Valutazione di team multi-agente
Annota i sistemi multi-agente per struttura del team, non come una trascrizione piatta. Potato aggiunge un grafo di interazione tra agenti cliccabile, l'attribuzione delle failure tra agenti, la revisione degli handoff, scorecard per singolo agente e per team, una timeline di contesa delle risorse e il tagging dei comportamenti emergenti.
Un sistema multi-agente fallisce in modo diverso da un singolo agente: il problema nasce tra gli agenti, durante un handoff, o nel modo in cui il team è stato organizzato. Valutarlo significa attribuire gli esiti a quale agente, quale passo e quale handoff, non solo assegnare un punteggio a una trascrizione piatta. Potato aggiunge un insieme di superfici di annotazione costruite per questo: un grafo di interazione cliccabile, l'attribuzione delle failure, la revisione degli handoff, scorecard per singolo agente e per team, una timeline di contesa degli strumenti e il tagging dei comportamenti emergenti tra le corsie.
Queste si basano sul display delle tracce di agenti e sulla tassonomia delle failure MAST. Ogni schema ricava i suoi agenti, passi e handoff dalla traccia stessa al momento del rendering, così l'annotatore sceglie tra ciò che è realmente accaduto nel run.
Grafo di interazione (agent_interaction_graph)
L'intero run viene reso come un grafo diretto: i nodi sono gli agenti, gli archi sono le transizioni di messaggio e handoff tra di loro (archi più spessi indicano una maggiore frequenza), disposti automaticamente a partire dalla traccia. L'annotatore clicca un nodo per segnare il percorso critico e clicca un arco per farlo passare ciclicamente normale → critico → problematico. Questa è la risposta più chiara a "come faccio a vedere la struttura di un run multi-agente", ed è una superficie che gli strumenti di annotazione generici non offrono.
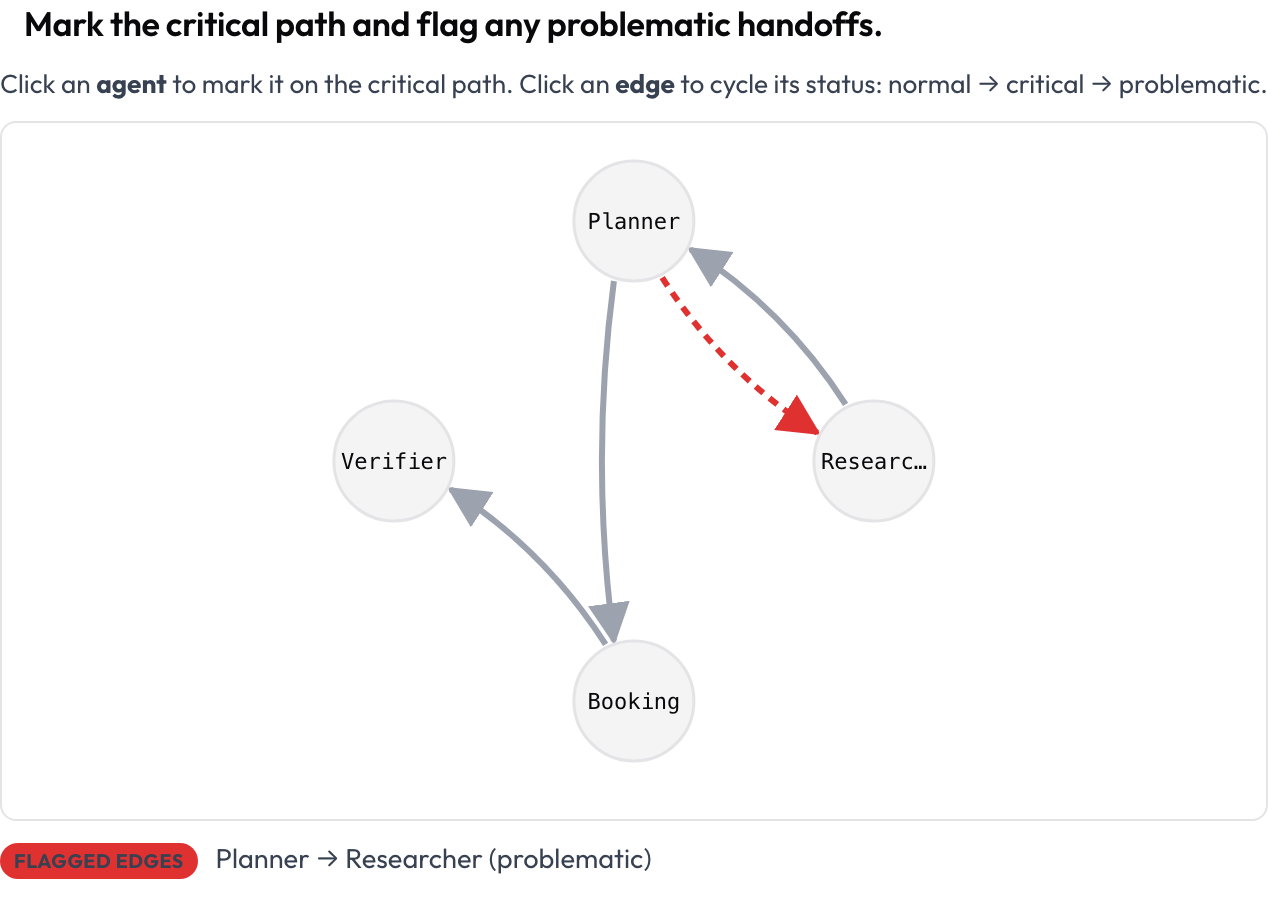 Segna il percorso critico e contrassegna gli handoff problematici su un grafo di interazione tra agenti cliccabile
