Evaluación de agentes multimodales
Evalúa agentes que actúan más allá del texto, agentes de uso del ordenador y de GUI, asistentes de voz, vídeo y agentes de documentos. Potato añade esquemas creados a medida para trayectorias de GUI con anclaje de clics, líneas de tiempo de voz full-duplex, anclaje temporal de vídeo con IoU en vivo, etiquetado de errores de transcripción de voz, razonamiento multimodal intercalado y estructura de cuadrícula de tablas.
Cada vez más los agentes actúan en modalidades más allá del texto: manejan GUIs, ven vídeo y mantienen conversaciones habladas. Cada modalidad necesita una superficie de revisión que un widget de texto plano no puede ofrecer, una captura de pantalla con el clic del agente, una línea de tiempo de voz de doble pista, un control de vídeo con intervalos de oro. Potato añade esquemas de anotación creados a medida para estas trazas, junto a sus vistas existentes de imagen, audio y vídeo.
Cada esquema deriva sus pasos, turnos o segmentos de la traza en el momento de renderizar, y cada uno incluye un ejemplo ejecutable en examples/agent-traces/.
Trayectoria de GUI / uso del ordenador (gui_trajectory)
Evalúa un agente de uso del ordenador, de GUI o de SO paso a paso (OSWorld, NeurIPS 2024; ScreenSpot-Pro; AndroidWorld). Cada paso muestra la captura de pantalla que vio el agente y la acción que tomó; el anotador juzga la acción (correcta / elemento incorrecto / acción incorrecta / alucinada). Cuando un paso lleva coordenadas de clic, un marcador de anclaje sobre la captura muestra si el clic cayó en el elemento correcto.
 Revisa cada paso de uso del ordenador: corrección de la acción más anclaje del clic en la captura
Revisa cada paso de uso del ordenador: corrección de la acción más anclaje del clic en la captura
