调试多智能体失败:一次实战演练
如何用 Potato 找出一个多智能体 LLM 系统失败的原因:交互图、失败归因、交接审查、每个智能体的记分卡、工具争用时间线和涌现行为标记。
当一个智能体团队失败时,难点不在于察觉到失败——而在于找出是哪个智能体在哪一步导致了它,以及真正的问题是不是两个各自表现都没问题的智能体之间一次糟糕的交接。这篇演练会按照你在一次出问题的运行上实际会用到的顺序,走完 Potato 为此打造的六个界面。 这里的一切都用 YAML 配置,并运行在你自己的服务器上;完整的方案参考见 多智能体团队评估。
一个 多智能体系统 是若干个角色各异的 LLM 智能体——一个规划者、一个编码者、一个审查者——彼此传递消息并交接控制权。关于这些系统为何会出问题的研究,即 MAST 分类法(Why Do Multi-Agent LLM Systems Fail?)发现,大多数失败都发生在智能体之间:某个约束在交接处被丢掉,一个团队从不核验自己的工作,多个智能体各说各话。一份扁平的聊天记录恰恰会把这些藏起来,因为出错的东西就活在两条消息之间的空隙里,而不在任何一条消息内部。
 失败发生在智能体之间、在交接处,而不在某一份记录内部
失败发生在智能体之间、在交接处,而不在某一份记录内部
