Evaluación de equipos multiagente
Anota sistemas multiagente por la estructura del equipo, no por una transcripción plana. Potato añade un grafo de interacción de agentes clicable, atribución de fallos entre agentes, revisión de traspasos, fichas de puntuación por agente y por equipo, una línea de tiempo de contención de herramientas y etiquetado de comportamiento emergente.
Un sistema multiagente falla de forma distinta a un único agente: la avería ocurre entre agentes, en un traspaso, o en cómo se organizó el equipo. Evaluarlo significa atribuir los resultados a qué agente, qué paso y qué traspaso, no solo puntuar una transcripción plana. Potato añade un conjunto de superficies de anotación creadas para eso: un grafo de interacción clicable, atribución de fallos, revisión de traspasos, fichas de puntuación por agente y por equipo, una línea de tiempo de contención de herramientas y etiquetado de comportamiento emergente entre carriles.
Estas se apoyan en la vista de traza de agente y la taxonomía de fallos MAST. Cada esquema deriva sus agentes, pasos y traspasos de la propia traza en el momento de renderizar, de modo que el anotador elige entre lo que realmente ocurrió en la ejecución.
Grafo de interacción (agent_interaction_graph)
Toda la ejecución se renderiza como un grafo dirigido: los nodos son agentes, las aristas son las transiciones de mensajes y traspasos entre ellos (las aristas más gruesas indican mayor frecuencia), dispuesto automáticamente a partir de la traza. El anotador hace clic en un nodo para marcar el camino crítico y clic en una arista para alternarla normal → crítica → problemática. Esta es la respuesta más clara a "cómo veo la estructura de una ejecución multiagente", y es una superficie que las herramientas de anotación generales no ofrecen.