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot # field on each step holding an image URL / data-URI
action_key: action # field holding the action text
coord_space: normalized # normalized (0..1) | pixels — for the x/y grounding marker
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Cada paso puede aportar screenshot, action y opcionalmente x/y (o un click: {x, y} anidado). Se almacena como una lista de {index, step, verdict, notes}.
Interacción de voz / full-duplex (voice_interaction)
Anota una conversación hablada humano↔agente para la toma de turnos y la gestión de interrupciones (Full-Duplex-Bench, 2025). Una línea de tiempo de doble pista (carril de usuario más carril de agente) coloca cada turno por su tiempo de inicio y fin y resalta las regiones de solapamiento donde ambos hablantes hablan a la vez. El anotador clasifica cada solapamiento (el agente debería responder / debería reanudar / retroalimentación / incierto) y valora la toma de turnos en general; el audio fuente se reproduce en línea cuando se proporciona.
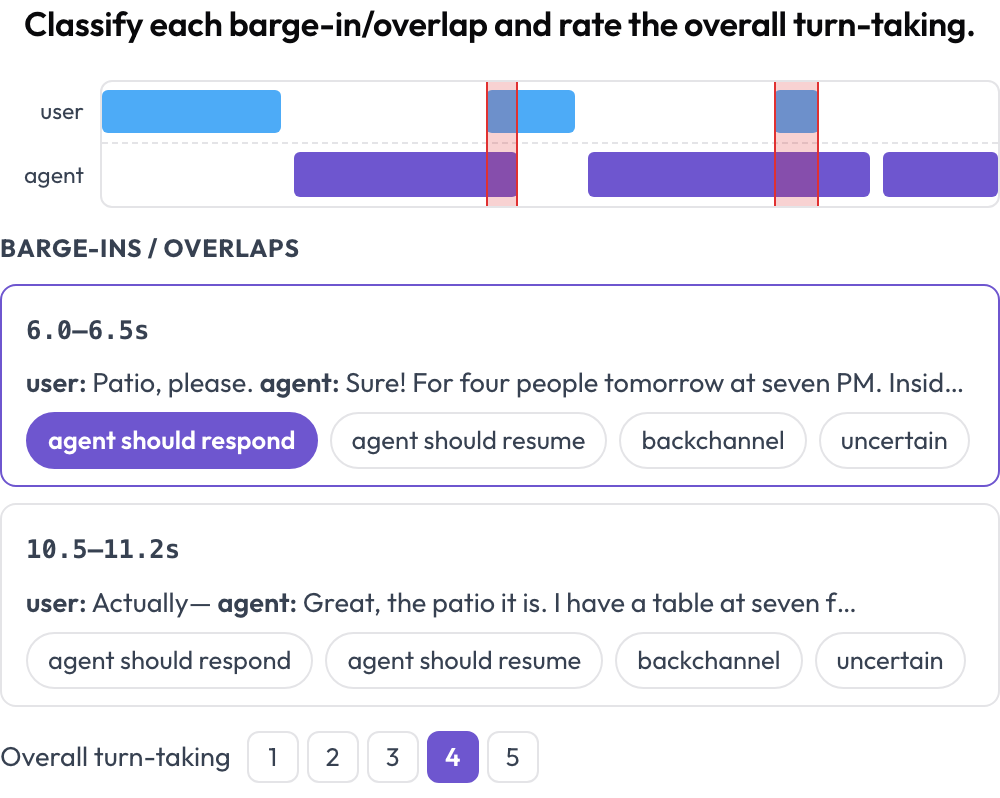 Una línea de tiempo de voz de doble pista con detección de interrupciones y puntuación de la toma de turnos
Una línea de tiempo de voz de doble pista con detección de interrupciones y puntuación de la toma de turnos
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns # list of {speaker, start, end, text} (seconds)
speaker_key: speaker
user_speakers: [user, human, caller] # everything else is treated as the agent
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5
# audio_key: audio # optional per-instance audio URL to enable the playerLos solapamientos entre turnos de distintos hablantes se calculan en el momento de renderizar. Se almacena como {"overlaps": {idx: label}, "rating": int}.
Anclaje temporal de vídeo (temporal_grounding)
