Übereinstimmung Judge ↔ Mensch
Messen Sie, wie gut ein LLM-Judge mit Ihren menschlichen Gold-Labels übereinstimmt. Potato führt den Judge über annotierte Instanzen aus, berechnet Cohens Kappa, eine Konfusionsmatrix und eine Liste der Abweichungen und verfolgt die Übereinstimmung, während Sie die Bewertungsvorgabe verfeinern.
Die Judge-Übereinstimmung misst und justiert, wie gut ein LLM-Judge mit Ihren menschlichen Gold-Labels übereinstimmt. Potato führt einen konfigurierbaren LLM-as-a-judge über Instanzen aus, die Ihre Annotatoren bereits gelabelt haben, berechnet Cohens κ, eine Konfusionsmatrix und eine Liste der Abweichungen und verfolgt κ, während Sie die Bewertungsvorgabe des Judges bearbeiten. Bei aktiviertem Inline-Modus erscheint das Urteil des Judges während der Annotation neben dem menschlichen Label, zusammen mit einem laufenden κ.
Das ist die übliche Schleife „Richten Sie Ihren Judge an etwa 100–200 Gold-Labels aus", wie sie Werkzeuge wie LangSmith Align Evals und Evidently verwenden: menschliche Labels sammeln, den Judge ausführen, Abweichungen prüfen, die Bewertungsvorgabe verfeinern und erneut ausführen, bis die Übereinstimmung hoch ist.
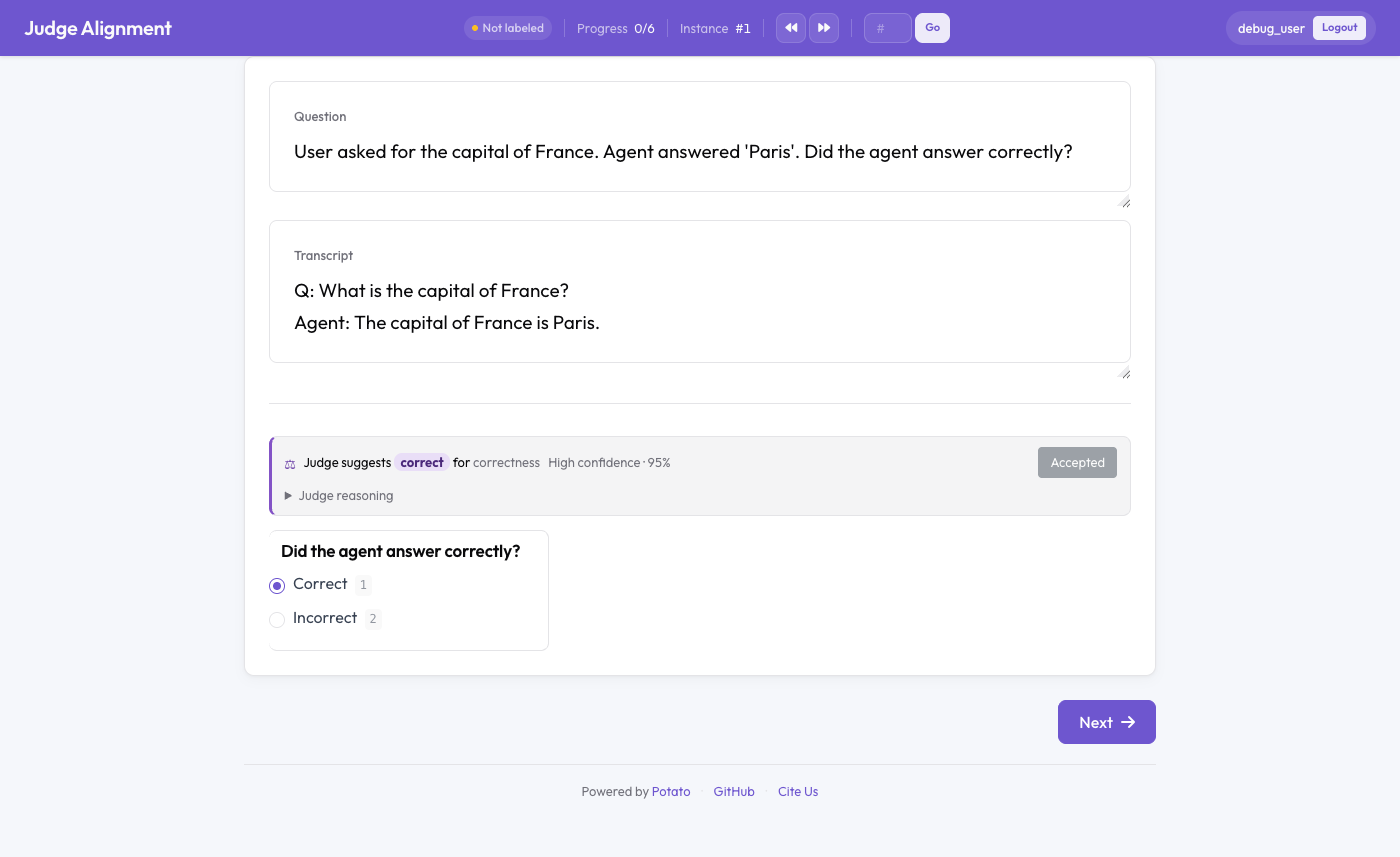 Urteil eines LLM-Judges neben der menschlichen Annotation mit einem laufenden Kappa
Urteil eines LLM-Judges neben der menschlichen Annotation mit einem laufenden Kappa
Konfiguration
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict existsDer Geltungsbereich umfasst kategoriale Einzelauswahl-Schemata (radio, select, likert). Ist judge_alignment.schemas gesetzt, werden nur diese Schemata beurteilt; andernfalls alle kategorialen Schemata.
Den Judge ausführen
Führen Sie den Judge über die Admin-API aus. Vorhersagen werden pro Prompt-Version zwischengespeichert, sodass erneute Durchläufe günstig sind:
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Zum Kalibrieren übergeben Sie eine bearbeitete Bewertungsvorgabe. Das erzeugt eine neue Prompt-Version, sodass Sie κ über mehrere Runden hinweg vergleichen können:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'Der Übereinstimmungsbericht
