Evaluation von Multi-Agenten-Teams
Annotiere Multi-Agenten-Systeme nach Teamstruktur statt als flaches Transkript. Potato ergänzt einen anklickbaren Agenten-Interaktionsgraphen, agentenübergreifende Fehlerzuordnung, Übergabe-Review, Scorecards pro Agent und pro Team, eine Zeitleiste für Tool-Konkurrenz und das Tagging von emergentem Verhalten.
Ein Multi-Agenten-System scheitert anders als ein einzelner Agent: Der Bruch entsteht zwischen Agenten, bei einer Übergabe oder in der Art, wie das Team organisiert war. Es zu evaluieren bedeutet, Ergebnisse dem jeweiligen Agenten, dem jeweiligen Schritt und der jeweiligen Übergabe zuzuordnen, statt nur ein flaches Transkript zu bewerten. Potato ergänzt eine Reihe von Annotationsoberflächen, die genau dafür gebaut sind: einen anklickbaren Interaktionsgraphen, Fehlerzuordnung, Übergabe-Review, Scorecards pro Agent und pro Team, eine Zeitleiste für Tool-Konkurrenz und spurenübergreifendes Tagging von emergentem Verhalten.
Diese bauen auf der Agenten-Trace-Anzeige und der MAST-Fehlertaxonomie auf. Jedes Schema leitet seine Agenten, Schritte und Übergaben zur Renderzeit aus dem Trace selbst ab, sodass die annotierende Person aus dem auswählt, was im Lauf tatsächlich passiert ist.
Interaktionsgraph (agent_interaction_graph)
Der gesamte Lauf wird als gerichteter Graph dargestellt: Knoten sind Agenten, Kanten sind die Nachrichten- und Übergabeübergänge zwischen ihnen (dickere Kanten bedeuten häufigere), automatisch aus dem Trace angeordnet. Die annotierende Person klickt einen Knoten an, um den kritischen Pfad zu markieren, und klickt eine Kante an, um sie normal → kritisch → problematisch durchzuschalten. Das ist die klarste Antwort auf "Wie sehe ich die Struktur eines Multi-Agenten-Laufs", und es ist eine Oberfläche, die allgemeine Annotationswerkzeuge nicht bieten.
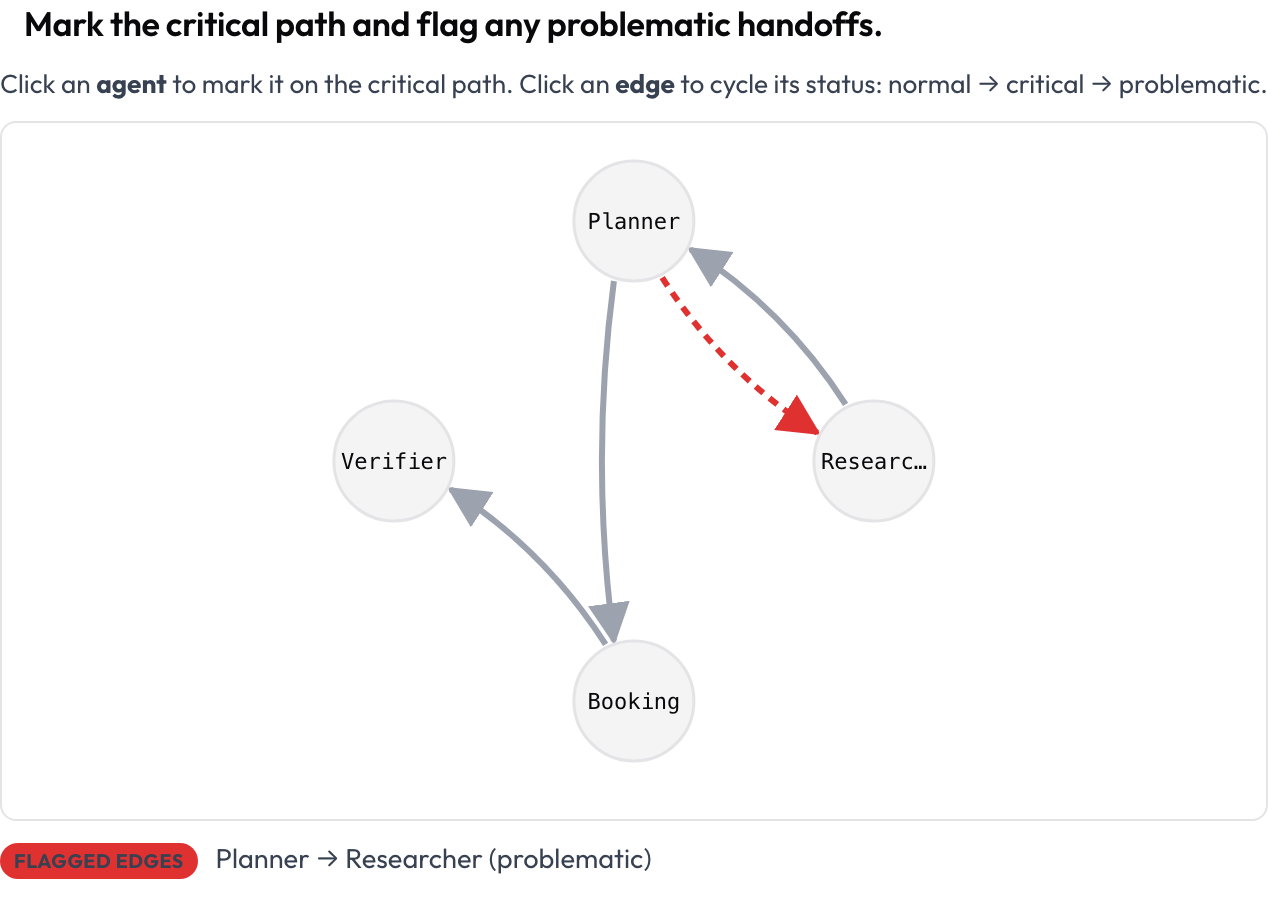 Markiere den kritischen Pfad und kennzeichne problematische Übergaben auf einem anklickbaren Agenten-Interaktionsgraphen