Marca intervalos de tiempo de eventos en un vídeo para la evaluación de anclaje temporal (TimeScope, 2025; ET-Bench). Para cada indicación de evento, el anotador fija el [start, end] de oro, capturando el cabezal de reproducción o escribiendo segundos. Cuando los datos llevan un intervalo predicho por un modelo, un IoU en vivo y una mini línea de tiempo de dos barras (predicho vs. oro) se actualizan según ajustas. Esto está creado a medida para la puntuación de localización predicho-vs-oro, distinta del etiquetado general de segmentos.
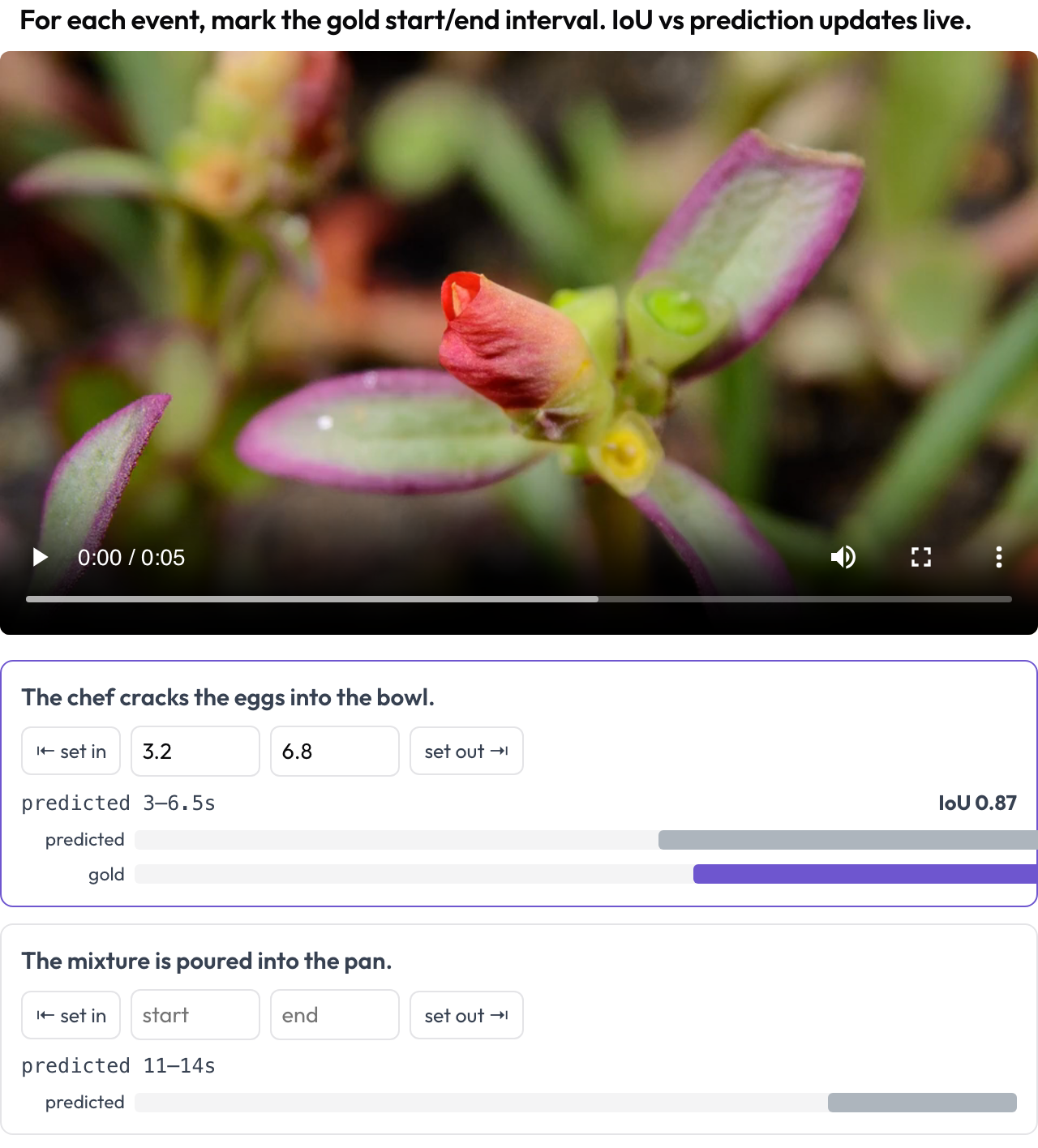 Marca intervalos de evento de oro en vídeo con un IoU en vivo frente a la predicción del modelo
Marca intervalos de evento de oro en vídeo con un IoU en vivo frente a la predicción del modelo
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video # per-instance video URL
events_key: events # list of {prompt, predicted: {start, end}} (predicted optional)
# duration: 120 # optional fixed timeline scale (else inferred from the video)Se almacena como {"events": {idx: {start, end}}}.
Errores de transcripción de voz alineada (speech_transcript)
Anota una transcripción de voz alineada en el tiempo segmento por segmento para errores de ASR/TTS y de calidad de voz (Speak & Improve, 2025). Cada segmento {start, end, text, speaker?} es una ficha que muestra su marca de tiempo y su texto; el anotador etiqueta errores (error de ASR / artefacto de TTS / mala pronunciación / disfluencia) y puede escribir la transcripción corregida. Este es el complemento a nivel de segmento de la vista de toma de turnos de voice_interaction.
