Multimodale Agenten-Evaluation
Evaluiere Agenten, die über Text hinaus handeln, Computer-Use- und GUI-Agenten, Sprachassistenten, Video- und Dokument-Agenten. Potato ergänzt zweckgebaute Schemas für GUI-Trajektorien mit Klick-Grounding, Voll-Duplex-Sprachzeitleisten, zeitliche Video-Verortung mit Live-IoU, Fehler-Tagging an ausgerichteten Transkripten, verschränktes multimodales Reasoning und Tabellengitter-Struktur.
Agenten handeln zunehmend in Modalitäten jenseits von Text: Sie steuern GUIs, sehen Videos und führen gesprochene Gespräche. Jede Modalität braucht eine Review-Oberfläche, die ein einfaches Text-Widget nicht bieten kann, einen Screenshot mit dem Klick des Agenten, eine zweispurige Sprachzeitleiste, einen Video-Scrubber mit Gold-Intervallen. Potato ergänzt Annotationsschemas, die für diese Traces gebaut sind, neben seinen bestehenden Anzeigen für Bild, Audio und Video.
Jedes Schema leitet seine Schritte, Turns oder Segmente zur Renderzeit aus dem Trace ab, und jedes wird mit einem lauffähigen Beispiel unter examples/agent-traces/ ausgeliefert.
GUI-/Computer-Use-Trajektorie (gui_trajectory)
Evaluiere einen Computer-Use-, GUI- oder OS-Agenten Schritt für Schritt (OSWorld, NeurIPS 2024; ScreenSpot-Pro; AndroidWorld). Jeder Schritt zeigt den Screenshot, den der Agent sah, und die Aktion, die er ausführte; die annotierende Person beurteilt die Aktion (korrekt / falsches Element / falsche Aktion / halluziniert). Wenn ein Schritt Klick-Koordinaten enthält, zeigt ein Grounding-Marker auf dem Screenshot, ob der Klick auf dem richtigen Element gelandet ist.
 Prüfe jeden Computer-Use-Schritt: Aktionskorrektheit plus Klick-Grounding auf dem Screenshot
Prüfe jeden Computer-Use-Schritt: Aktionskorrektheit plus Klick-Grounding auf dem Screenshot
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot # field on each step holding an image URL / data-URI
action_key: action # field holding the action text
coord_space: normalized # normalized (0..1) | pixels — for the x/y grounding marker
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Jeder Schritt kann screenshot, action und optional x/y (oder ein verschachteltes click: {x, y}) bereitstellen. Gespeichert als Liste von {index, step, verdict, notes}.
Sprache / Voll-Duplex-Interaktion (voice_interaction)
Annotiere ein gesprochenes Mensch↔Agent-Gespräch auf Sprecherwechsel und Barge-in-Handhabung (Full-Duplex-Bench, 2025). Eine zweispurige Zeitleiste (Nutzer-Spur plus Agenten-Spur) platziert jeden Turn nach seiner Start- und Endzeit und hebt Überlappungsbereiche hervor, in denen beide Sprecher gleichzeitig reden. Die annotierende Person klassifiziert jede Überlappung (Agent sollte antworten / sollte fortfahren / Rückmeldelaut / unklar) und bewertet den Sprecherwechsel insgesamt; das Quell-Audio wird inline abgespielt, wenn es bereitgestellt wird.