Markiere den kritischen Pfad und kennzeichne problematische Übergaben auf einem anklickbaren Agenten-Interaktionsgraphen
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentGespeichert als {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}. Jeder Knoten und jede Kante ist per Tastatur fokussierbar, und eine Live-Textzusammenfassung listet kritische Knoten und markierte Kanten auf, sodass Bedeutung nie allein über Farbe transportiert wird.
Agentenübergreifende Fehlerzuordnung (failure_attribution)
Wenn ein Team scheitert, ist das nützliche Label das Tripel (verantwortlicher Agent, ausschlaggebender Schritt, Grund) aus der Literatur zur Fehlerzuordnung (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, der Who&When-Datensatz). Das Agenten-Dropdown und die Schrittauswahl werden aus den eigenen Turns des Traces befüllt, sodass die annotierende Person den Fehler einem realen Agenten und einem realen Schritt zuordnet.
 Ordne einen Multi-Agenten-Fehler dem verantwortlichen Agenten, dem ausschlaggebenden Schritt und dem Grund zu
Ordne einen Multi-Agenten-Fehler dem verantwortlichen Agenten, dem ausschlaggebenden Schritt und dem Grund zu
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the traceGespeichert als {"responsible_agent", "decisive_step", "reason"}. Kombiniere es mit einem radio-Outcome-Schema (success/failure), sodass die Zuordnung nur bei gescheiterten Läufen ausgelöst wird.
Übergabe-Review (handoff_review)
Jede Übergabe, bei der ein Agent die Kontrolle an einen anderen abgibt, wird zu einem erstklassigen Objekt, das annotiert werden kann. Überall dort, wo sich der handelnde Agent zwischen aufeinanderfolgenden Turns ändert, gibt Potato eine Übergabekarte A → B aus; die annotierende Person kennzeichnet agentenübergreifende Fehlausrichtung und bewertet die Übergabequalität. Die Fehlermodi sind in MASTs Inter-Agent-Kategorie und im "Echoing"-Phänomen verankert (Zhang et al., 2025).