Segna il percorso critico e contrassegna gli handoff problematici su un grafo di interazione tra agenti cliccabile
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentMemorizzato come {"critical_nodes": [...], "edges": {"A->B": "problematic", ...}}. Ogni nodo e arco è raggiungibile da tastiera e un riepilogo testuale dal vivo elenca i nodi critici e gli archi segnalati, così il significato non è mai veicolato solo dal colore.
Attribuzione delle failure tra agenti (failure_attribution)
Quando un team fallisce, l'etichetta utile è la tripla (agente responsabile, passo decisivo, motivo) dalla letteratura sull'attribuzione delle failure (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, il dataset Who&When). Il menu a tendina degli agenti e il selettore dei passi sono popolati dai turni stessi della traccia, così l'annotatore attribuisce la failure a un agente reale e a un passo reale.
 Attribuisci una failure multi-agente all'agente responsabile, al passo decisivo e al motivo
Attribuisci una failure multi-agente all'agente responsabile, al passo decisivo e al motivo
annotation_schemes:
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent
# agents: [Planner, Coder, Reviewer] # optional static list instead of deriving from the traceMemorizzato come {"responsible_agent", "decisive_step", "reason"}. Abbinalo a uno schema di esito radio (success/failure) così l'attribuzione si attiva solo sui run falliti.
Revisione degli handoff (handoff_review)
Ogni handoff, un agente che passa il controllo a un altro, diventa un oggetto di prima classe da annotare. Ovunque l'agente che agisce cambi tra turni consecutivi, Potato emette una scheda di handoff A → B; l'annotatore segnala il disallineamento tra agenti e valuta la qualità dell'handoff. Le modalità di failure sono ancorate alla categoria inter-agente di MAST e al fenomeno dell'"echoing" (Zhang et al., 2025).