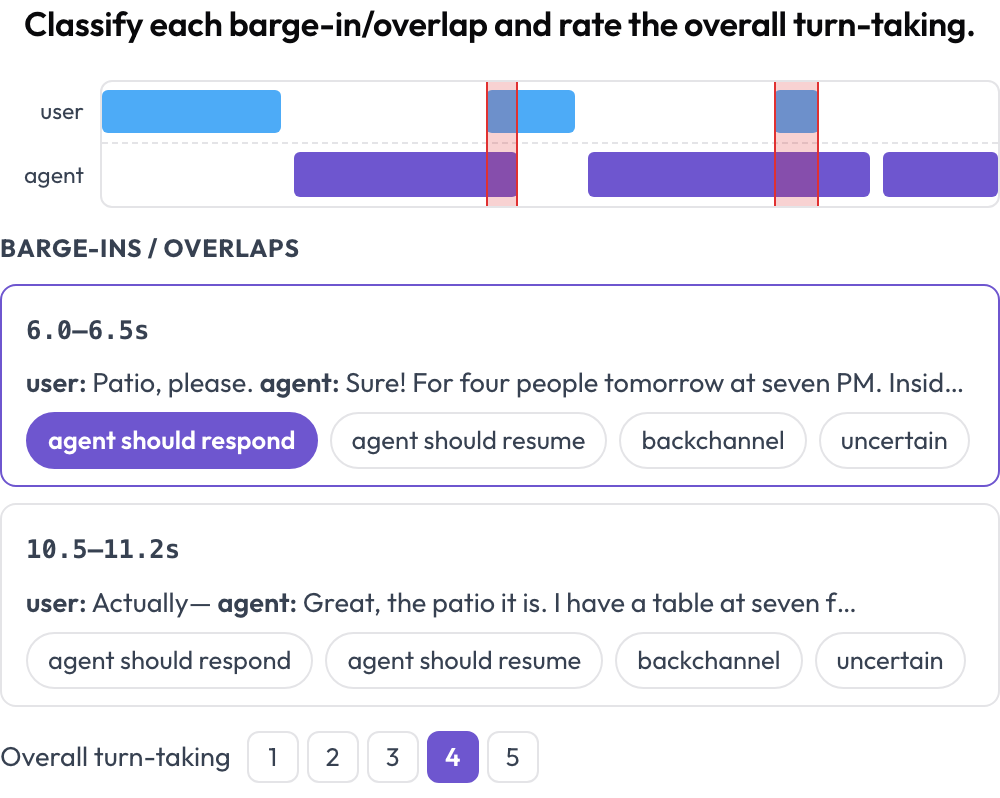 Eine zweispurige Sprachzeitleiste mit Barge-in-Erkennung und Sprecherwechsel-Bewertung
Eine zweispurige Sprachzeitleiste mit Barge-in-Erkennung und Sprecherwechsel-Bewertung
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns # list of {speaker, start, end, text} (seconds)
speaker_key: speaker
user_speakers: [user, human, caller] # everything else is treated as the agent
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5
# audio_key: audio # optional per-instance audio URL to enable the playerÜberlappungen zwischen Turns verschiedener Sprecher werden zur Renderzeit berechnet. Gespeichert als {"overlaps": {idx: label}, "rating": int}.
Zeitliche Video-Verortung (temporal_grounding)
Markiere Ereignis-Zeitintervalle in einem Video zur Evaluation der zeitlichen Verortung (TimeScope, 2025; ET-Bench). Für jeden Ereignis-Prompt setzt die annotierende Person das Gold-[start, end], indem sie den Abspielkopf erfasst oder Sekunden eintippt. Wenn die Daten ein vom Modell vorhergesagtes Intervall enthalten, aktualisieren sich ein Live-IoU und eine zweibalkige Mini-Zeitleiste (vorhergesagt vs. Gold), während du anpasst. Das ist zweckgebaut für die Bewertung von Vorhersage-vs.-Gold-Verortung, verschieden vom allgemeinen Segment-Labeling.