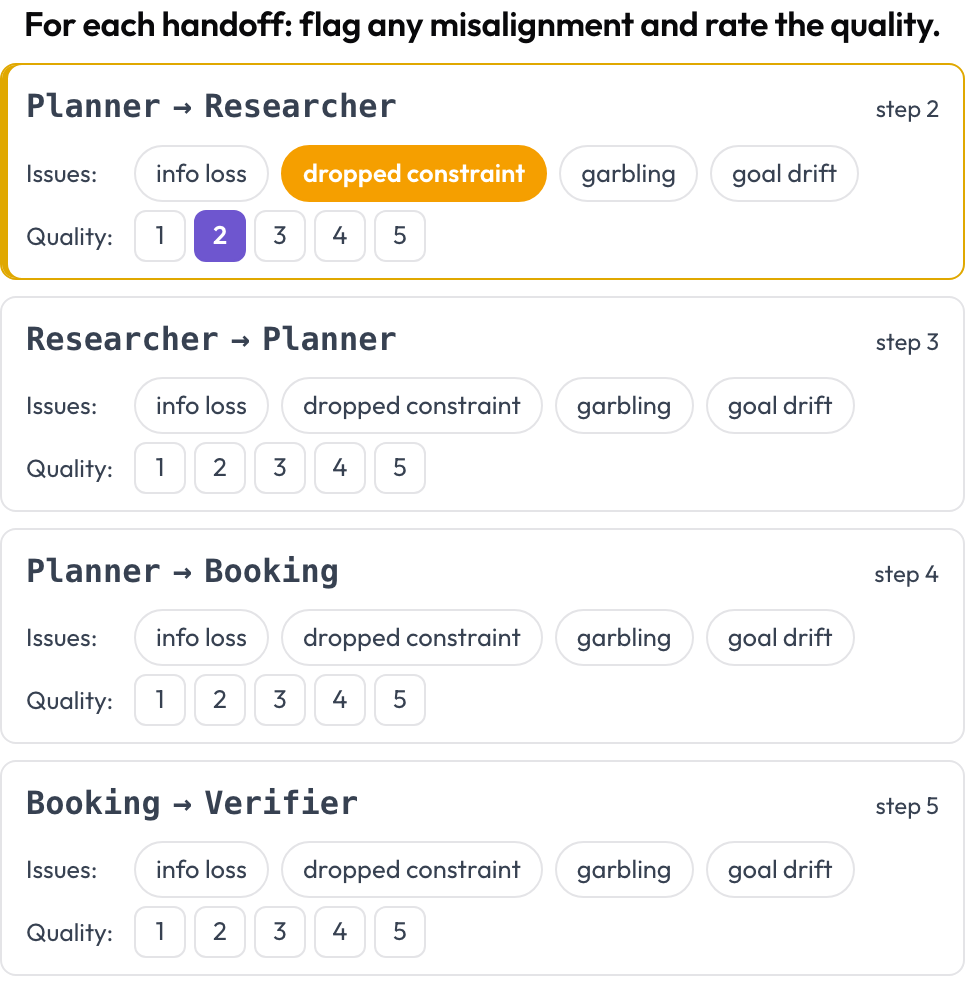 Kennzeichne agentenübergreifende Fehlausrichtung bei jeder Übergabe und bewerte deren Qualität
Kennzeichne agentenübergreifende Fehlausrichtung bei jeder Übergabe und bewerte deren Qualität
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Übergaben werden zur Renderzeit aus dem Trace abgeleitet, es gibt also kein manuelles Setup. Gespeichert als Liste von {index, step, from, to, flags, quality}.
Scorecard pro Agent und pro Team (agent_scorecard)
Bewerte einen Lauf auf zwei Ebenen gleichzeitig (MultiAgentBench, Zhou et al., ACL 2025): Jeder Agent erhält Werte pro Dimension (Rollentreue, Beitrag, Koordination), das Team erhält Werte für die gemeinsamen Dimensionen, und optionale Meilensteine werden abgehakt. Die Agentenzeilen stammen aus den eigenen Turns des Traces, sodass die Matrix mit denen übereinstimmt, die tatsächlich beteiligt waren.
