音声・動画エージェントを評価する
Potato における音声、動画、ドキュメントエージェントの人手評価のウォークスルー:デュアルトラックタイムライン上でターンテイキングをスコアリングし、ライブな IoU で動画イベントをグラウンディングし、音声エラーをタグ付けし、表構造をマークする。
話し、動画を視聴し、ドキュメントを読むエージェントは、テキストボックスでは示せない形で失敗します。音声エージェントの誤りはターンの継ぎ目に存在し、動画エージェントの答えは文ではなく時間区間であり、ドキュメントエージェントの誤りは読み違えた表のセルです。これらのそれぞれが、モダリティに合わせて形作られたレビューサーフェスを必要とします。 Potato は、既存の 画像 および 音声 表示に加えて、そうしたサーフェスを 4 つ追加します。音声、動画、発話、ドキュメントです。完全なリファレンスは マルチモーダルエージェント評価 です。
 プレーンなテキストウィジェットでは、割り込み、イベント区間、表のセルを表現できない
プレーンなテキストウィジェットでは、割り込み、イベント区間、表のセルを表現できない
音声エージェントのターンテイキングを評価するには?
話すエージェントは境界で壊れます:ユーザーをさえぎる、かぶせて話す、または長く間を空けてユーザーがあきらめてしまう。voice_interaction スキーマは、会話をデュアルトラックタイムラインとして配置し(ユーザーのレーンとエージェントのレーン)、両者が同時に話す重なりの領域をハイライトします(Full-Duplex-Bench、2025)。各重なりを分類し、全体のターンテイキングを評価します。音声が提供されている場合はインラインで再生されます。
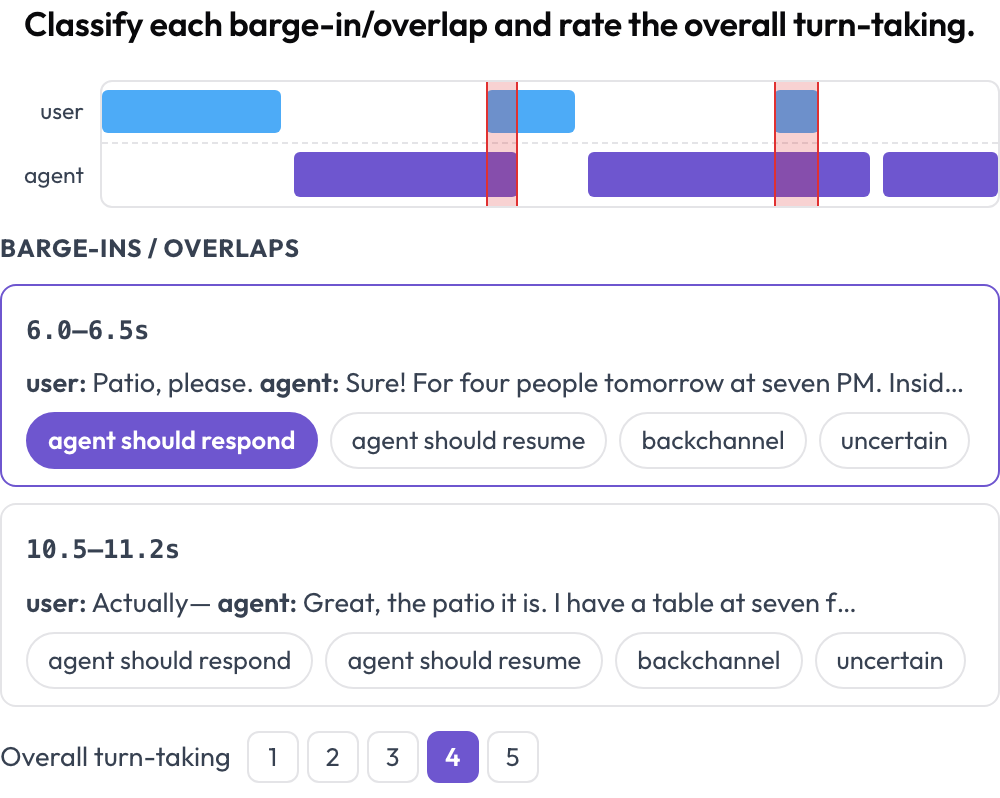 割り込み検出とターンテイキングのスコアリングを備えたデュアルトラック音声タイムライン
割り込み検出とターンテイキングのスコアリングを備えたデュアルトラック音声タイムライン
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5重なりはレンダリング時にターンのタイミングから計算されるため、フラットなトランスクリプトなら「両者が何かを言った」と平板化してしまう 全二重 会話が、具体的でラベル付け可能な瞬間の集合になります。
動画エージェントの時間的グラウンディングをスコアリングするには?