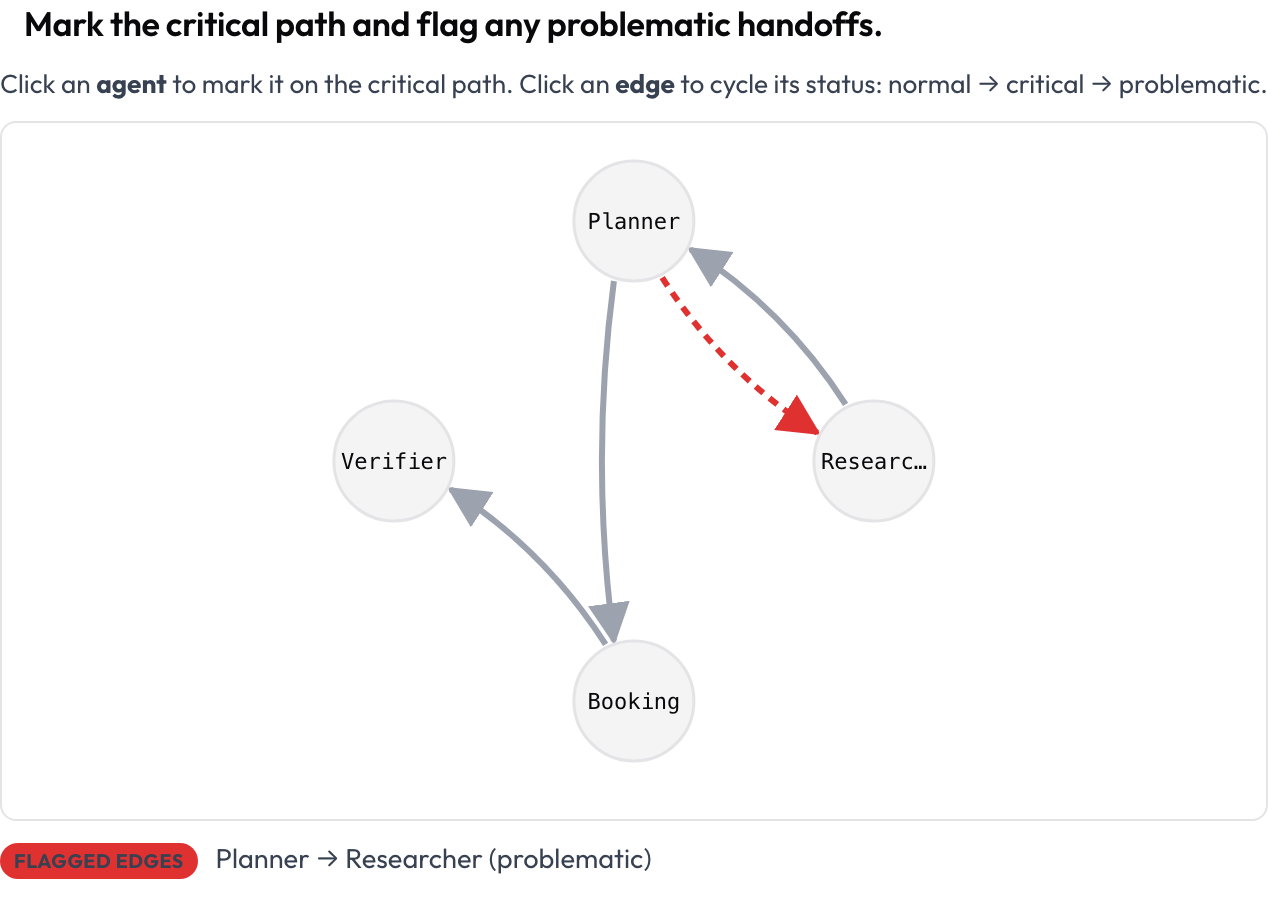 Marca el camino crítico y señala traspasos problemáticos en un grafo de interacción de agentes clicable
Marca el camino crítico y señala traspasos problemáticos en un grafo de interacción de agentes clicable
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentSe almacena como {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}. Cada nodo y arista es enfocable con el teclado y un resumen de texto en vivo enumera los nodos críticos y las aristas señaladas, de modo que el significado nunca recae solo en el color.
Atribución de fallos entre agentes (failure_attribution)
Cuando un equipo falla, la etiqueta útil es la tripleta (agente responsable, paso decisivo, motivo) de la literatura de atribución de fallos (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, el conjunto de datos Who&When). El desplegable de agentes y el selector de pasos se rellenan a partir de los propios turnos de la traza, de modo que el anotador atribuye el fallo a un agente real y un paso real.
 Atribuye un fallo multiagente al agente responsable, el paso decisivo y el porqué
Atribuye un fallo multiagente al agente responsable, el paso decisivo y el porqué
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the traceSe almacena como {"responsible_agent", "decisive_step", "reason"}. Combínalo con un esquema de resultado radio (éxito/fallo) para que la atribución solo se active en ejecuciones fallidas.
Revisión de traspasos (handoff_review)
Cada traspaso, un agente cediendo el control a otro, se convierte en un objeto de primera clase para anotar. Allí donde el agente que actúa cambia entre turnos consecutivos, Potato emite una ficha de traspaso A → B; el anotador señala la desalineación entre agentes y valora la calidad del traspaso. Los modos de fallo se anclan en la categoría inter-agente de MAST y en el fenómeno de "eco" (Zhang et al., 2025).
