Potato 2.6.2:完全なオープンソースのエージェント評価スイート
2.6.x 系列は Potato を完全かつ無償のエージェント評価プラットフォームへと進化させます:OpenTelemetry、LangGraph、CrewAI、AutoGen からのトレース取り込み、クリック可能な相互作用グラフを備えたマルチエージェントチーム注釈、GUI・音声・動画向けのマルチモーダルエージェントスキーマ、さらにモデルアリーナ、CI ゲーティング、キュレーションを備えます。
Potato 2.6 はエージェント評価の第一波をもたらしました:LLM-as-judge のキャリブレーション、学習データ向けのトラジェクトリ編集、そして 3 ペインの eval_trace 表示です。それ以降の 2.6.x ポイントリリースが残りの部分を埋めていきます。2.6.2 の時点で、Potato は完全なエージェント評価プラットフォームになりました:自分のエージェントからトレースを取得し、単一エージェント、マルチエージェントチーム、マルチモーダルエージェントを注釈し、信頼できる LLM でそれらを評価し、アリーナでモデルを順位付けし、CI でリリースをゲートできます。そのすべてが YAML で設定され、自分のサーバー上にとどまります。
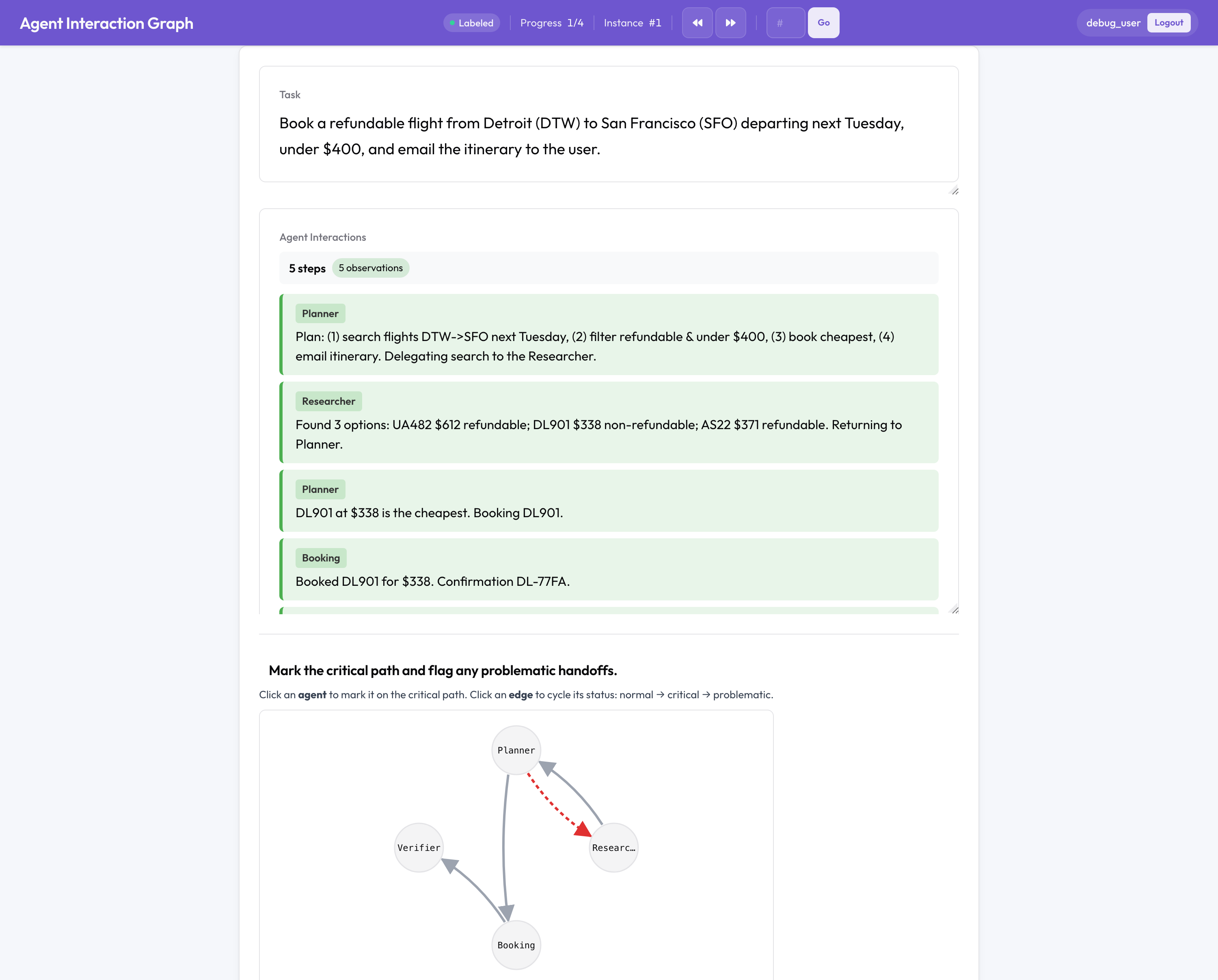 Potato のマルチエージェント評価
Potato のマルチエージェント評価
これらの大半は、現在ホスト型プラットフォームに料金を支払って得る機能です。Potato はそれらを無償かつセルフホストで提供します。以下が 2.6.x 系列で出荷された内容です。
 2.6.x のエージェント評価スイート、エンドツーエンド
2.6.x のエージェント評価スイート、エンドツーエンド
トレースを取り込む:キャプチャ SDK とオープン標準
評価は実際の実行から始まります。新しい potato_trace SDK は任意のエージェントを計装します:関数を @traceable(同期または非同期)でデコレートすると、ネストした呼び出しが捕捉され、Potato の取り込みエンドポイントに送信されます。オプションで OpenTelemetry エクスポートも可能です。Potato は OpenTelemetry / OpenInference スパンや、LangGraph、CrewAI、AutoGen の実行フォーマットも取り込むため、すでに使っているフレームワークからのトレースがグルーコードなしで注釈キューに届きます。新しいトレースは Webhook、ポーラー、または監視対象ディレクトリ経由で到着でき、届くとともに注釈者へ割り当て可能になります。
参考:トレーシング SDK、自動化ルール。
チーム全体を見る:マルチエージェント評価
これはオープンソースに同等品がない部分です。マルチエージェントの実行は単一エージェントとは異なる形で失敗します。エージェント間で、引き継ぎの場面で、チームの編成のされ方で失敗するため、Potato はフラットなトランスクリプトではなくチーム構造を注釈します:
- エージェントと引き継ぎのクリック可能な相互作用グラフ。クリティカルパスをマークし、問題のあるエッジにフラグを立てます。
- 失敗の帰属:責任を負うエージェント、決定的なステップ、理由を選びます。Who&When の帰属研究に由来する (agent, step, reason) の三つ組です。
- 引き継ぎレビュー:あらゆる制御の移譲がカードになり、エージェント間の不整合にフラグを立て、品質を評価できます。
- エージェント別・チーム別のスコアカード:エージェントごとの役割忠実度、貢献、協調に加え、共有のチーム次元とマイルストーン。
- 複数のエージェントが同じリソースに同時に触れるデッドロックや競合状態を表面化させるツール競合タイムライン。
- 複数のエージェントとターンにまたがる結託、グループシンク、連鎖的なエラーのための創発的振る舞いのタグ付け。
 失敗の帰属:どのエージェントが、どのステップで、なぜ
失敗の帰属:どのエージェントが、どのステップで、なぜ