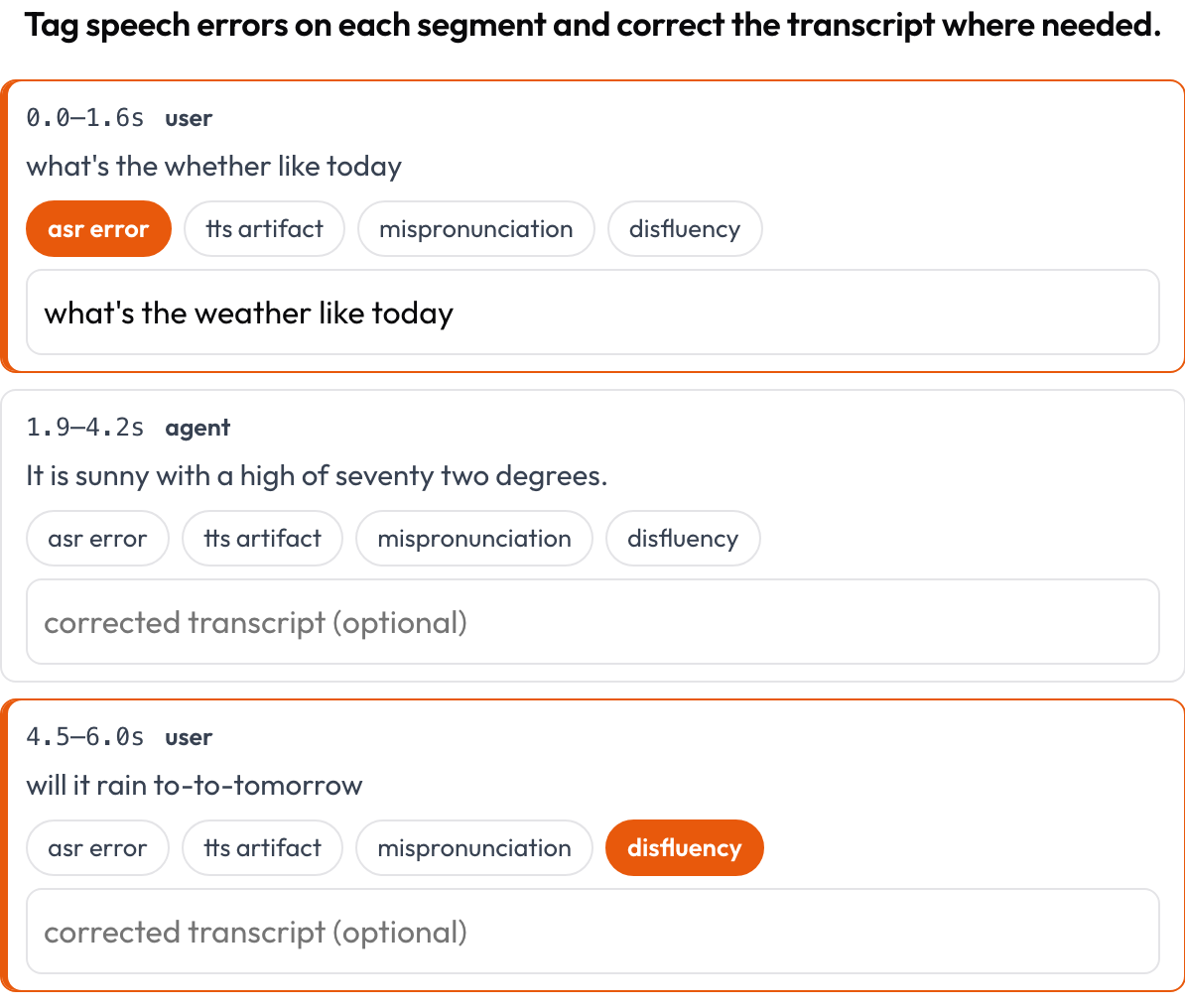 Etiqueta errores de ASR/TTS/pronunciación por segmento y corrige la transcripción en línea
Etiqueta errores de ASR/TTS/pronunciación por segmento y corrige la transcripción en línea
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments # list of {start, end, text, speaker?}
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true
# audio_key: audio # optional per-item audio URL to enable the playerSe almacena como una lista de {index, start, end, errors, correction}.
Razonamiento multimodal intercalado (multimodal_reasoning)
Valora una traza de razonamiento intercalado texto ↔ imagen ↔ herramienta ↔ acción paso a paso (Multimodal RewardBench 2, 2025; Zebra-CoT). Cada paso es un bloque tipado, renderizado en línea según su tipo; el anotador juzga la coherencia de cada paso, ¿el razonamiento se desprende de la imagen y de los pasos previos, o el elemento visual está alucinado?