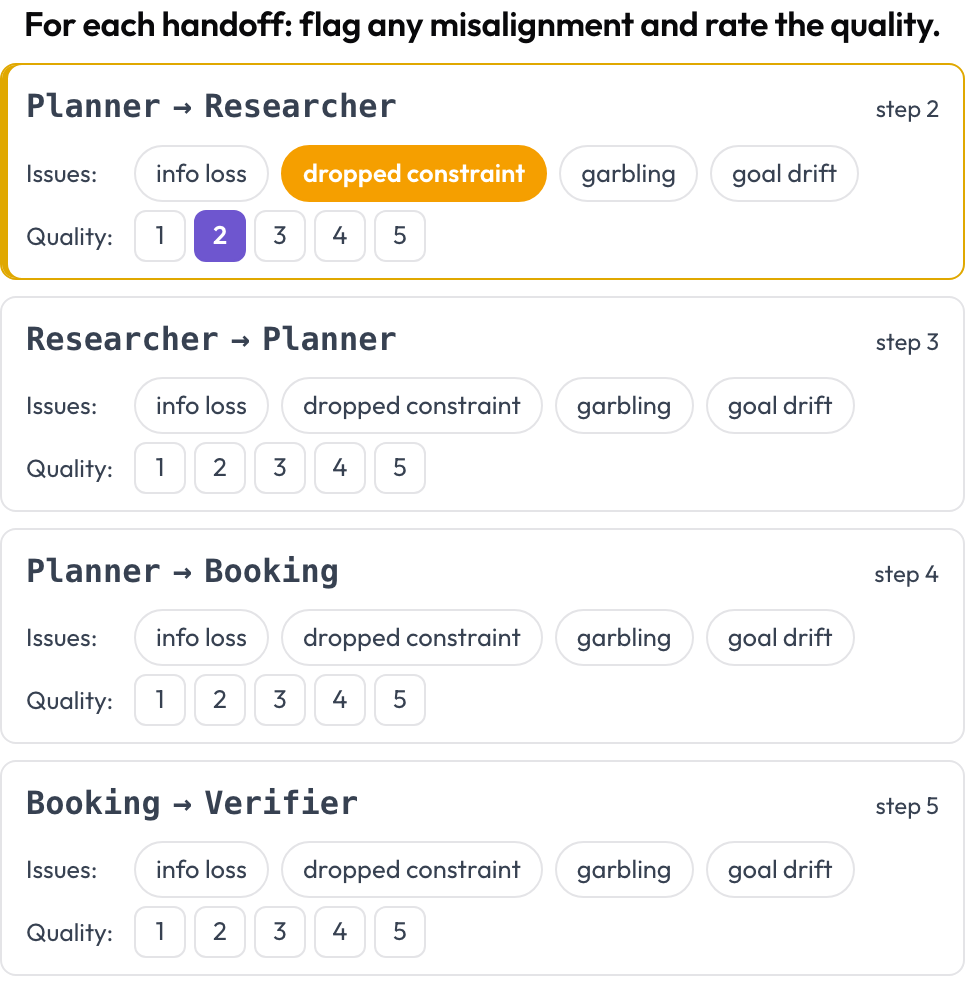 Señala la desalineación entre agentes en cada traspaso y valora su calidad
Señala la desalineación entre agentes en cada traspaso y valora su calidad
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Los traspasos se derivan de la traza en el momento de renderizar, así que no hay configuración manual. Se almacenan como una lista de {index, step, from, to, flags, quality}.
Ficha de puntuación por agente y por equipo (agent_scorecard)
Puntúa una ejecución en dos niveles a la vez (MultiAgentBench, Zhou et al., ACL 2025): cada agente recibe puntuaciones por dimensión (fidelidad al rol, contribución, coordinación), el equipo recibe puntuaciones en dimensiones compartidas, y se marcan hitos opcionales. Las filas de agentes provienen de los propios turnos de la traza, de modo que la matriz coincide con quién participó realmente.