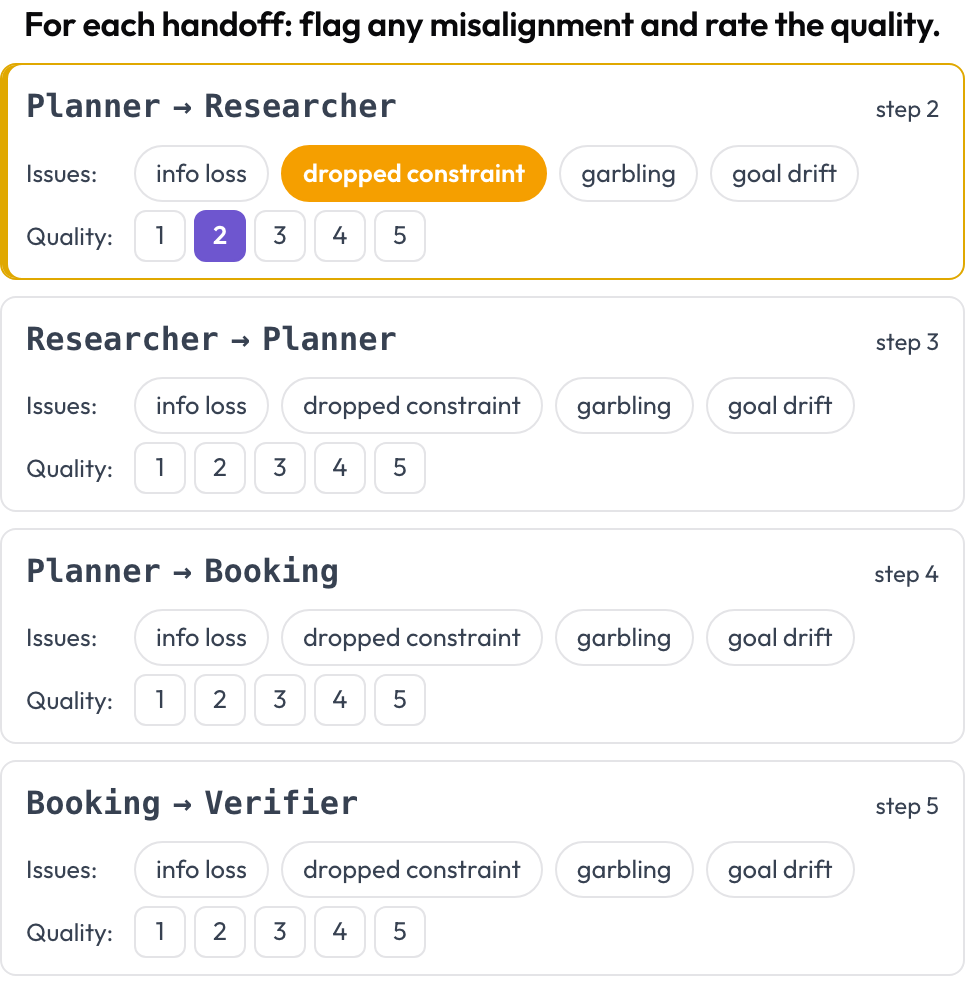 Segnala il disallineamento tra agenti su ogni handoff e valutane la qualità
Segnala il disallineamento tra agenti su ogni handoff e valutane la qualità
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Gli handoff sono ricavati dalla traccia al momento del rendering, quindi non c'è alcuna configurazione manuale. Memorizzati come una lista di {index, step, from, to, flags, quality}.
Scorecard per singolo agente e per team (agent_scorecard)
Valuta un run su due livelli contemporaneamente (MultiAgentBench, Zhou et al., ACL 2025): ogni agente ottiene punteggi per dimensione (fedeltà al ruolo, contributo, coordinamento), il team ottiene punteggi sulle dimensioni condivise e le milestone opzionali vengono spuntate. Le righe degli agenti provengono dai turni stessi della traccia, così la matrice corrisponde a chi ha realmente partecipato.