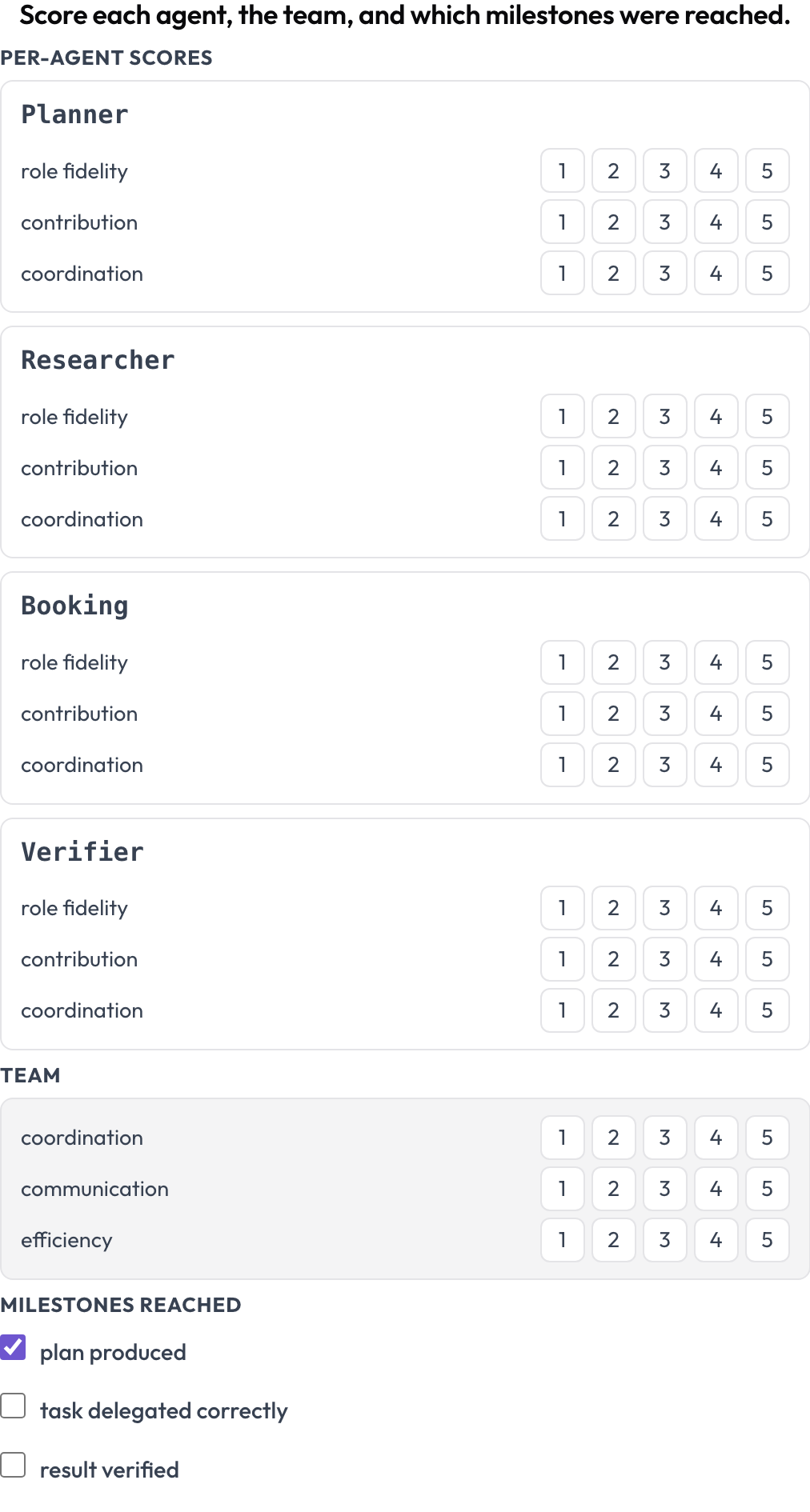 Bewerte jeden Agenten nach Rollentreue, Beitrag und Koordination, plus das Team und die Meilensteine
Bewerte jeden Agenten nach Rollentreue, Beitrag und Koordination, plus das Team und die Meilensteine
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optionalGespeichert als {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}.
Zeitleiste für Tool-/Ressourcen-Konkurrenz (tool_contention)
Gleichzeitige Tool- und Ressourcennutzung über Agenten hinweg wird auf einer mehrspurigen Zeitleiste dargestellt, eine Spur pro Agent. Bereiche, in denen zwei Aufrufe dieselbe Ressource zu überlappenden Zeiten berühren, werden spurenübergreifend hervorgehoben und zur Klassifikation aufgelistet: Deadlock, zirkuläres Warten, Race Condition oder harmlos (DPBench, 2026). So fängst du Nebenläufigkeitsfehler ab, die ein Turn-für-Turn-Transkript verbirgt.