我怎么看清一次多智能体运行的结构?
先从运行的形状入手,而不是文本。agent_interaction_graph 方案把整次运行渲染为一张有向图:节点是智能体,边是它们之间的交接,越粗的边表示流量越大。你点击一个节点把它标在关键路径上,点击一条边让它在正常、关键、有问题之间循环切换。
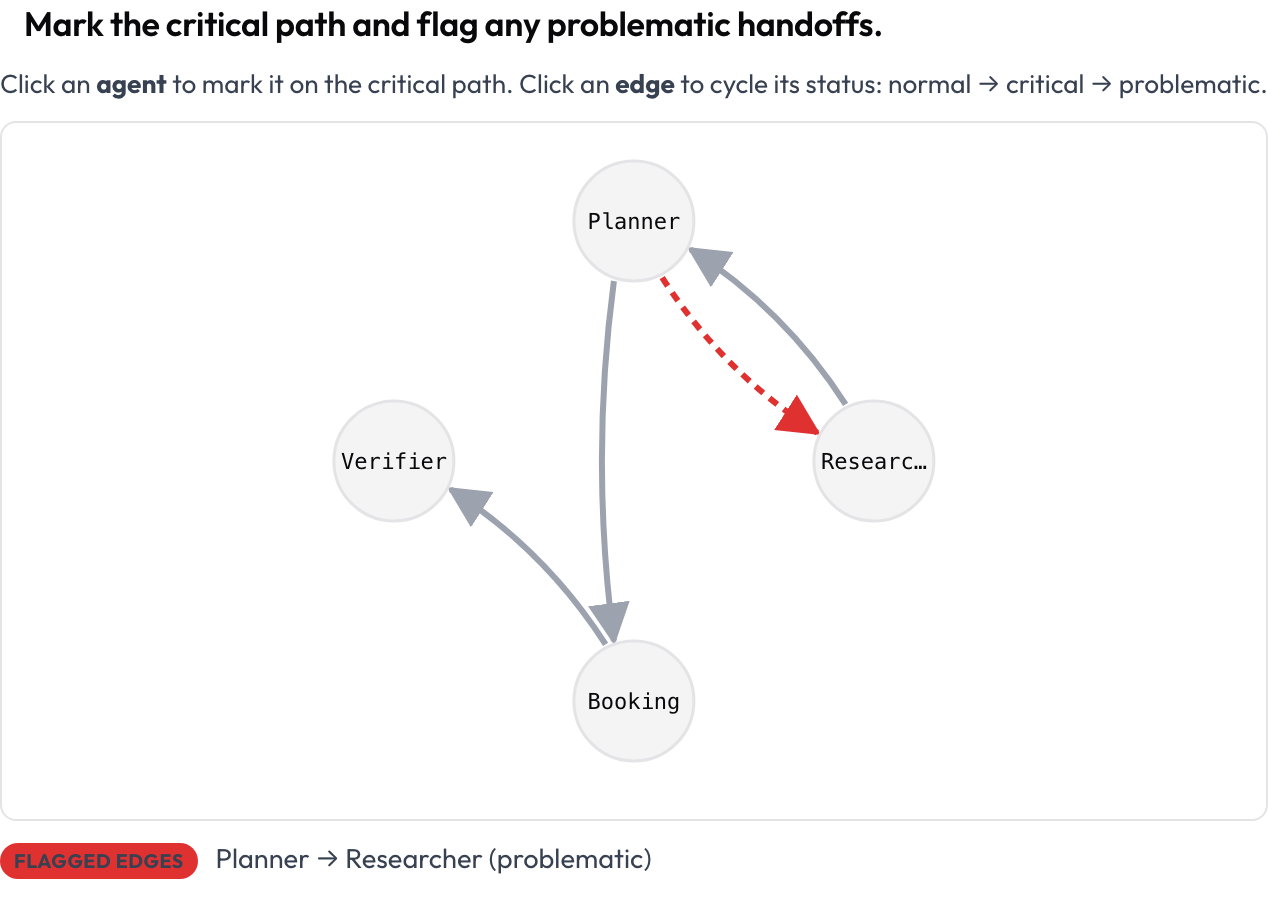 标出关键路径并标记有问题的交接
标出关键路径并标记有问题的交接
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agent这张图是根据轨迹自动布局的,所以你什么都不用画。每个节点和边都可用键盘聚焦,并有一段文字摘要列出关键节点和被标记的边,因此其含义从不只靠颜色来传达。这个视图是回答“谁和谁通信了,路径在哪里跑偏了”的最快方式。
我怎么把一次多智能体失败归因到某一个智能体?
一旦你能看清这次运行,就把失败钉死。failure_attribution 方案要求给出失败归因文献里的那个三元组(Zhang 等人,Which Agent Causes Task Failures and When?,ICML 2025,Who&When 数据集):该负责的智能体、决定性的步骤和原因。智能体下拉框和步骤选择器由轨迹自身的回合填充,所以你只能把失败归因到确实发生过的某个智能体和某一步。