「ゴールはいつ起きるのか?」という問いに対する動画エージェントの答えは区間なので、区間としてスコアリングします。temporal_grounding スキーマは、各イベントプロンプトに対してゴールの [start, end] をマークできるスクラバーを提供します。再生ヘッドを捕捉するか、秒数を入力します。データがモデルの予測区間を持つ場合、ライブな IoU と 2 本バーのミニタイムラインが、調整するにつれて更新されます(TimeScope、2025)。
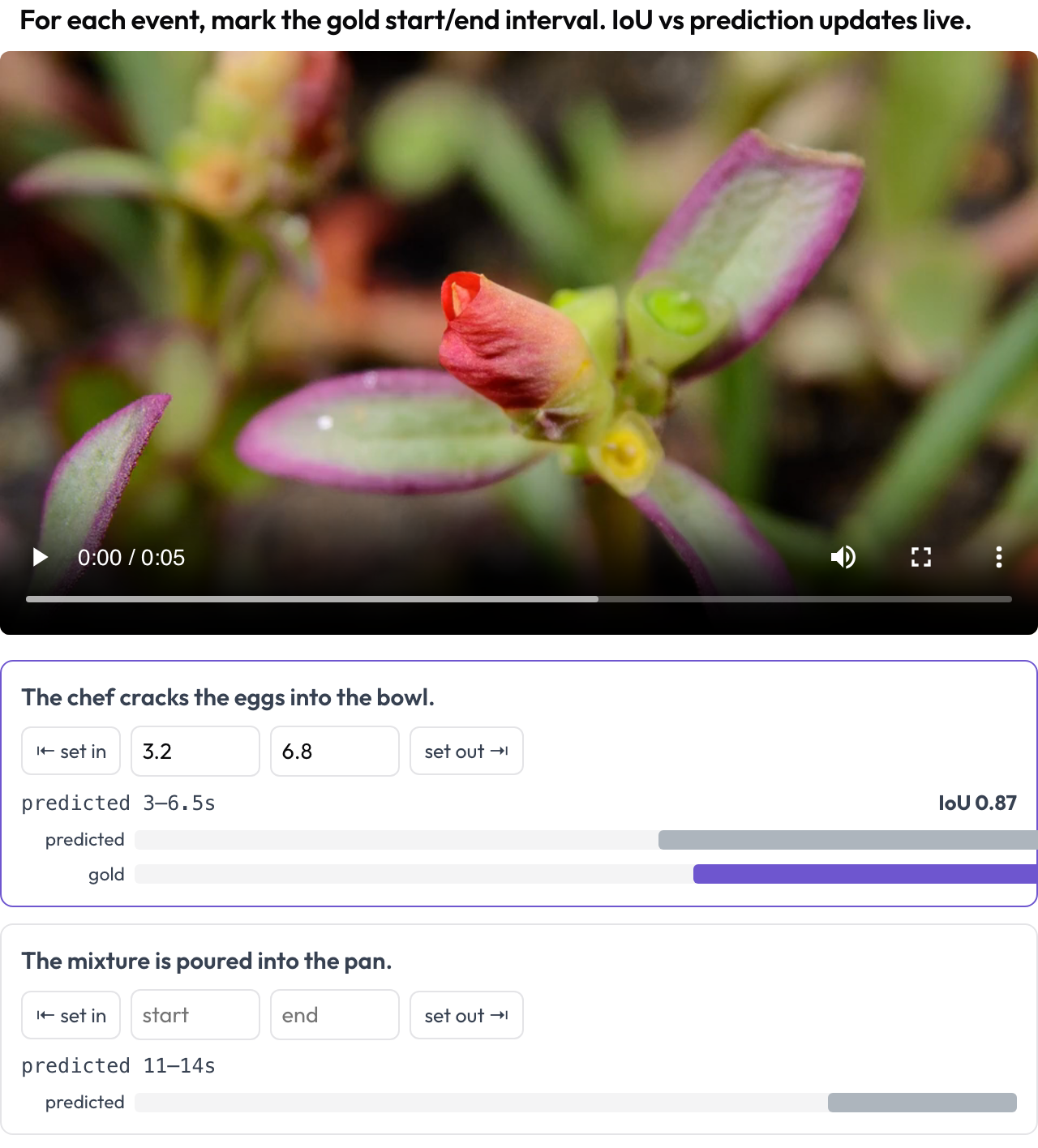 モデルの予測に対するライブな IoU とともに、動画上でゴールのイベント区間をマークする
モデルの予測に対するライブな IoU とともに、動画上でゴールのイベント区間をマークする
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsこれは予測対ゴールの局所化のために作られており、一般的なセグメントのラベル付けとは異なる仕事です:モデルのスパンが真実にどれだけ近いかをスコアリングしており、境界をドラッグするにつれて IoU が動くのを見ることで、それが即座に分かります。
音声トランスクリプト、推論、表はどうか?