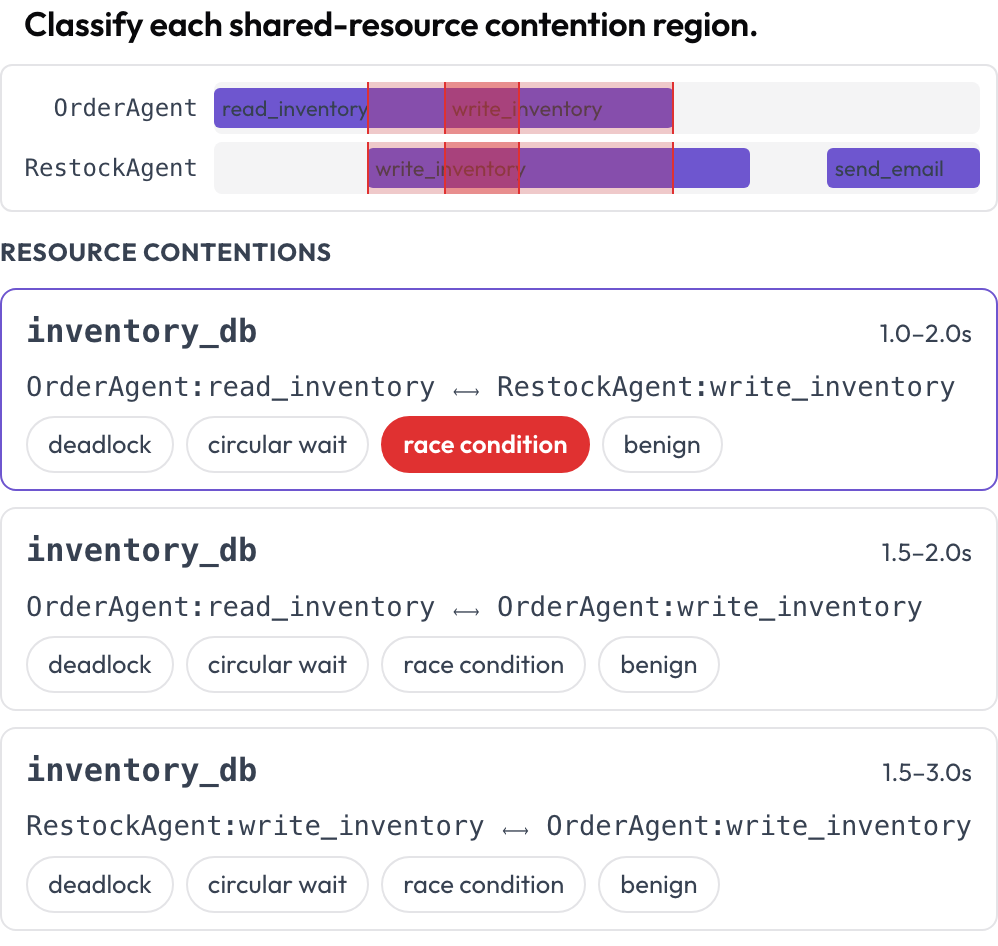 Erkenne Deadlocks und Race Conditions auf einer Tool-Aufruf-Zeitleiste pro Agent
Erkenne Deadlocks und Race Conditions auf einer Tool-Aufruf-Zeitleiste pro Agent
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]Konkurrenzbereiche werden zur Renderzeit berechnet (gleiche resource, überlappendes Intervall). Gespeichert als {"contentions": {idx: label}}.
Spurenübergreifendes emergentes Verhalten (emergent_behavior)
Manche Fehler sind kollektiv: Kollusion, Gruppendenken, kaskadierende Fehler, Rollendrift. Ein emergentes Verhalten ist keine zusammenhängende Textspanne; es ist eine Menge beteiligter Turns, möglicherweise von verschiedenen Agenten. Für jedes Verhalten hakt die annotierende Person die beteiligten Turns ab und fügt eine Notiz hinzu, eine spurenübergreifende Spanne, ausgedrückt als Turn-Menge.