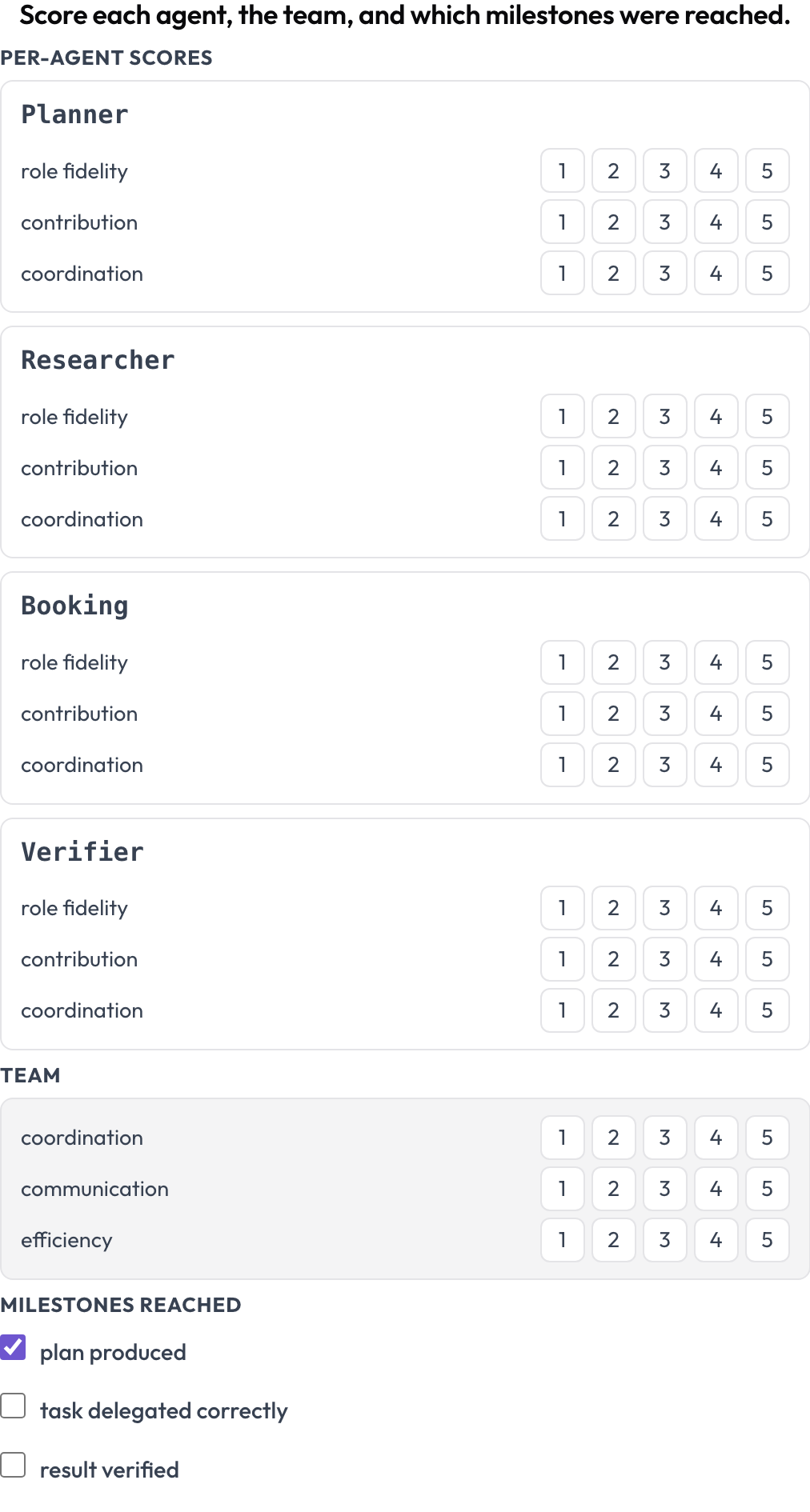 Valuta ogni agente su fedeltà al ruolo, contributo e coordinamento, oltre al team e alle milestone
Valuta ogni agente su fedeltà al ruolo, contributo e coordinamento, oltre al team e alle milestone
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified] # optionalMemorizzato come {"agents": {name: {dim: score}}, "team": {dim: score}, "milestones": {name: bool}}.
Timeline di contesa di strumenti / risorse (tool_contention)
L'uso concorrente di strumenti e risorse tra agenti viene reso su una timeline multi-corsia, una corsia per agente. Le regioni in cui due chiamate toccano la stessa risorsa in tempi sovrapposti sono evidenziate tra le corsie ed elencate per la classificazione: deadlock, attesa circolare, race condition o benigna (DPBench, 2026). È così che cogli le failure di concorrenza che una trascrizione per turno nasconde.