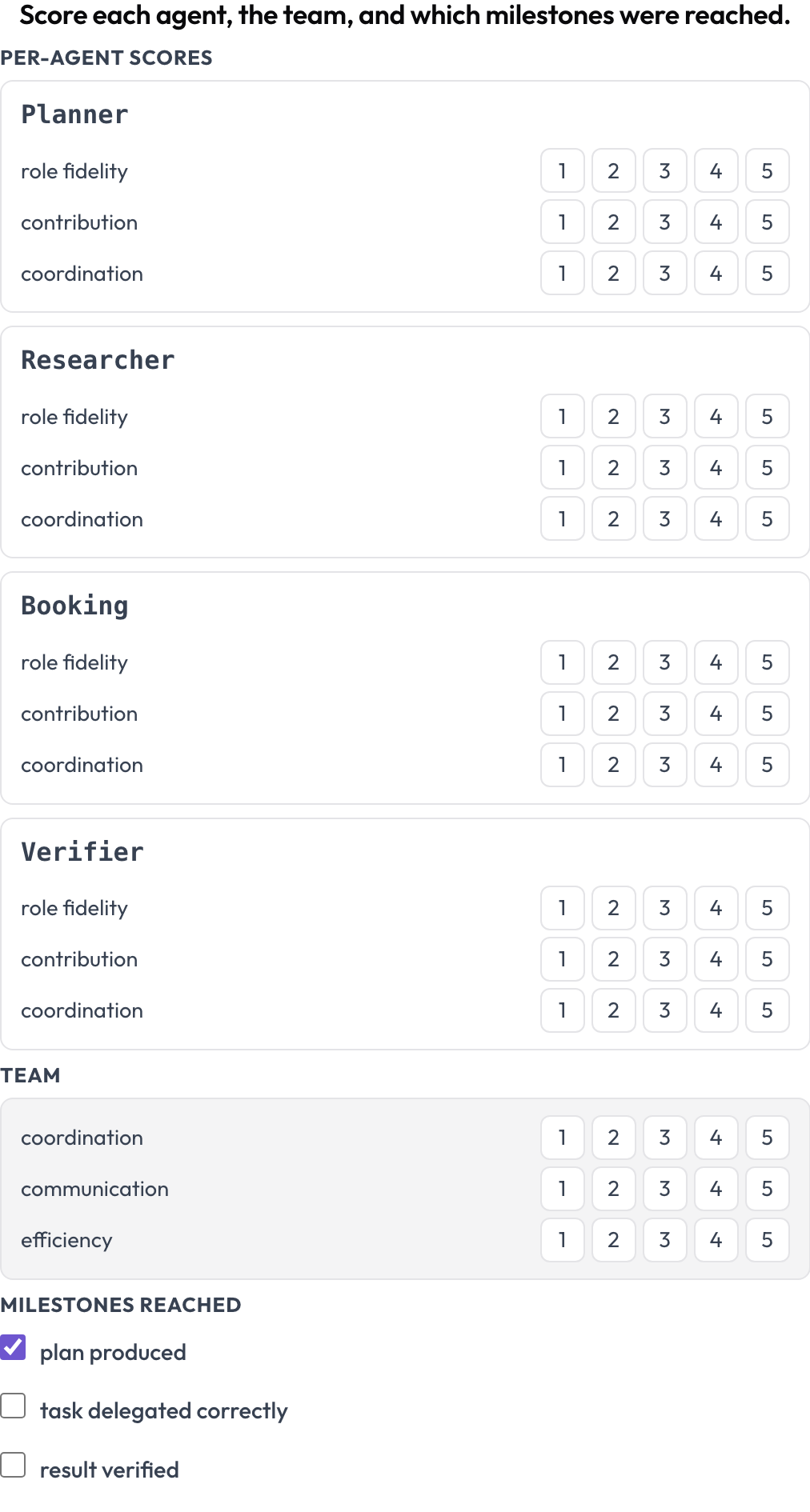 Puntúa cada agente en fidelidad al rol, contribución y coordinación, además del equipo y los hitos
Puntúa cada agente en fidelidad al rol, contribución y coordinación, además del equipo y los hitos
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optionalSe almacena como {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}.
Línea de tiempo de contención de herramientas / recursos (tool_contention)
El uso concurrente de herramientas y recursos entre agentes se renderiza en una línea de tiempo de varios carriles, un carril por agente. Las regiones donde dos llamadas tocan el mismo recurso en tiempos solapados se resaltan a lo largo de los carriles y se enumeran para clasificarlas: bloqueo mutuo, espera circular, condición de carrera o benigna (DPBench, 2026). Así es como detectas fallos de concurrencia que una transcripción por turnos oculta.