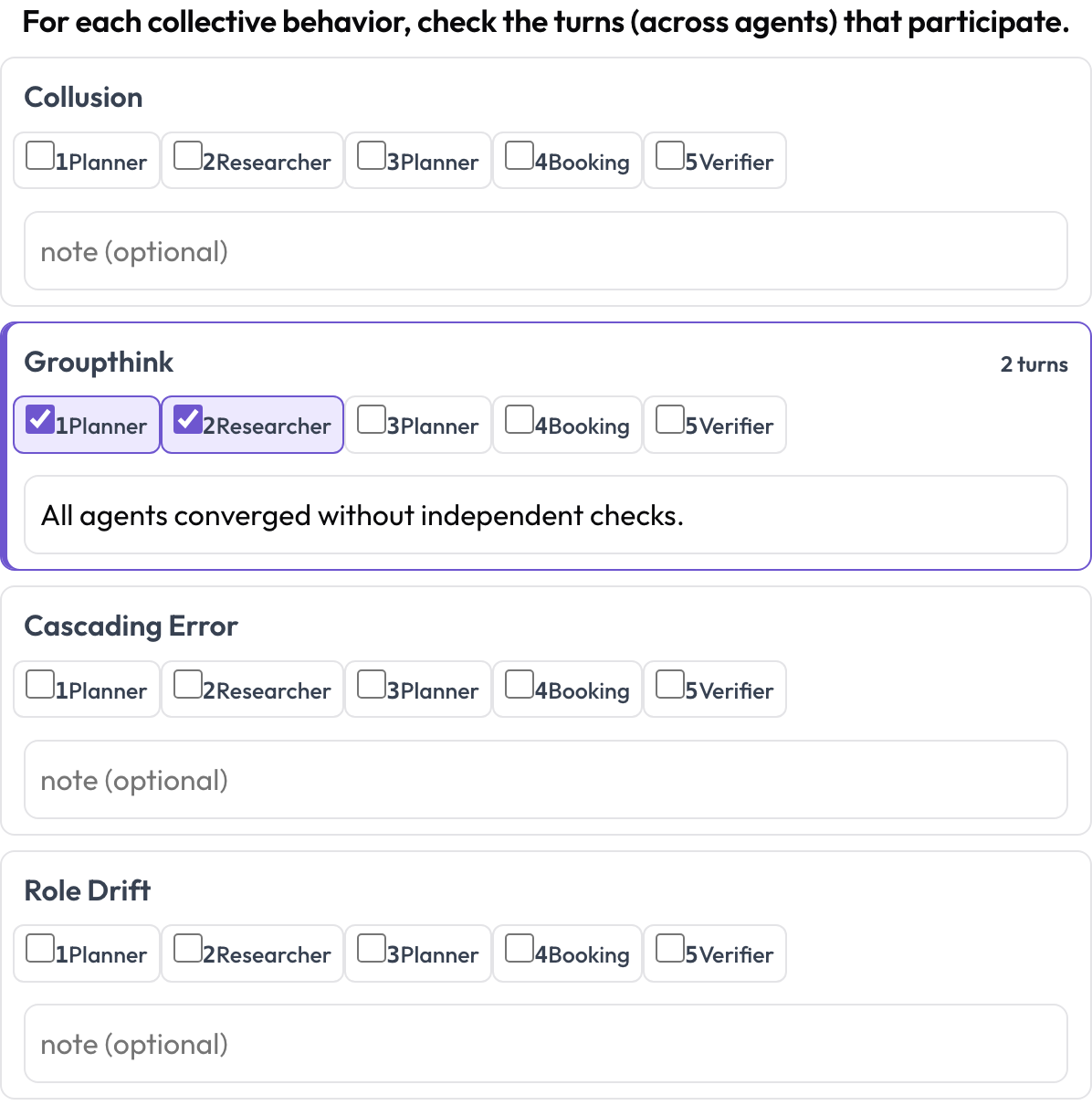 Tagge Kollusion, Gruppendenken und kaskadierende Fehler über Agenten und Turns hinweg
Tagge Kollusion, Gruppendenken und kaskadierende Fehler über Agenten und Turns hinweg
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueGespeichert als {behavior: {turns: [idx...], note}}, wobei nur nicht-leere Verhalten behalten werden.
Tool-Aufruf-Review (tool_call_review)
Beurteile jeden Tool- oder Funktionsaufruf einzeln: Wurde das richtige Tool gewählt, waren die Argumente korrekt, war die Reihenfolge richtig (in Anlehnung an BFCL v4 / MCPMark)? Tool-Aufrufe werden zur Renderzeit aus den Trace-Schritten extrahiert; die tool_calls, tool_call oder action jedes Schritts wird zu einer Karte mit dem Tool-Namen und schön formatierten Argumenten.