 把失败归因到该负责的智能体、决定性的步骤以及原因
把失败归因到该负责的智能体、决定性的步骤以及原因
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent把归因和一个成功/失败的单选搭配起来,意味着这个三元组只在失败的运行上收集,这让标注者把时间花在带有信号的案例上。
那些交接本身呢?
归因点出一个决定性步骤。交接审查则看每一次控制权转移。只要执行的智能体在两个连续回合之间发生变化,Potato 就会发出一张交接卡片 A → B,你在这一遍里标记出错的地方——信息丢失、约束被丢、内容被搅乱、目标漂移——并给质量打分。这些失败模式来自 MAST 的智能体间类别和“回声”现象(Zhang 等人,2025)。
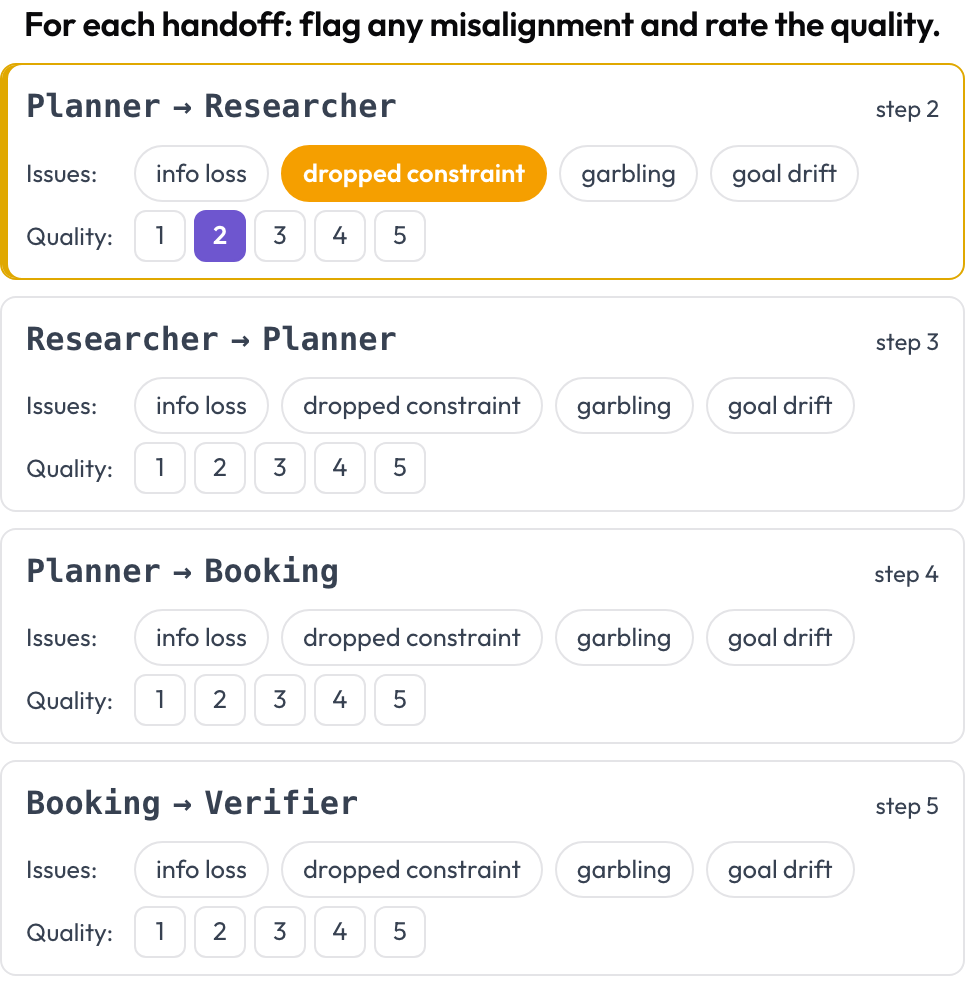 在每一次交接上标记智能体间的不一致并给其质量打分
在每一次交接上标记智能体间的不一致并给其质量打分