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
Senden Sie den Header X-API-Key. Pro Schema zeigt der Bericht:
- Cohens κ mit einer Interpretation nach Landis–Koch, die Übereinstimmungsrate und die Anzahl der verglichenen Instanzen.
- Eine Konfusionsmatrix (Zeilen sind der menschliche Goldstandard, Spalten sind der Judge).
- Eine Abweichungstabelle mit der Instanz, dem menschlichen Label, dem Judge-Label, der Konfidenz und der Begründung des Judges.
- Eine Prompt-Versionshistorie mit dem mittleren κ pro Version, sodass der Kalibrierungsfortschritt sichtbar ist.
Der menschliche Goldstandard ist die Mehrheitsentscheidung über alle Annotatoren für jede Instanz.
Inline-Modus
Bei inline.enabled zeigt jede Annotationsseite das zwischengespeicherte Urteil des Judges für die Instanz an – sein Label, seine Konfidenz und seine ausklappbare Begründung – zusammen mit einem laufenden κ für die Aufgabe. „Akzeptieren" füllt die passende Auswahl aus. Jeder menschliche Speichervorgang erfasst einen Mensch↔Judge-Vergleich, der in die laufende Übereinstimmung einfließt. Setzen Sie compute_on_demand: true, um den Judge live aufzurufen, wenn kein zwischengespeichertes Urteil vorliegt; andernfalls führen Sie den Stapel vorab aus, was schneller ist.
Hinweise und Einschränkungen
- Die Kalibrierung ist in dieser Version manuell: Bewertungsvorgabe bearbeiten und erneut ausführen. Automatische Prompt-Optimierung liegt außerhalb des Umfangs.
- Der Geltungsbereich umfasst kategoriale Einzelauswahl-Schemata. Das Beurteilen von Spannen (span) und Freitext ist zukünftige Arbeit.
- Führen Sie den Judge über einen fokussierten Goldsatz von etwa 100–200 gelabelten Instanzen aus, um ein stabiles κ zu erhalten.
Verwandt
- LLM-as-Judge-Kalibrierung — Multi-Judge-Kalibrierung mit menschlich-blinder Validierung und Kalibrierungsfehler
- Triage-Warteschlange — leiten Sie die informativsten Elemente zuerst an Menschen weiter
- Leitfaden zur Inter-Annotator-Übereinstimmung — die Kappa-Metriken im Detail
Implementierungsdetails finden Sie in der Quelldokumentation.