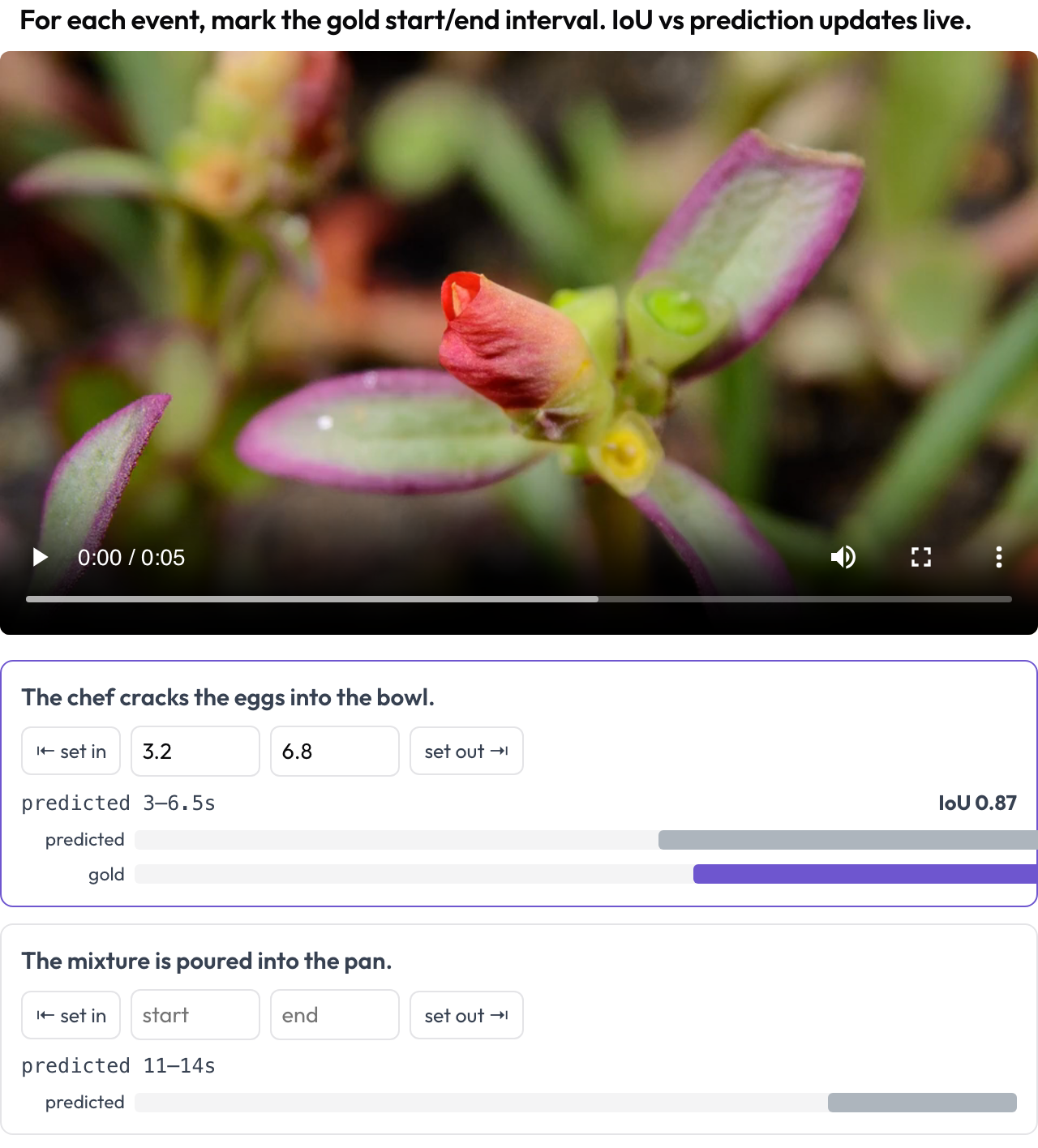 Markiere Gold-Ereignisintervalle im Video mit einem Live-IoU gegenüber der Vorhersage des Modells
Markiere Gold-Ereignisintervalle im Video mit einem Live-IoU gegenüber der Vorhersage des Modells
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video # per-instance video URL
events_key: events # list of {prompt, predicted: {start, end}} (predicted optional)
# duration: 120 # optional fixed timeline scale (else inferred from the video)Gespeichert als {"events": {idx: {start, end}}}.
Sprachfehler an ausgerichteten Transkripten (speech_transcript)
Annotiere ein zeitlich ausgerichtetes Sprachtranskript Segment für Segment auf ASR-/TTS- und Sprachqualitätsfehler (Speak & Improve, 2025). Jedes Segment {start, end, text, speaker?} ist eine Karte, die seinen Zeitstempel und Text zeigt; die annotierende Person taggt Fehler (ASR-Fehler / TTS-Artefakt / Falschaussprache / Sprechunflüssigkeit) und kann das korrigierte Transkript eintippen. Das ist die segmentweise Ergänzung zur Sprecherwechsel-Ansicht in voice_interaction.