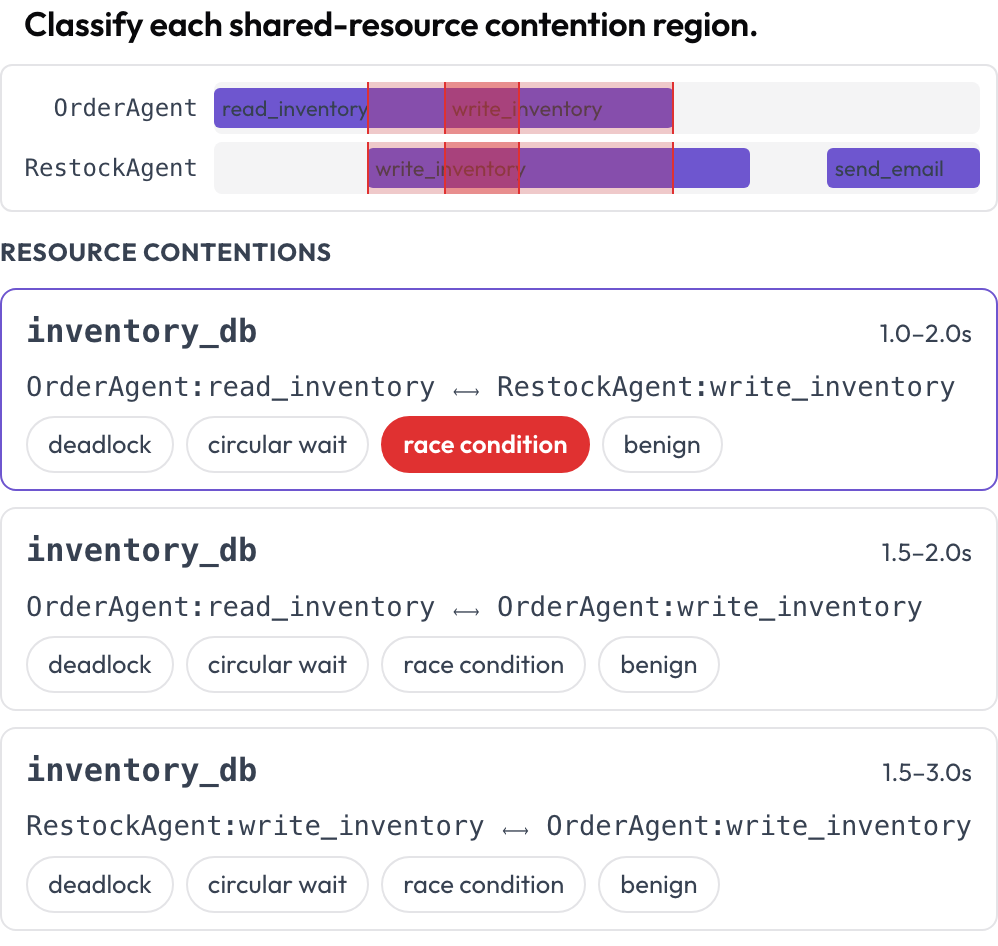 Individua deadlock e race condition su una timeline delle chiamate di strumenti per agente
Individua deadlock e race condition su una timeline delle chiamate di strumenti per agente
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls # list of {agent, tool, start, end, resource}
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]Le regioni di contesa sono calcolate al momento del rendering (stessa resource, intervallo sovrapposto). Memorizzate come {"contentions": {idx: label}}.
Comportamento emergente tra corsie (emergent_behavior)
Alcune failure sono collettive: collusione, groupthink, errori a cascata, deriva del ruolo. Un comportamento emergente non è una porzione di testo contigua; è un insieme di turni partecipanti, possibilmente da agenti diversi. Per ogni comportamento l'annotatore spunta i turni che vi partecipano e aggiunge una nota, una porzione tra corsie espressa come insieme di turni.