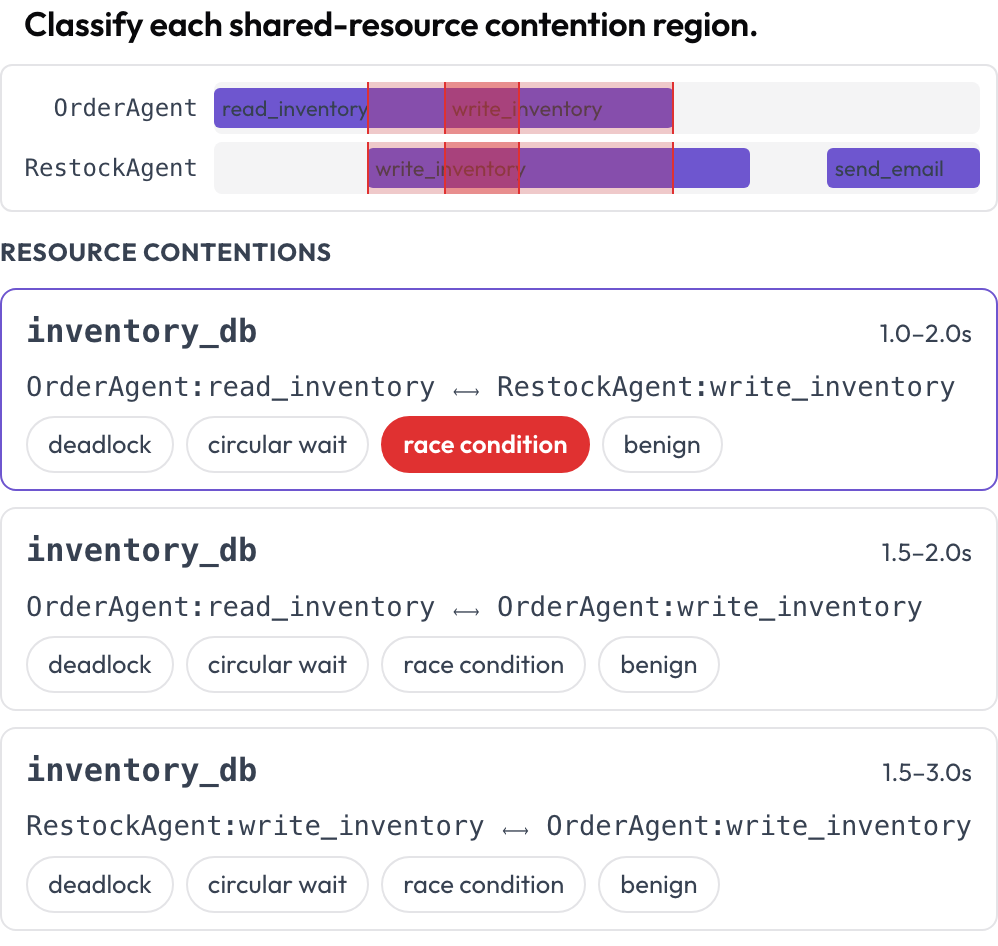 Detecta bloqueos mutuos y condiciones de carrera en una línea de tiempo de llamadas a herramientas por agente
Detecta bloqueos mutuos y condiciones de carrera en una línea de tiempo de llamadas a herramientas por agente
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]Las regiones de contención se calculan en el momento de renderizar (mismo resource, intervalo solapado). Se almacenan como {"contentions": {idx: label}}.
Comportamiento emergente entre carriles (emergent_behavior)
Algunos fallos son colectivos: colusión, pensamiento de grupo, errores en cascada, deriva de rol. Un comportamiento emergente no es un span de texto contiguo; es un conjunto de turnos participantes, posiblemente de distintos agentes. Para cada comportamiento, el anotador marca los turnos que participan y añade una nota, un span entre carriles expresado como un conjunto de turnos.