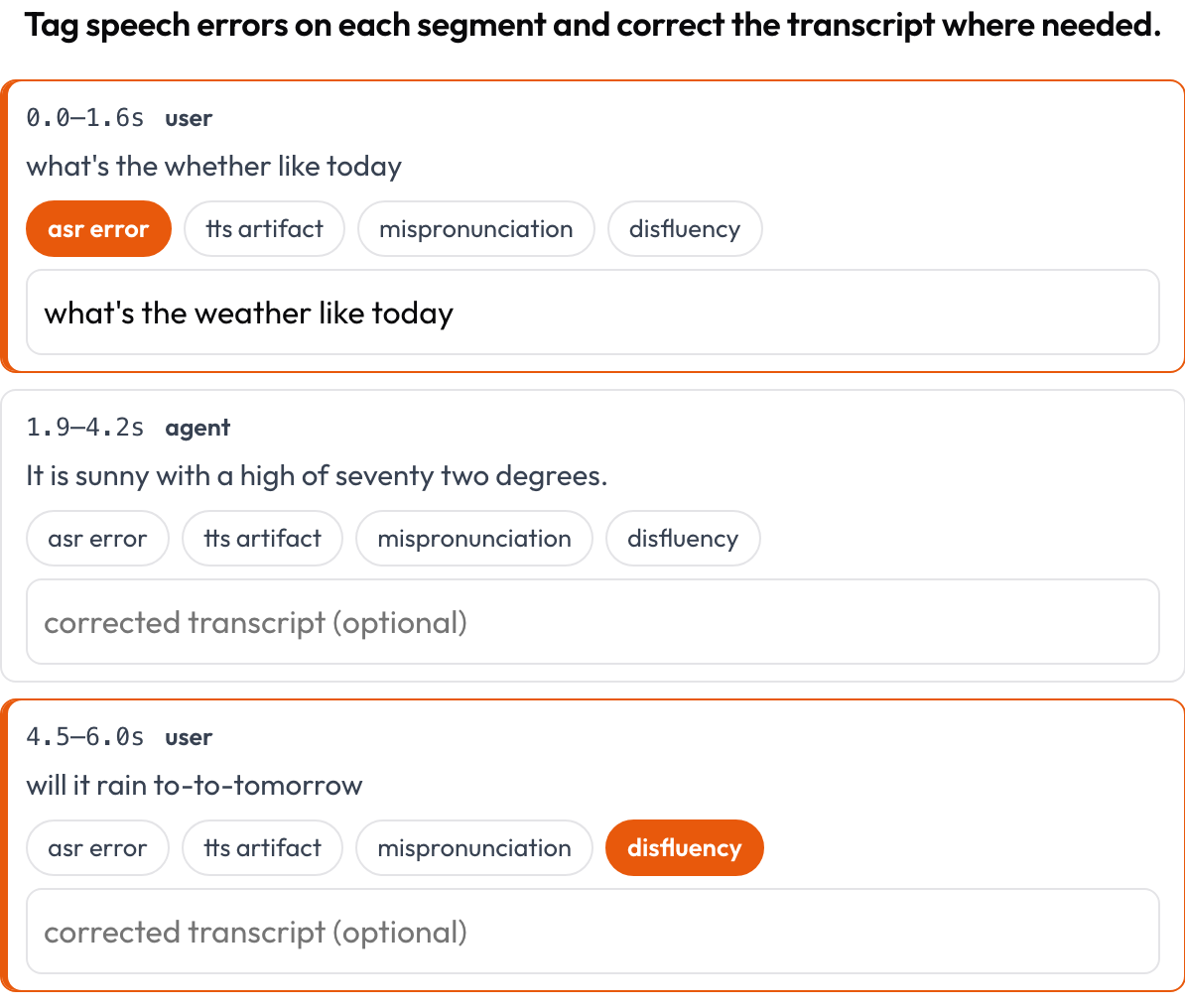 Tagge ASR-/TTS-/Aussprachefehler pro Segment und korrigiere das Transkript inline
Tagge ASR-/TTS-/Aussprachefehler pro Segment und korrigiere das Transkript inline
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments # list of {start, end, text, speaker?}
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true
# audio_key: audio # optional per-item audio URL to enable the playerGespeichert als Liste von {index, start, end, errors, correction}.
Verschränktes multimodales Reasoning (multimodal_reasoning)
Bewerte eine verschränkte Text-↔-Bild-↔-Tool-↔-Aktion-Reasoning-Spur Schritt für Schritt (Multimodal RewardBench 2, 2025; Zebra-CoT). Jeder Schritt ist ein typisierter Block, inline nach seinem Typ gerendert; die annotierende Person beurteilt die Kohärenz jedes Schritts, folgt das Reasoning aus dem Bild und den vorherigen Schritten, oder ist das Visuelle halluziniert?