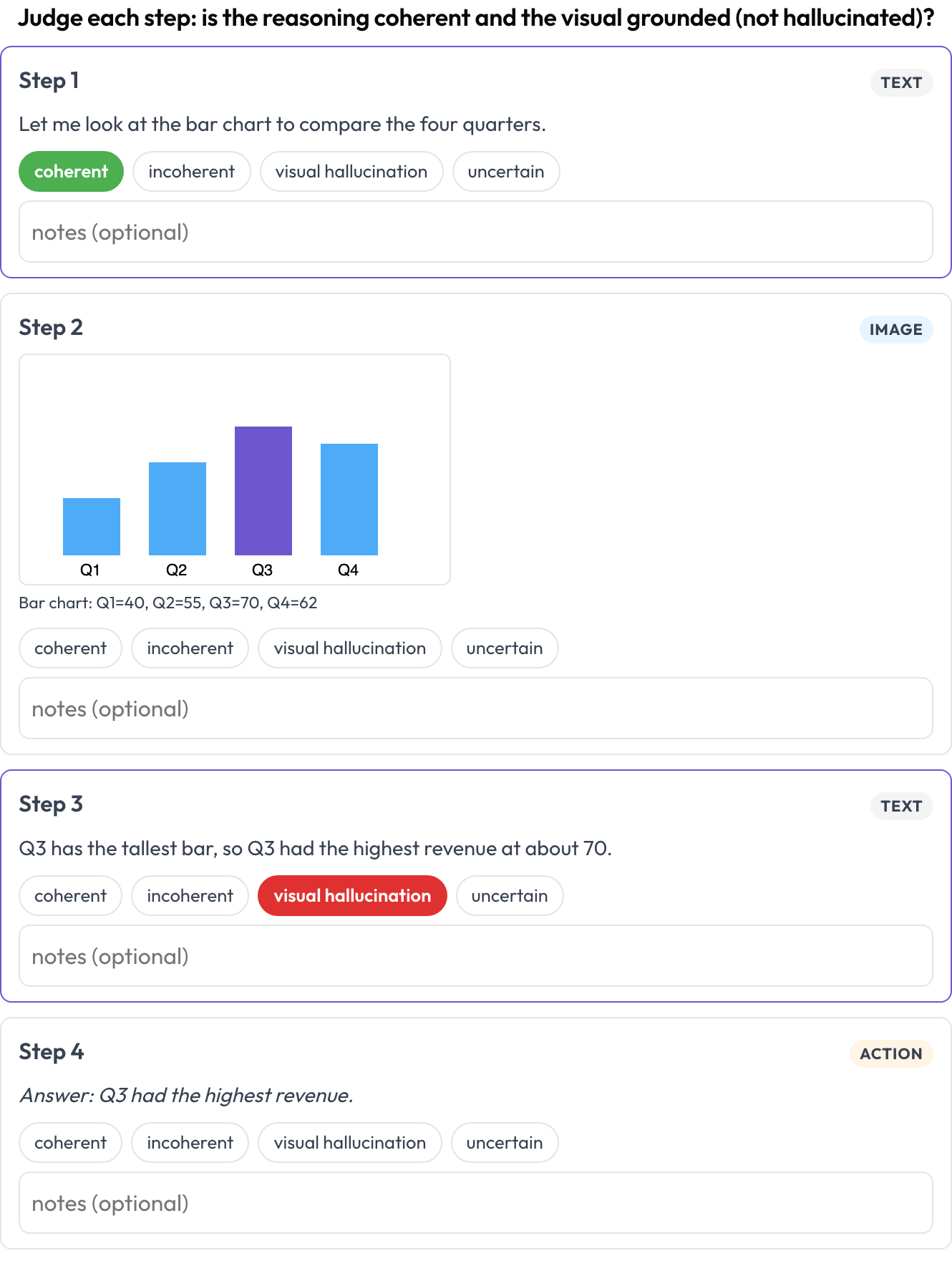 Valora cada paso de una traza de razonamiento texto-imagen-herramienta por su coherencia y alucinación visual
Valora cada paso de una traza de razonamiento texto-imagen-herramienta por su coherencia y alucinación visual
annotation_schemes:
- annotation_type: multimodal_reasoning
name: reasoning_review
description: "Judge each step: coherent reasoning and grounded visuals?"
steps_key: steps
type_key: type # each step's 'type': text | image | tool | action (inferred if absent)
verdict_options: [coherent, incoherent, visual_hallucination, uncertain]Cada paso puede llevar text/content, image/image_url (+caption), o tool/args. Se almacena como una lista de {index, step, type, verdict, notes}.
Estructura de cuadrícula de tablas (table_grid)
Anota la estructura de celdas de la imagen de una tabla, la pieza específica de documentos que las cajas delimitadoras simples no pueden capturar (OmniDocBench, CVPR 2025; RealHiTBench). El anotador fija las dimensiones de la cuadrícula y hace clic en las celdas para marcar su rol (dato / encabezado de columna / encabezado de fila / vacía). Las cajas de región por página ya están cubiertas ejecutando la anotación de imágenes por página, así que este esquema se centra en la estructura que esas cajas no pueden expresar.