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5交接是在渲染时推导出来的,所以无需手动设置。“每个智能体看起来都没问题,团队却还是失败了”这类案例通常就在这里得到解答:约束在智能体 A 那里还活着,到智能体 B 那里就没了。
我怎么给智能体和团队打分?
一次失败告诉你某一次哪里坏了。一张记分卡则告诉你一个设计在多次运行中是否优秀。agent_scorecard 方案同时给两个层级打分(MultiAgentBench,Zhou 等人,ACL 2025):每个智能体的角色忠实度、贡献度和协作度,以及团队自身的共享维度,外加可选的里程碑。智能体的行来自轨迹,所以这张矩阵与实际参与者相吻合。
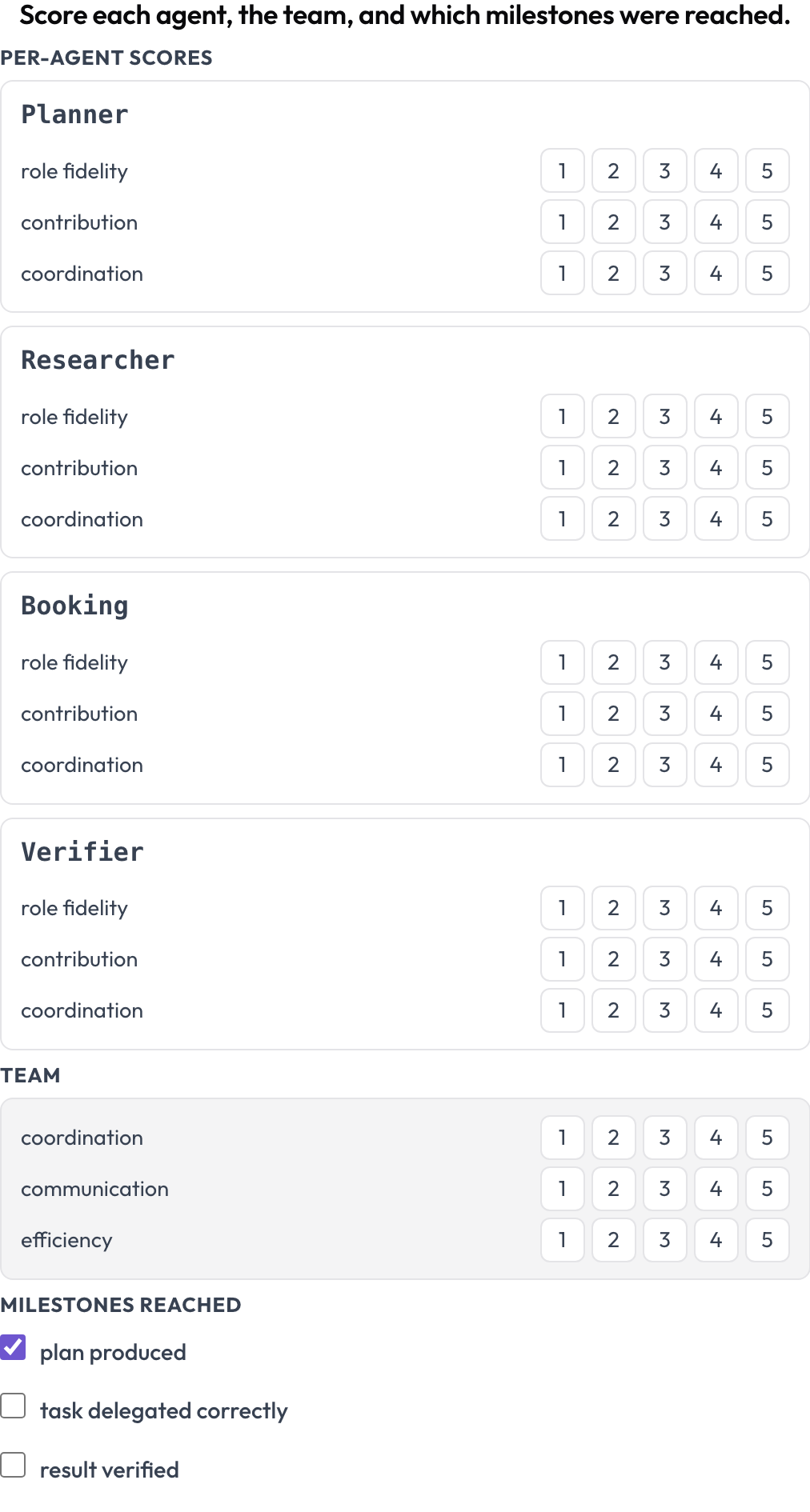 给每个智能体在角色忠实度、贡献度和协作度上打分,再加上团队
给每个智能体在角色忠实度、贡献度和协作度上打分,再加上团队
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]一个困在协作糟糕的团队里的强力智能体,会在这里表现为一行很高的智能体分数紧挨着很低的团队维度,而这正是你在同样任务上比较顺序式、层级式与群聊式编排时想要看到的那种模式。
那并发与集体性的失败呢?