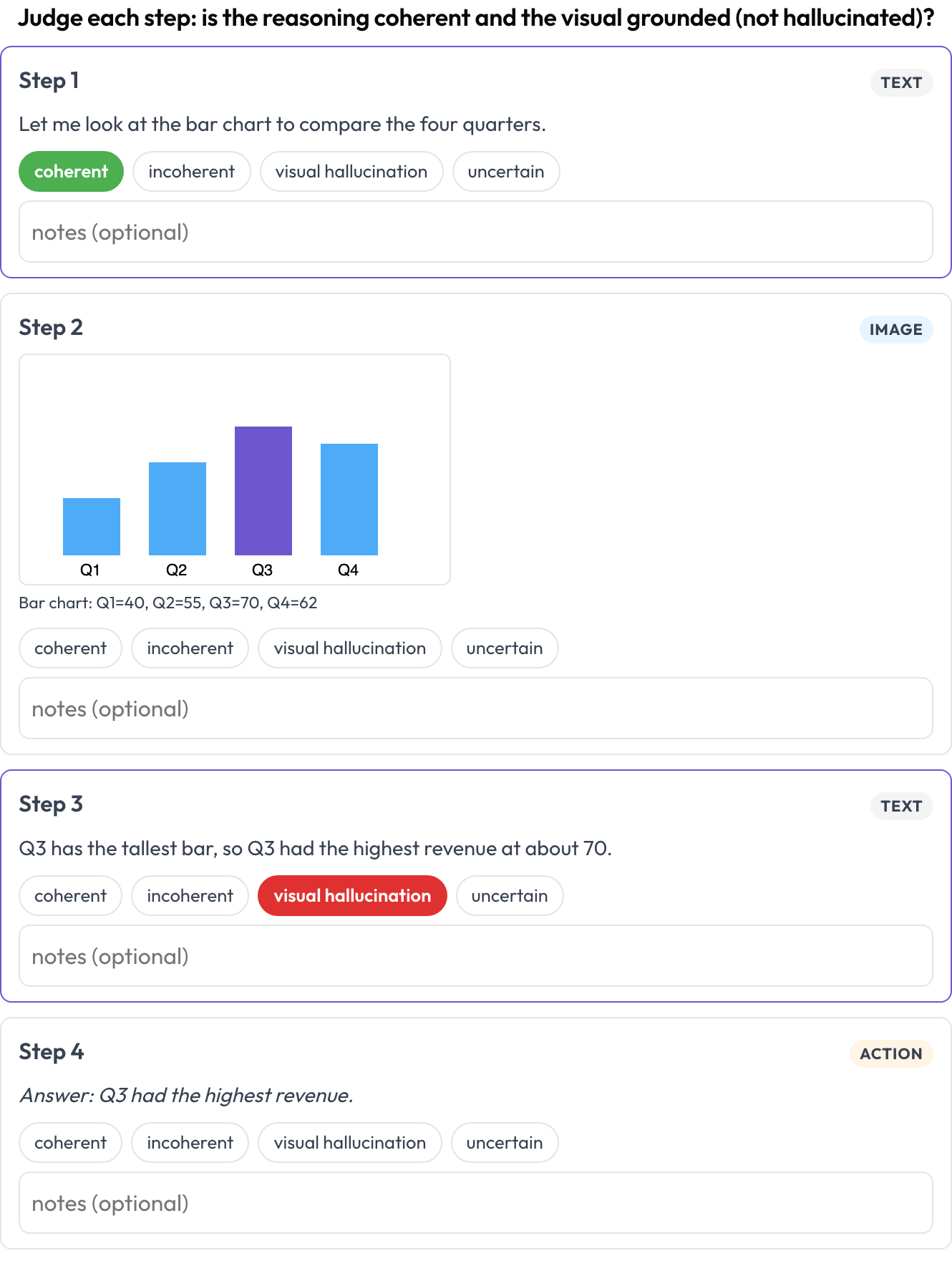 Bewerte jeden Schritt einer Text-Bild-Tool-Reasoning-Spur auf Kohärenz und visuelle Halluzination
Bewerte jeden Schritt einer Text-Bild-Tool-Reasoning-Spur auf Kohärenz und visuelle Halluzination
annotation_schemes:
- annotation_type: multimodal_reasoning
name: reasoning_review
description: "Judge each step: coherent reasoning and grounded visuals?"
steps_key: steps
type_key: type # each step's 'type': text | image | tool | action (inferred if absent)
verdict_options: [coherent, incoherent, visual_hallucination, uncertain]Jeder Schritt kann text/content, image/image_url (+caption) oder tool/args enthalten. Gespeichert als Liste von {index, step, type, verdict, notes}.
Tabellengitter-Struktur (table_grid)
Annotiere die Zellstruktur eines Tabellenbildes, das dokumentspezifische Teil, das einfache Bounding-Boxen nicht erfassen können (OmniDocBench, CVPR 2025; RealHiTBench). Die annotierende Person setzt die Gitterabmessungen und klickt Zellen an, um ihre Rolle zu markieren (Daten / Spaltenüberschrift / Zeilenüberschrift / leer). Region-Boxen pro Seite werden bereits abgedeckt, indem man Bildannotation pro Seite ausführt, daher konzentriert sich dieses Schema auf die Struktur, die diese Boxen nicht ausdrücken können.
