Trajektorienbearbeitung für SFT/DPO
Annotatoren schreiben die Schritte einer Agenten-Trace um, um einen falschen Denkschritt zu beheben, einen Tool-Aufruf zu korrigieren oder die endgültige Antwort zu stärken, und Potato exportiert jedes Original/Korrektur-Paar als Ziele für überwachtes Fine-Tuning und als DPO-Präferenzpaare.
Das trajectory_edit-Schema ermöglicht es Annotatoren, die Schritte einer Agenten-Trace umzuschreiben, und exportiert jede Korrektur als Trainingsdaten. Behebe einen falschen Denkschritt, korrigiere einen vertippten Tool-Aufruf oder stärke die endgültige Antwort, und Potato speichert die korrigierte Trajektorie neben dem Original. Der trajectory_correction-Exporter verwandelt anschließend jedes (original, corrected)-Paar in Ziele für überwachtes Fine-Tuning (SFT) und in Präferenzpaare für Direct Preference Optimization (DPO).
Dadurch wird Potato zu einem Werkzeug zur Erzeugung von Trainingsdaten und nicht nur zu einem Evaluierungswerkzeug. Es ist das bearbeitende Gegenstück zur Bewertung auf Schrittebene: Statt eine Trajektorie zu bewerten, reparieren Annotatoren sie, und die Reparatur wird zum Lernsignal.
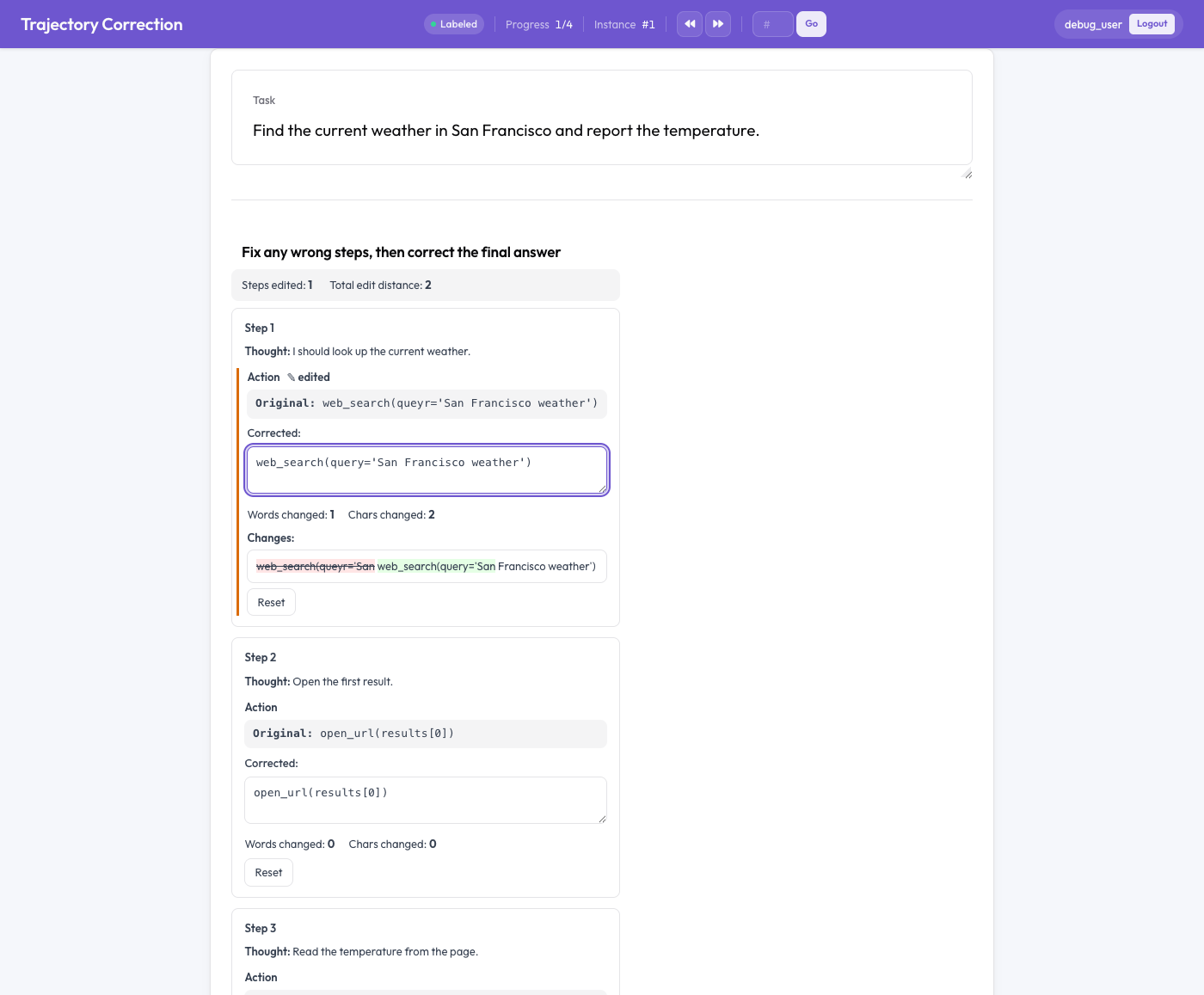 Ein Agentenschritt, dargestellt mit einem schreibgeschützten Original und einem bearbeitbaren Korrekturfeld mit einem Diff auf Wortebene
Ein Agentenschritt, dargestellt mit einem schreibgeschützten Original und einem bearbeitbaren Korrekturfeld mit einem Diff auf Wortebene
Schnellstart
Führe das mitgelieferte Beispiel aus dem Repository-Stammverzeichnis aus:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000Funktionsweise
Jeder Agentenschritt wird als Karte dargestellt, die den originalen Text (schreibgeschützt) und ein bearbeitbares korrigiertes Feld zeigt, das mit dem Original vorausgefüllt ist. Während der Annotator tippt:
- hebt ein Live-Diff auf Wortebene Einfügungen (grün) und Löschungen (rot durchgestrichen) hervor,
- werden die geänderten Wörter und Zeichen gezählt, und
- erscheint eine Markierung „bearbeitet" an den geänderten Feldern.
Eine Schaltfläche „Zurücksetzen" stellt das Original je Feld wieder her. Mit edit_final_answer: true erhält die endgültige Antwort einen eigenen Editor. Nichts ist verpflichtend: Eine unbearbeitete Trace erzeugt einfach kein Trainingspaar.
Konfiguration
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer| Option | Standard | Beschreibung |
|---|---|---|
steps_key | steps | Instanzfeld, das die Schrittliste enthält. |