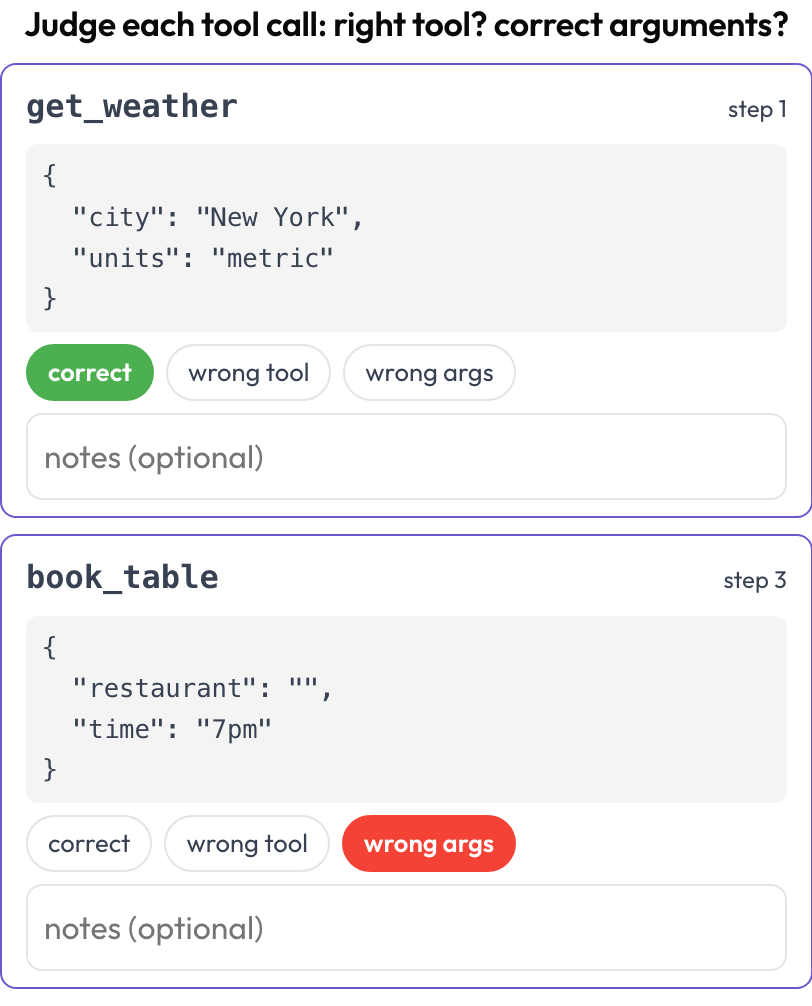 Beurteile jeden Tool-Aufruf: richtiges Tool, korrekte Argumente, richtige Reihenfolge
Beurteile jeden Tool-Aufruf: richtiges Tool, korrekte Argumente, richtige Reihenfolge
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizableGespeichert als Liste von {index, step, tool, verdict, notes}.
MAST-Tagging auf Schritt-Granularität
Du brauchst kein neues Schema, um die 14-modige MAST-Fehlertaxonomie (Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025) an den genauen Schritt (und damit den handelnden Agenten) zu binden, an dem ein Fehler aufgetreten ist. Konfiguriere das bestehende Schema trajectory_eval pro Schritt mit den MAST-Modi als seinen error_types, gruppiert nach den drei MAST-Kategorien. Kombiniere es mit failure_attribution und handoff_review für volle Abdeckung.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]Die Orchestrierungsperspektive wählen
Die Orchestrierungsarchitektur dominiert oft das Ergebnis eines Laufs, daher lohnt es sich, sie als erstklassiges Label zu erfassen. Es ist kein neues Schema nötig: Ein radio bestätigt oder korrigiert das Muster des Laufs, das dann sowohl die Evaluationsperspektive als auch das Layout des Traces steuert (sequenziell → Spuren, hierarchisch → Baum, Gruppenchat → Board).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueVerwandt
- Multimodale Agenten-Evaluation — Schemas für GUI-, Sprach-, Video- und Dokument-Agenten
- Annotieren von Agenten-Trajektorien — Fehlerannotation pro Schritt
- Wie man KI-Agenten evaluiert — die Ebenen der Agenten-Evaluation
- Agentische Annotation — Konfiguration und Ingestion der Trace-Anzeige
Implementierungsdetails findest du in der Quelldokumentation.