それぞれの YAML を含む全機能は マルチエージェントチーム評価 にあり、深掘り記事 マルチエージェントの失敗をデバッグする が各サーフェスをエンドツーエンドで解説します。ガイド マルチエージェントシステムの評価方法 は、どの方法をいつ使うかを扱います。
テキストを超えて:マルチモーダルエージェント評価
エージェントは今や GUI を操作し、動画を視聴し、音声会話を行います。そのそれぞれが、テキストウィジェットでは提供できないレビューサーフェスを必要とします:
- GUI / コンピュータ操作トラジェクトリ:ステップごとのスクリーンショットとアクション、アクションの判定、そしてクリックが正しい要素に着地したかを示すクリックグラウンディングマーカー。
- 全二重音声タイムライン:ユーザー/エージェントのデュアルトラックタイムラインで、割り込み検出とターンテイキングのスコアリングを行います。
- 動画の時間的グラウンディング:ゴールのイベント区間をマークし、モデルの予測区間に対するライブな IoU を表示します。
- 音声トランスクリプトのエラータグ付け、視覚的ハルシネーションのフラグを備えたインターリーブされたマルチモーダル推論、そしてドキュメントの表グリッド構造。
 コンピュータ操作レビュー:アクションの正しさに加えてクリックグラウンディング
コンピュータ操作レビュー:アクションの正しさに加えてクリックグラウンディング
2 本の深掘り記事がこれらを解説します:GUI および OS エージェントを扱う コンピュータ操作エージェントの評価 と、音声・動画・ドキュメントエージェントを扱う 音声・動画エージェントの評価 です。リファレンスは マルチモーダルエージェント評価、ガイドは コンピュータ操作およびマルチモーダルエージェントの評価 です。
信頼できる評価者と、アリーナ
LLM を使って出力を採点することは日常的です。2.6.x の取り組みは、それをどこまで信頼してよいかを知ることに関するものです。評価者キャリブレーション は、モデルのラベルに対してブラインドの人手パスを実行し、正確度、kappa、期待キャリブレーション誤差を報告します。評価者アライメント は、単一の評価者をあなたのゴールドラベルに合わせて調整します。そして プログラム的評価器 は、サーバーを起動せずにトラジェクトリとテキストを自動採点します(トラジェクトリの一致、ツール利用の正しさ、参照不要の LLM-as-judge、ヒューリスティクス)。
直接対決の比較には、モデルアリーナ が 1 つのプロンプトを複数のモデルに送り、選好を収集し、OpenAI、Anthropic、Gemini、Ollama、vLLM にまたがる勝率リーダーボードを構築します。
評価をソフトウェアのように扱う
運用面の各機能が評価を再現可能にします:
- データセットと実験:バージョン管理された評価セット、分割、回帰デルタを伴う実験の並列比較。
- CI 評価:プロンプトやモデルの変更がエージェント品質を閾値を超えて悪化させたときにビルドを失敗させる pytest プラグイン。
- 自動化ルール:到着する本番トレースを、ルールに従ってデータセット、評価器、または注釈キューへ振り分けます。
- セマンティックキュレーション:「この失敗に似たトレースを探す」ための埋め込みインデックスと、保存された動的スライス。
入手方法
pip install --upgrade potato-annotation新しい各サーフェスは、examples/agent-traces/ の下に実行可能な例を出荷します。interaction-graph/、failure-attribution/、gui-trajectory/、temporal-grounding/ などです。そのいずれかを Potato に指定すると、スキーマが動作するのを確認できます:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000ツールを比較検討しているなら、Potato vs LangSmith・Langfuse の比較と、ガイド オープンソース注釈ツールの比較 が、それぞれがどこに適するかを示します。質問や、対応すべきトレースフォーマットについては GitHub リポジトリ でお寄せください。