step_text_key | action | Standardmäßig bearbeitbares Feld je Schritt. |
editable_fields | [step_text_key] | Welche Schrittfelder einen Editor erhalten, z. B. [action, thought]. |
show_diff | true | Zeigt das Live-Diff auf Wortebene an. |
show_edit_distance | true | Zeigt die geänderten Wörter und Zeichen an. |
allow_reset | true | Schaltfläche „Auf Original zurücksetzen" je Feld. |
require_reason_on_edit | false | Eingabefeld „Grund für die Bearbeitung" je Feld. |
edit_final_answer | false | Fügt einen Editor für die endgültige Antwort hinzu. |
final_answer_key | final_answer | Instanzfeld, das die endgültige Antwort enthält. |
Datenformat
Das Schema liest die Schritte aus der Instanz unter steps_key. Jeder Schritt ist ein Objekt, dessen Felder (action, thought usw.) bearbeitet werden können; reine Zeichenketten-Schritte werden als step_text_key-Feld bearbeitet.
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}Export
Führe den trajectory_correction-Exporter aus. Er schreibt drei Dateien:
trajectory_corrections.json— jeder Datensatz: dieoriginal_trace, die rekonstruiertecorrected_traceund je Feld dieeditsmit Editierdistanzen und Gründen.trajectory_sft.jsonl— eine Zeile pro bearbeiteter Trace:{"prompt": <task>, "completion": <corrected_trace>}.trajectory_dpo.jsonl— eine Zeile pro bearbeiteter Trace:{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}.
Unbearbeitete Traces werden gezählt, aber von SFT/DPO ausgeschlossen, da das Training auf einer unveränderten Trajektorie nichts bringt; die Anzahl der übersprungenen Traces erscheint in den Exportstatistiken. Bei mehreren Annotatoren ergibt jeder Annotator, der eine Trace bearbeitet hat, einen SFT/DPO-Datensatz.
Hinweise und Einschränkungen
- Das Diff erfolgt auf Wortebene. Bei codeähnlichen Tool-Aufrufen ohne Leerzeichen kann ein einzelnes Token selbst bei einer Korrektur von einem Zeichen als vollständig geändert erscheinen; der Zeichendistanzzähler ist das präzise Signal.
- Kombiniere es mit der Bewertung auf Schrittebene, wenn du auch eine Korrektheit je Schritt oder eine Fehlertaxonomie für dieselbe Trace möchtest.
Verwandt
- Trace-Auswertung mit drei Bereichen — schreibgeschützte Ansicht von Denken, Aufrufen und Antwort
- Agentische Annotation — Muster zur Anzeige und Auswertung von Agenten-Traces
- Exportformate — die vollständige Exporter-Referenz
Implementierungsdetails findest du in der Quelldokumentation.