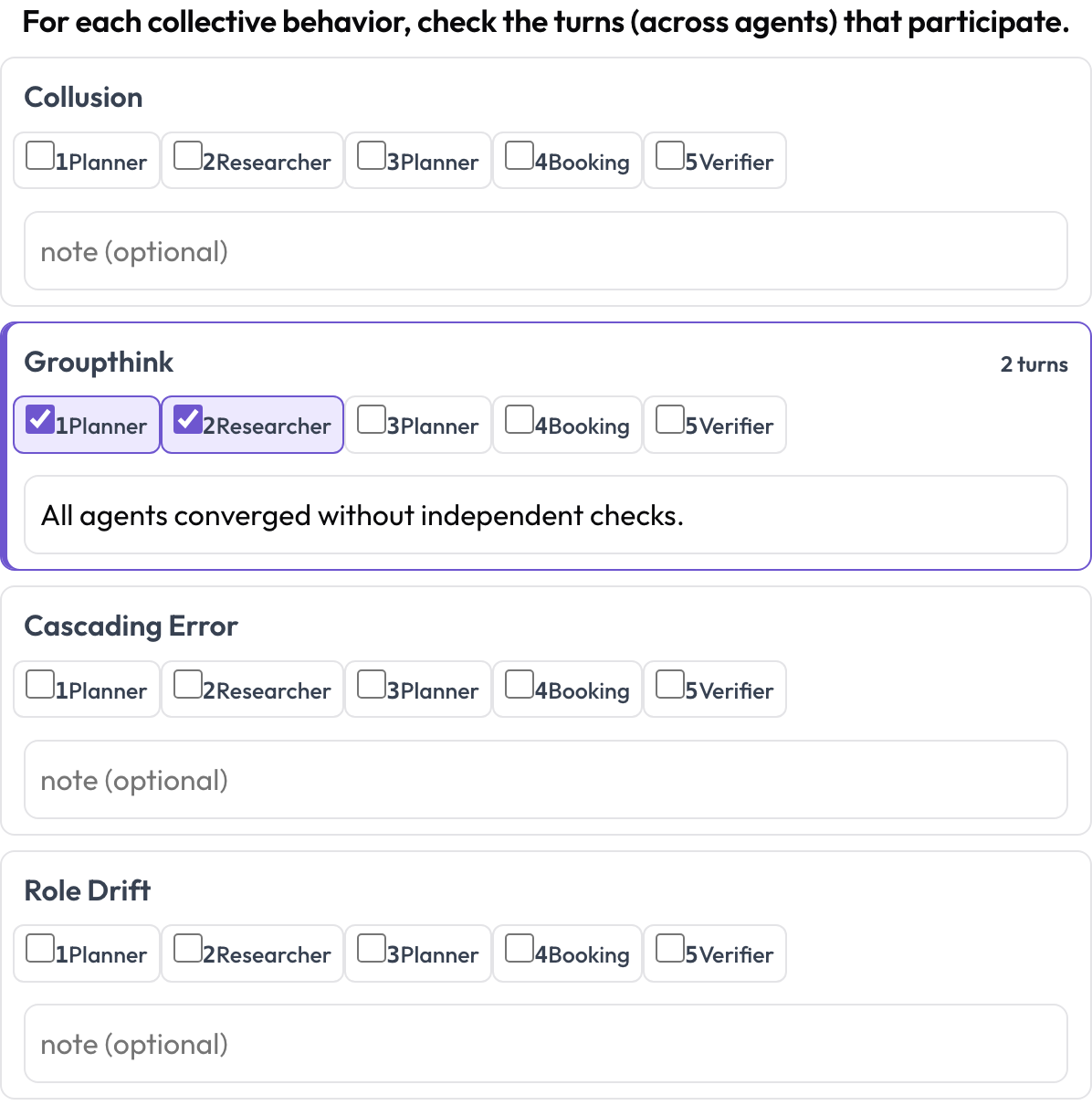 Etiqueta colusión, pensamiento de grupo y errores en cascada entre agentes y turnos
Etiqueta colusión, pensamiento de grupo y errores en cascada entre agentes y turnos
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueSe almacena como {behavior: {turns: [idx...], note}}, conservando solo los comportamientos no vacíos.
Revisión de llamadas a herramientas (tool_call_review)
Juzga cada llamada a herramienta o función de forma individual: ¿se eligió la herramienta correcta, los argumentos eran correctos, el orden era el adecuado (replicando BFCL v4 / MCPMark)? Las llamadas a herramientas se extraen de los pasos de la traza en el momento de renderizar; cada tool_calls, tool_call o action de un paso se convierte en una ficha con el nombre de la herramienta y los argumentos formateados.