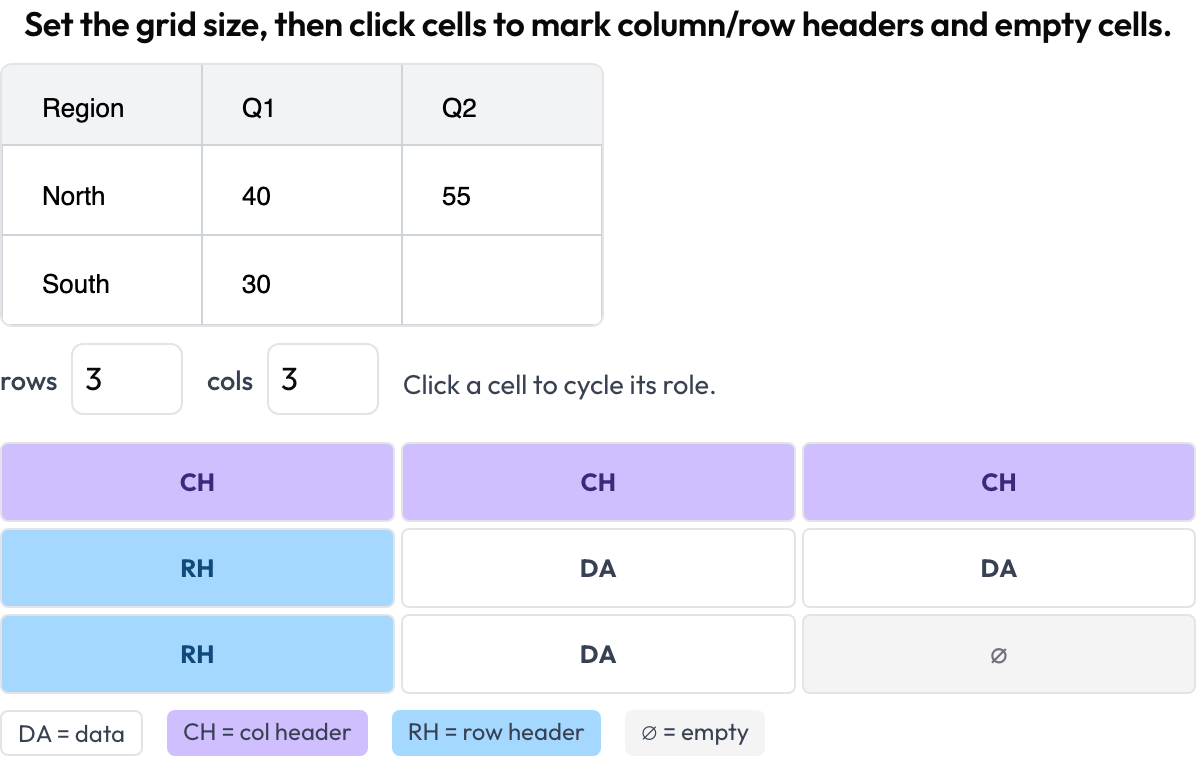 Annotiere die Zellstruktur von Dokumenttabellen: Spalten- und Zeilenüberschriften, Daten und leere Zellen
Annotiere die Zellstruktur von Dokumenttabellen: Spalten- und Zeilenüberschriften, Daten und leere Zellen
annotation_schemes:
- annotation_type: table_grid
name: structure
description: "Set the grid size, then click cells to mark headers and empty cells."
image_key: image # per-instance table image URL / data-URI
rows_key: rows # optional initial dims from the data
cols_key: cols
roles: [data, col_header, row_header, empty] # click cycles through theseGespeichert als {rows, cols, cells: {"r,c": role}}, wobei nur nicht-data-Zellen behalten werden.
Verwandt
- Evaluation von Multi-Agenten-Teams — Interaktionsgraph, Übergaben und Team-Scorecards
- Web-Agenten-Evaluation — Screenshot-und-Aktion-Web-Agenten
- Wie man KI-Agenten evaluiert — die Ebenen der Agenten-Evaluation
- Agentische Annotation — Konfiguration und Ingestion der Trace-Anzeige
Implementierungsdetails findest du in der Quelldokumentation.