さらに 3 つのサーフェスが、マルチモーダルの広がりの残りをカバーします:
- 音声トランスクリプト(
speech_transcript):時間整合された各セグメントがカードになります。ASR/TTS エラー、発音の誤り、非流暢さをタグ付けし、テキストをインラインで修正します(Speak & Improve、2025)。これはターンテイキングビューに対するセグメントレベルの補完です。 - インターリーブ推論(
multimodal_reasoning):テキスト・画像・ツールのトレースが型付きのブロックとして描画されます。各ステップの一貫性を評価し、推論が画像から導かれない視覚的ハルシネーションにフラグを立てます(Multimodal RewardBench 2、2025)。 - ドキュメントの表(
table_grid):グリッドの寸法を設定し、セルをクリックしてその役割をマークします。データ、列ヘッダー、行ヘッダー、空のいずれかで、バウンディングボックスでは捉えられない構造を捕捉します。
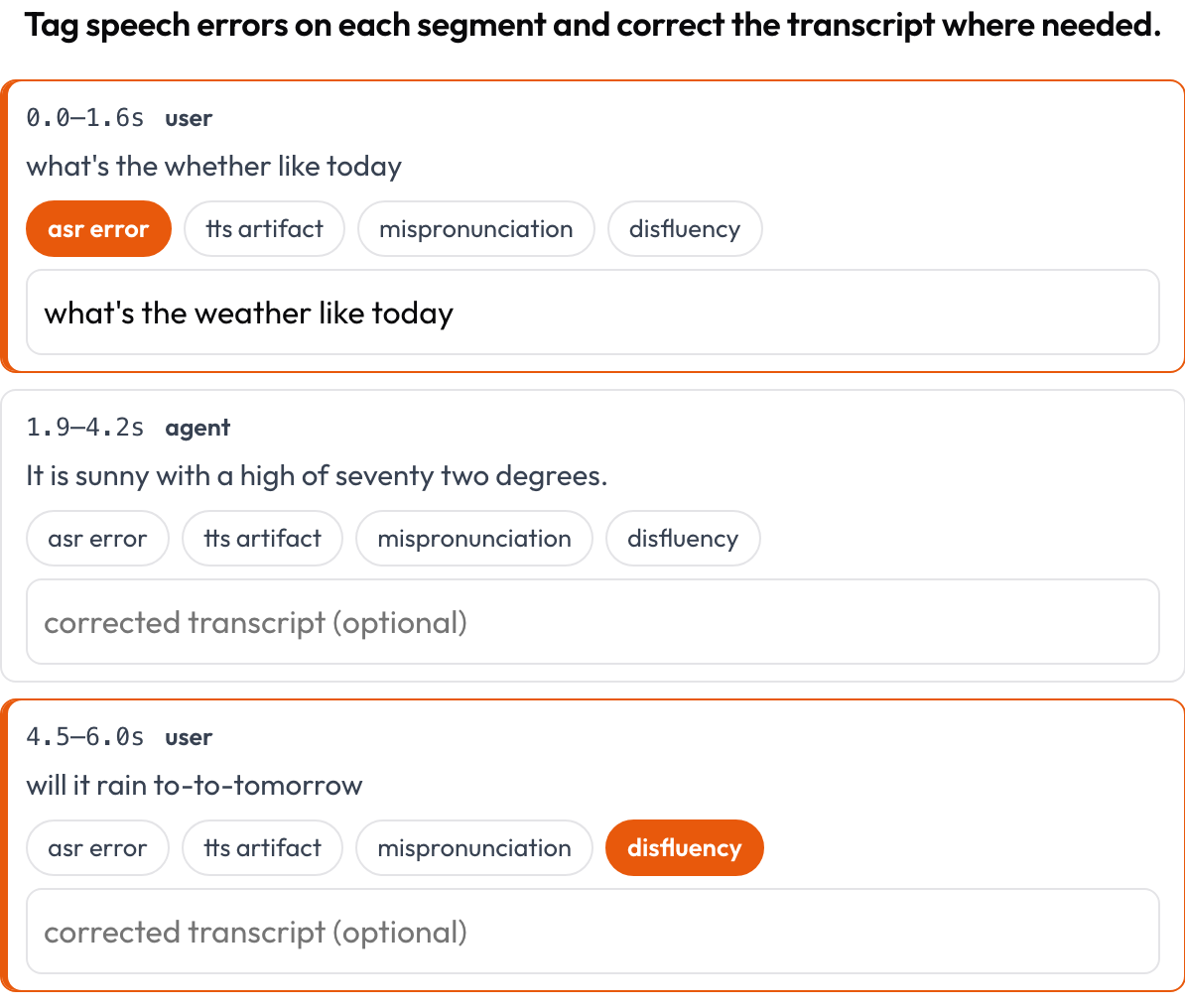 セグメントごとに ASR/TTS/発音エラーをタグ付けし、トランスクリプトをインラインで修正する
セグメントごとに ASR/TTS/発音エラーをタグ付けし、トランスクリプトをインラインで修正する
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true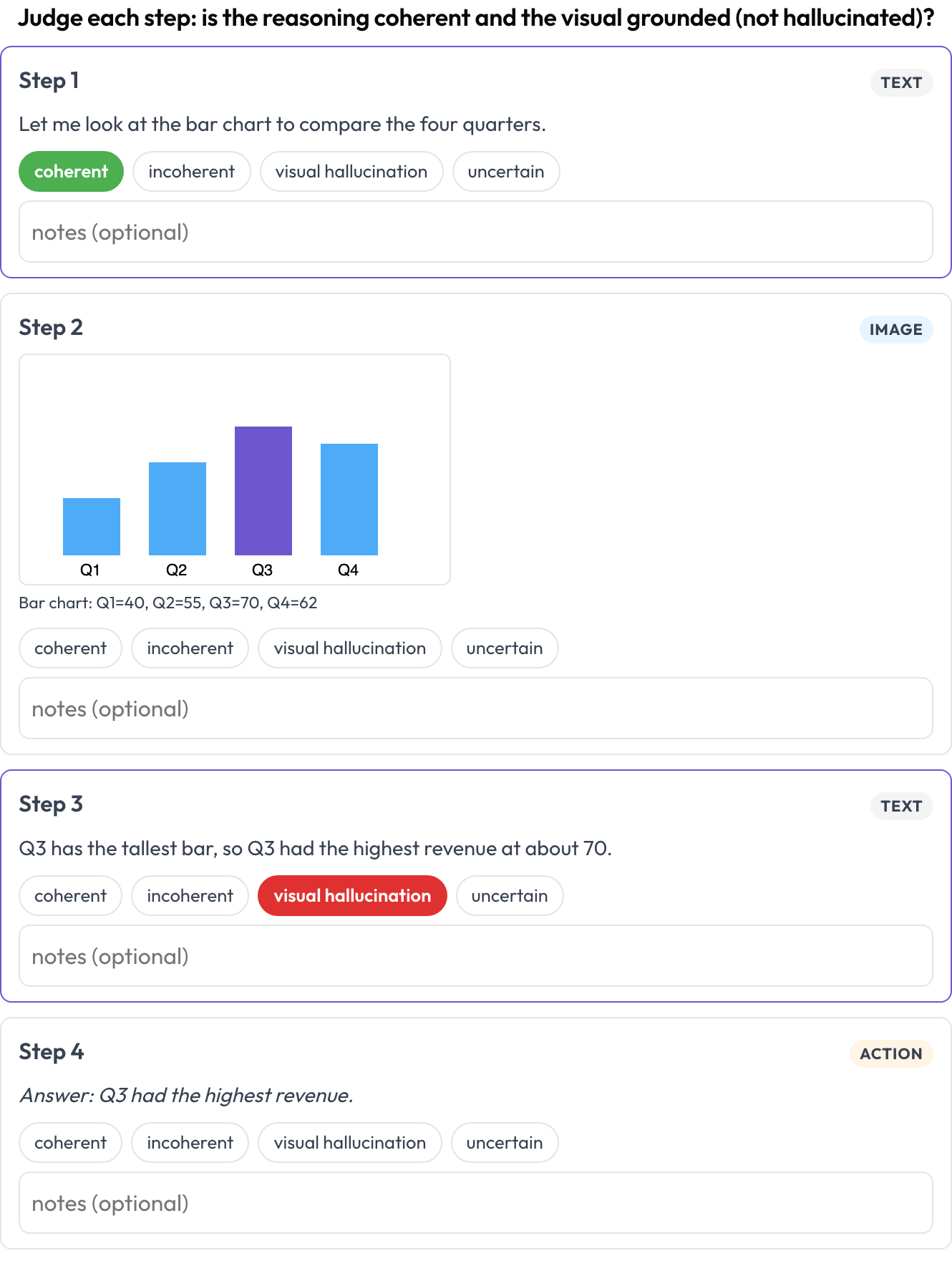 テキスト・画像・ツールの推論トレースの各ステップを、一貫性と視覚的ハルシネーションについて評価する
テキスト・画像・ツールの推論トレースの各ステップを、一貫性と視覚的ハルシネーションについて評価する
これらのスキーマのいくつかは同じタスク上で実行できるため、1 つのドキュメントエージェントの実行を、表構造と推論の一貫性について同時にスコアリングできます。
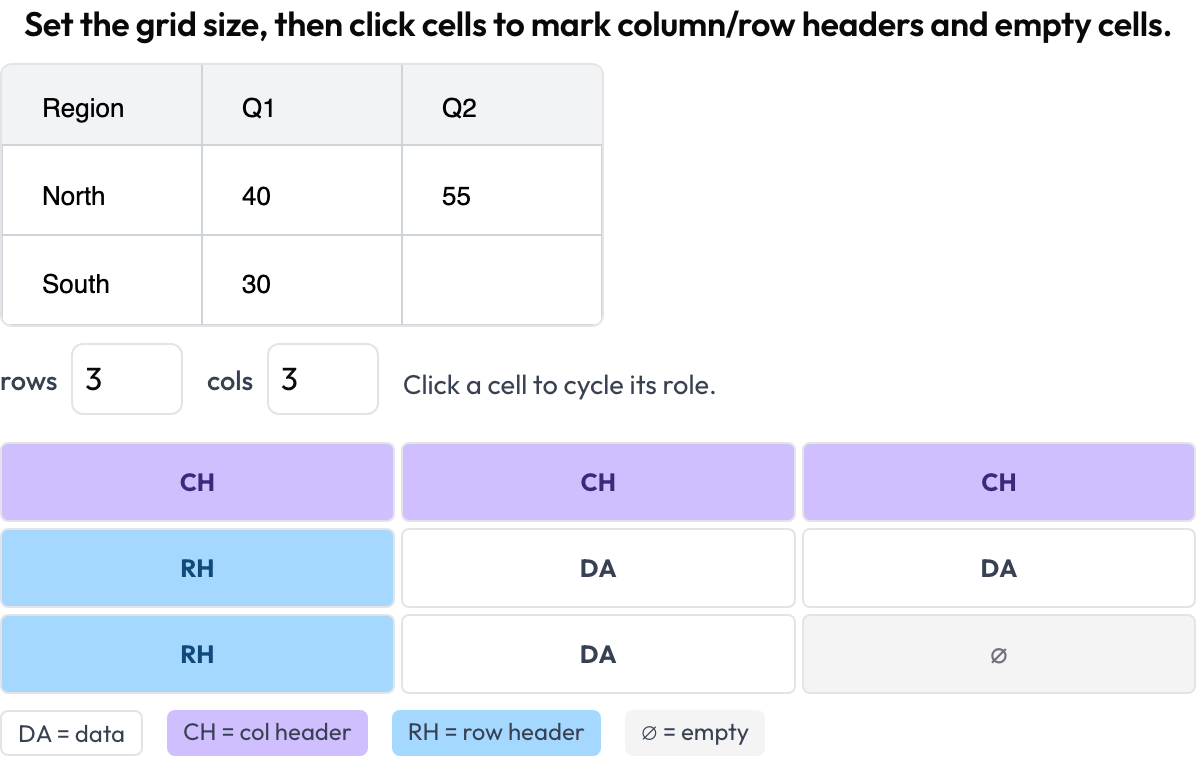 ドキュメントの表のセル構造を注釈する:列・行ヘッダー、データ、空のセル
ドキュメントの表のセル構造を注釈する:列・行ヘッダー、データ、空のセル
これをどうセットアップするのか?
各サーフェスは、examples/agent-traces/ の下に実行可能な例を出荷します:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000あなたのデータは、タイムスタンプ付きのターン、セグメント、またはイベントとして投入します。サーフェスは、それらからレンダリング時にタイムラインを導出します。GUI および OS エージェントについては、姉妹編の コンピュータ操作エージェントの評価 があります。
さらに読む
- マルチモーダルエージェント評価 — 完全なスキーマリファレンス
- コンピュータ操作およびマルチモーダルエージェントの評価 — スキーマ選択の表を含むガイド
- コンピュータ操作エージェントを評価する、ステップごとに — マルチモーダルサーフェスのうち GUI および OS の半分
- Potato 2.6.2:完全なオープンソースのエージェント評価スイート — 2.6.x 系列のすべて