Modifica delle traiettorie per SFT/DPO
Gli annotatori riscrivono i passaggi di una traccia di agente per correggere un passaggio di ragionamento errato, sistemare una chiamata a strumento o rafforzare la risposta finale, e Potato esporta ogni coppia originale/corretta come obiettivi di fine-tuning supervisionato e coppie di preferenza DPO.
Lo schema trajectory_edit consente agli annotatori di riscrivere i passaggi di una traccia di agente ed esporta ogni correzione come dati di addestramento. Correggi un passaggio di ragionamento errato, sistema una chiamata a strumento con un refuso o rafforza la risposta finale, e Potato salva la traiettoria corretta accanto a quella originale. L'esportatore trajectory_correction trasforma poi ogni coppia (original, corrected) in obiettivi di fine-tuning supervisionato (SFT) e in coppie di preferenza di ottimizzazione diretta delle preferenze (DPO).
Questo rende Potato uno strumento di produzione di dati di addestramento, e non solo di valutazione. È la controparte in modalità modifica del punteggio a livello di passaggio: invece di valutare una traiettoria, gli annotatori la riparano, e la riparazione diventa un segnale di apprendimento.
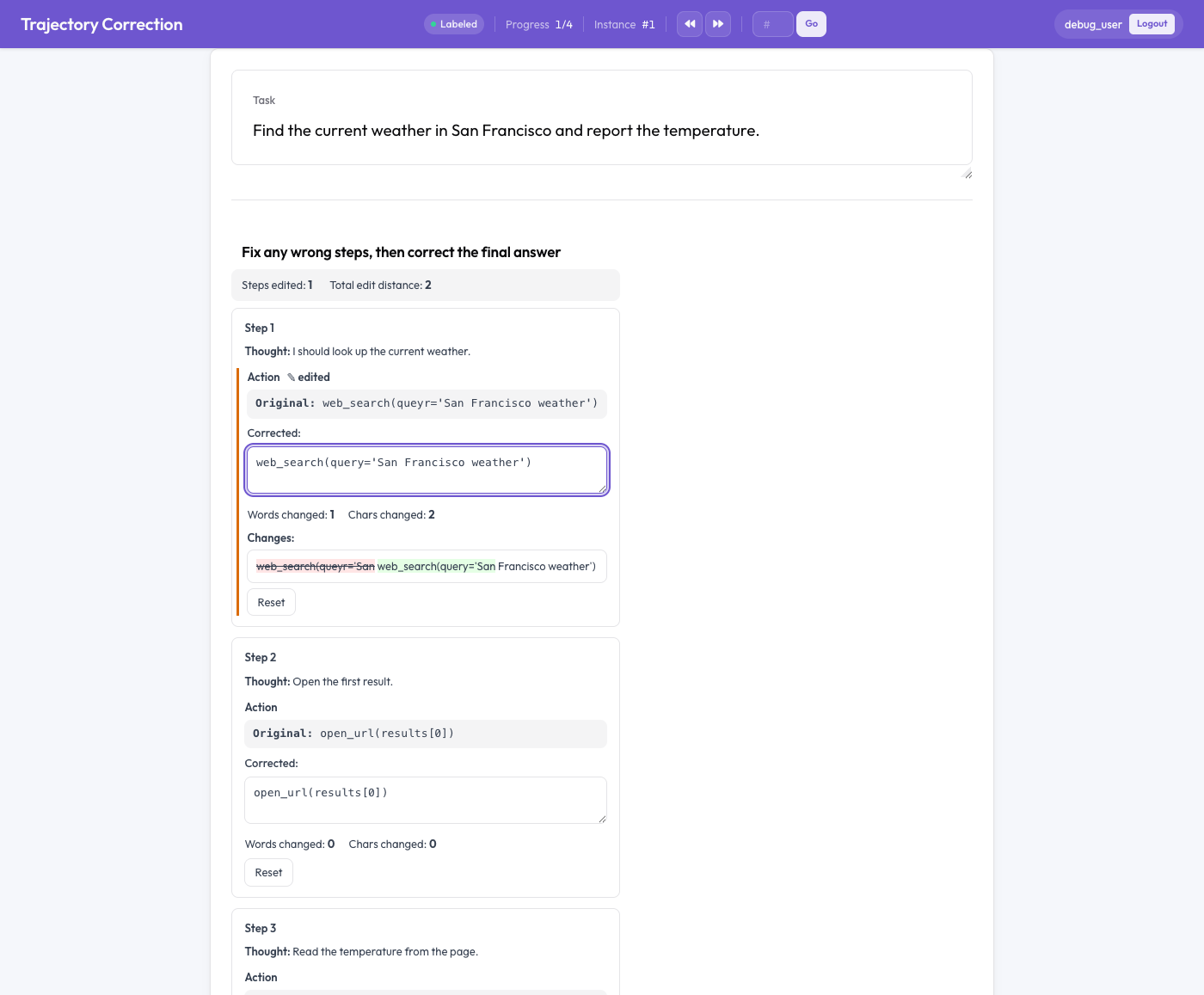 Un passaggio di agente mostrato con un originale in sola lettura e un riquadro corretto modificabile con un diff a livello di parola
Un passaggio di agente mostrato con un originale in sola lettura e un riquadro corretto modificabile con un diff a livello di parola
Avvio rapido
Esegui l'esempio incluso dalla radice del repository:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000Come funziona
Ogni passaggio di agente viene reso come una scheda che mostra il testo originale (in sola lettura) e un riquadro corretto modificabile precompilato con l'originale. Mentre l'annotatore digita:
- un diff in tempo reale a livello di parola evidenzia gli inserimenti (in verde) e le eliminazioni (barrato in rosso),
- vengono conteggiate le parole e i caratteri modificati, e
- compare un contrassegno «modificato» sui campi modificati.
Un pulsante «Ripristina» riporta l'originale per ogni campo. Con edit_final_answer: true la risposta finale ottiene un proprio editor. Niente è obbligatorio: una traccia non modificata semplicemente non produce alcuna coppia di addestramento.
Configurazione
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer| Opzione | Predefinito | Descrizione |
|---|---|---|
steps_key | steps | Campo dell'istanza che contiene l'elenco dei passaggi. |
