Alineación juez ↔ humano
Mide qué tan bien coincide un juez LLM con tus etiquetas de oro humanas. Potato ejecuta el juez sobre las instancias anotadas, calcula el kappa de Cohen, una matriz de confusión y una lista de desacuerdos, y hace seguimiento de la concordancia a medida que refinas la rúbrica.
La alineación del juez mide y ajusta qué tan bien coincide un juez LLM con tus etiquetas de oro humanas. Potato ejecuta un LLM-as-a-judge configurable sobre las instancias que tus anotadores ya han etiquetado, calcula la κ de Cohen, una matriz de confusión y una lista de desacuerdos, y hace seguimiento de κ a medida que editas la rúbrica del juez. Con el modo en línea activado, el veredicto del juez aparece junto a la etiqueta humana durante la anotación, con una κ en tiempo real.
Este es el bucle estándar de «alinea tu juez con unas 100–200 etiquetas de oro» que usan herramientas como LangSmith Align Evals y Evidently: recoge etiquetas humanas, ejecuta el juez, inspecciona los desacuerdos, refina la rúbrica y vuelve a ejecutar hasta que la concordancia sea alta.
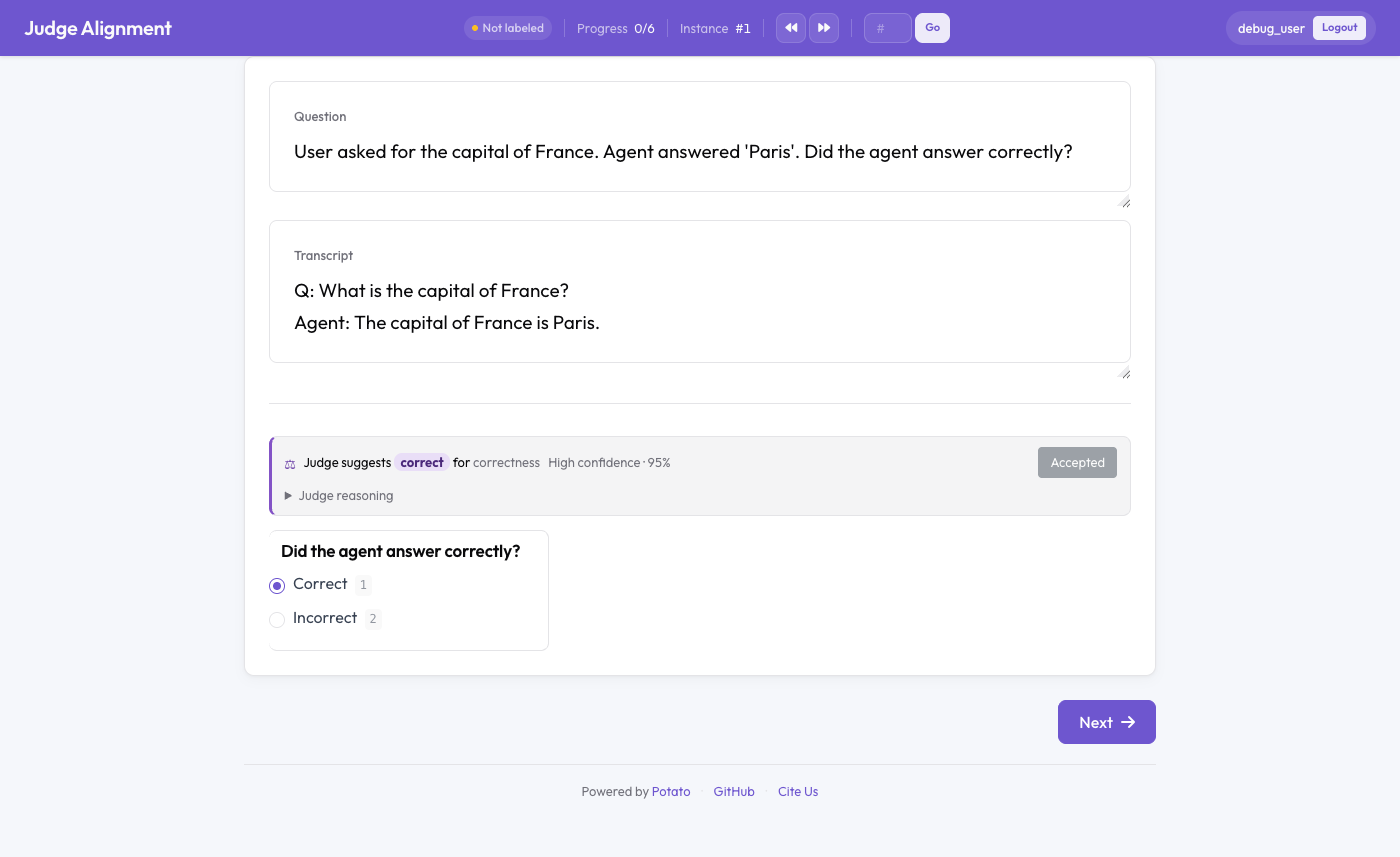 Veredicto de un juez LLM mostrado junto a la anotación humana con un kappa en tiempo real
Veredicto de un juez LLM mostrado junto a la anotación humana con un kappa en tiempo real
Configuración
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict existsEl alcance abarca los esquemas categóricos de selección única (radio, select, likert). Si se establece judge_alignment.schemas, solo se juzgan esos esquemas; de lo contrario, se juzgan todos los esquemas categóricos.
Ejecutar el juez
Ejecuta el juez desde la API de administración. Las predicciones se almacenan en caché por versión de prompt, así que volver a ejecutarlas resulta económico:
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Para calibrar, pasa una rúbrica editada. Eso crea una nueva versión del prompt, de modo que puedes comparar κ entre rondas:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'El informe de alineación
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
Envía la cabecera X-API-Key. Por cada esquema, el informe muestra:
- La κ de Cohen con una interpretación de Landis–Koch, la tasa de concordancia y el número de instancias comparadas.
- Una matriz de confusión (las filas son el oro humano, las columnas son el juez).
- Una tabla de desacuerdos con la instancia, la etiqueta humana, la etiqueta del juez, la confianza y el razonamiento del juez.
- El historial de versiones del prompt con la κ media por versión, de modo que el progreso de la calibración sea visible.
El oro humano es el voto mayoritario entre los anotadores para cada instancia.
Modo en línea
Con inline.enabled, cada página de anotación muestra el veredicto en caché del juez para la instancia —su etiqueta, su confianza y su razonamiento expandible— junto a una κ en tiempo real para la tarea. «Aceptar» rellena la opción coincidente. Cada guardado humano registra una comparación humano↔juez que alimenta la concordancia en tiempo real. Establece compute_on_demand: true para llamar al juez en vivo cuando no exista un veredicto en caché; de lo contrario, ejecuta el lote por adelantado, que es más rápido.
Notas y limitaciones
- En esta versión la calibración es manual: edita la rúbrica y vuelve a ejecutar. La optimización automática de prompts queda fuera del alcance.
- El alcance abarca los esquemas categóricos de selección única. Juzgar tramos (span) y texto libre es trabajo futuro.
- Ejecuta el juez sobre un conjunto de oro acotado de unas 100–200 instancias etiquetadas para obtener una κ estable.
Relacionado
- Calibración de jueces LLM — calibración con varios jueces y humano ciego, con error de calibración
- Cola de triaje — dirige primero a los humanos los elementos más informativos
- Guía de concordancia entre anotadores — las métricas kappa en profundidad
Para conocer los detalles de implementación, consulta la documentación de origen.