还有两个界面能抓住逐回合阅读无法捕捉的失败。tool_contention 时间线把每个智能体放在各自的泳道上,并高亮两次调用在重叠时间里触碰同一资源的区域,你把它分类为死锁、循环等待、竞态条件或良性(DPBench,2026)。
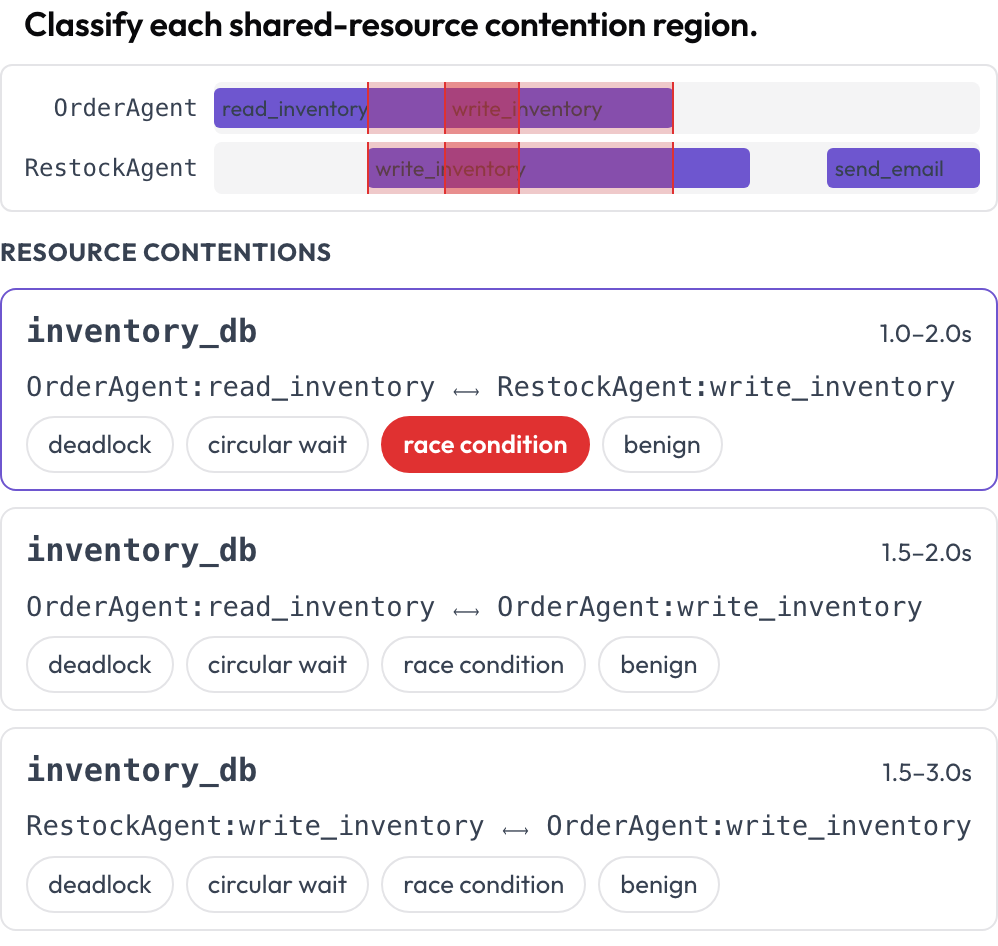 在每个智能体的工具调用时间线上发现死锁与竞态条件
在每个智能体的工具调用时间线上发现死锁与竞态条件
而 emergent_behavior 处理的是集体性而非定位于某一步的失败——共谋、群体思维、级联错误、角色漂移。一个涌现行为不是一段连续的跨度;它是一组参与的回合,可能来自不同的智能体,所以你勾选参与其中的回合并加上一条备注。
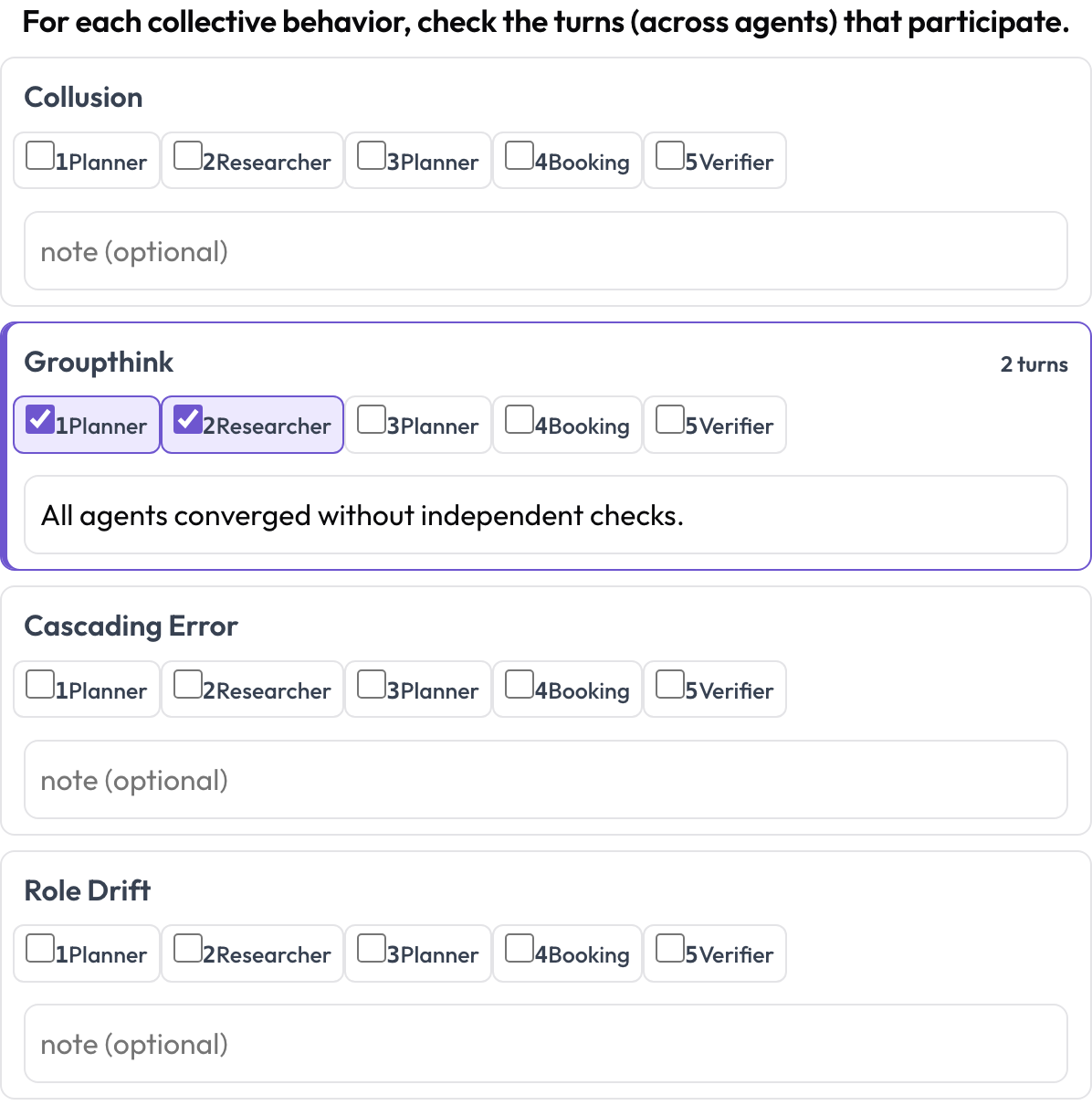 跨智能体与回合标记共谋、群体思维和级联错误
跨智能体与回合标记共谋、群体思维和级联错误
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: true把它们排成顺序
在一次真实的出问题的运行上,顺序通常是:读交互图看清形状,用失败归因点出决定性步骤,如果决定性步骤是一次转移就打开交接审查,当失败关乎时序或群体而非单个智能体时再去用争用时间线或涌现行为标记。当你在比较多个设计而不是调试某一次运行时,再用记分卡来打分。像对待任何主观标签那样去衡量归因上的一致性;参见 标注者间一致性。
延伸阅读
- 多智能体团队评估 — 完整的方案参考,含每个界面的 YAML
- 如何评估多智能体系统 — 何时该用哪种方法的决策指南
- Potato 2.6.2:一套完整的开源智能体评估工具 — 2.6.x 系列发布的全部内容
- 标注智能体轨迹 — 每一步的错误分类法,包括在步骤粒度上的 MAST 标记