step_text_key | action | Campo modificabile predefinito per ogni passaggio. |
editable_fields | [step_text_key] | Quali campi del passaggio ottengono un editor, ad es. [action, thought]. |
show_diff | true | Mostra il diff in tempo reale a livello di parola. |
show_edit_distance | true | Mostra le parole e i caratteri modificati. |
allow_reset | true | Pulsante «Ripristina all'originale» per ogni campo. |
require_reason_on_edit | false | Campo di immissione «motivo della modifica» per ogni campo. |
edit_final_answer | false | Aggiunge un editor per la risposta finale. |
final_answer_key | final_answer | Campo dell'istanza che contiene la risposta finale. |
Formato dei dati
Lo schema legge i passaggi dall'istanza sotto steps_key. Ogni passaggio è un oggetto i cui campi (action, thought e così via) possono essere modificati; i passaggi costituiti da una semplice stringa vengono modificati come campo step_text_key.
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}Esportazione
Esegui l'esportatore trajectory_correction. Scrive tre file:
trajectory_corrections.json— ogni record: l'original_trace, ilcorrected_tracericostruito e, per ciascun campo, leeditscon distanze di modifica e motivi.trajectory_sft.jsonl— una riga per ogni traccia modificata:{"prompt": <task>, "completion": <corrected_trace>}.trajectory_dpo.jsonl— una riga per ogni traccia modificata:{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}.
Le tracce non modificate vengono conteggiate ma escluse da SFT/DPO, poiché addestrare su una traiettoria invariata non aggiunge nulla; il conteggio di quelle ignorate compare nelle statistiche di esportazione. Con più annotatori, ogni annotatore che ha modificato una traccia produce un record SFT/DPO.
Note e limitazioni
- Il diff è a livello di parola. Per le chiamate a strumenti simili a codice e senza spazi, un singolo token può apparire come interamente modificato anche per una correzione di un solo carattere; il contatore della distanza tra caratteri è il segnale preciso.
- Abbinalo al punteggio a livello di passaggio se desideri anche la correttezza per ogni passaggio o una tassonomia degli errori sulla stessa traccia.
Correlati
- Valutazione della traccia a tre pannelli — vista in sola lettura di ragionamento, chiamate e risposta
- Annotazione agentica — schemi di visualizzazione e valutazione delle tracce di agente
- Formati di esportazione — il riferimento completo dell'esportatore
Per i dettagli di implementazione, consulta la documentazione sorgente.