欢迎在 GitHub 仓库 提出问题以及我们应当支持的轨迹格式。