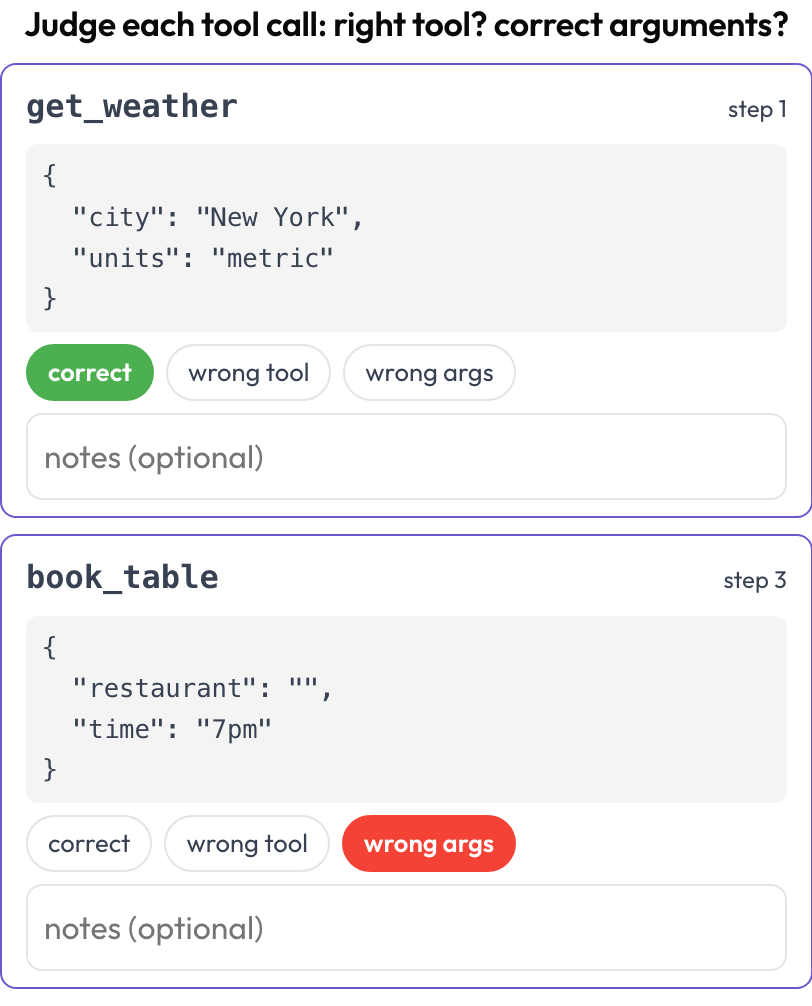 Juzga cada llamada a herramienta: herramienta correcta, argumentos correctos, orden correcto
Juzga cada llamada a herramienta: herramienta correcta, argumentos correctos, orden correcto
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizableSe almacena como una lista de {index, step, tool, verdict, notes}.
Etiquetado MAST con granularidad de paso
No necesitas un esquema nuevo para vincular la taxonomía de fallos MAST de 14 modos (Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025) al paso exacto (y por tanto al agente que actúa) donde ocurrió un fallo. Configura el esquema existente por paso trajectory_eval con los modos MAST como sus error_types, agrupados por las tres categorías MAST. Combínalo con failure_attribution y handoff_review para una cobertura completa.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]Elegir el enfoque de orquestación
La arquitectura de orquestación a menudo domina el resultado de una ejecución, así que vale la pena capturarla como una etiqueta de primera clase. No se necesita un esquema nuevo: un radio confirma o corrige el patrón de la ejecución, que luego guía tanto el enfoque de evaluación como la disposición de la traza (secuencial → carriles, jerárquico → árbol, chat grupal → tablero).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueRelacionado
- Evaluación de agentes multimodales — esquemas para GUI, voz, vídeo y agentes de documentos
- Anotar trayectorias de agentes — anotación de errores por paso
- Cómo evaluar agentes de IA — los niveles de evaluación de agentes
- Anotación agéntica — configuración e ingesta de la vista de trazas
Para detalles de implementación, consulta la documentación fuente.