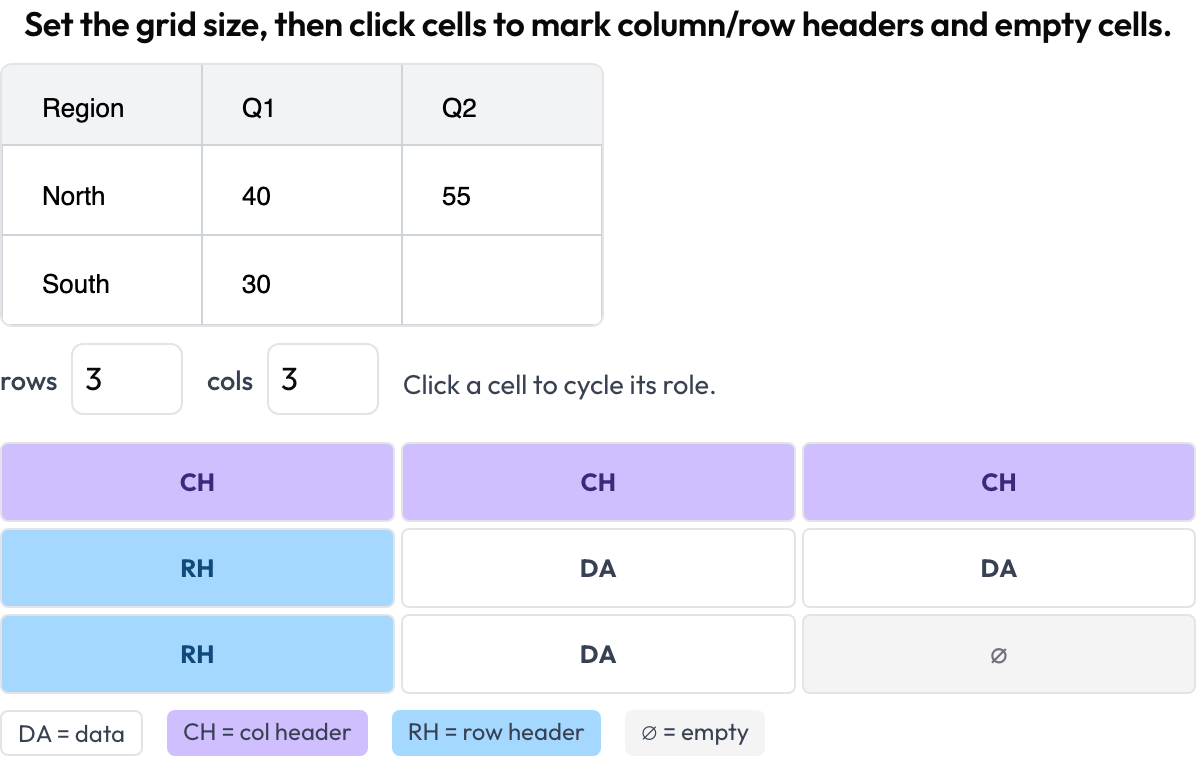 Anota la estructura de celdas de una tabla de documento: encabezados de columna y fila, datos y celdas vacías
Anota la estructura de celdas de una tabla de documento: encabezados de columna y fila, datos y celdas vacías
annotation_schemes:
- annotation_type: table_grid
name: structure
description: "Set the grid size, then click cells to mark headers and empty cells."
image_key: image # per-instance table image URL / data-URI
rows_key: rows # optional initial dims from the data
cols_key: cols
roles: [data, col_header, row_header, empty] # click cycles through theseSe almacena como {rows, cols, cells: {"r,c": role}}, conservando solo las celdas que no son data.
Relacionado
- Evaluación de equipos multiagente — grafo de interacción, traspasos y fichas de puntuación del equipo
- Evaluación de agentes web — agentes web de captura y acción
- Cómo evaluar agentes de IA — los niveles de evaluación de agentes
- Anotación agéntica — configuración e ingesta de la vista de trazas
Para detalles de implementación, consulta la documentación fuente.