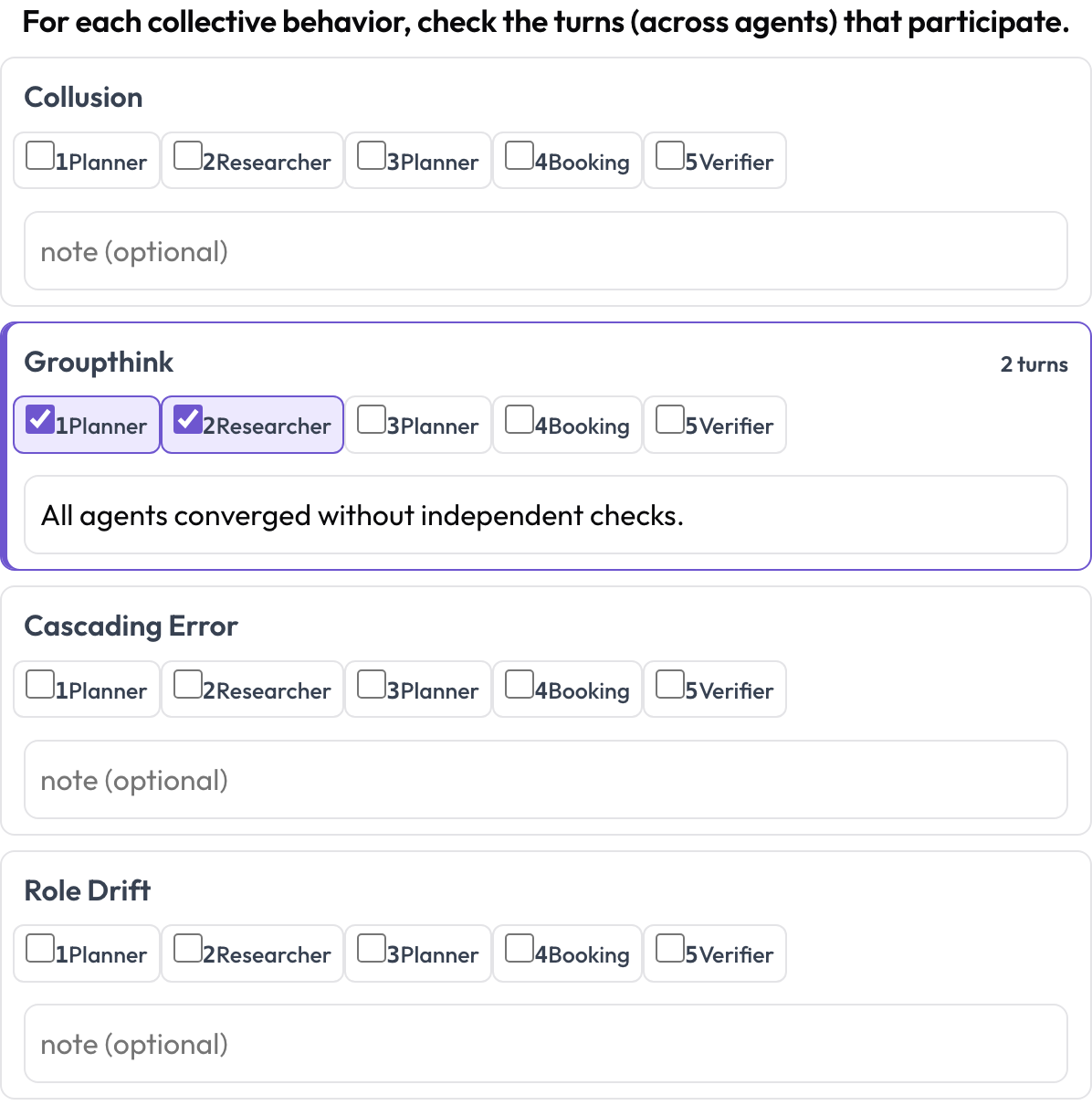 Tagga collusione, groupthink ed errori a cascata tra agenti e turni
Tagga collusione, groupthink ed errori a cascata tra agenti e turni
annotation_schemes:
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns (across agents) that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueMemorizzato come {behavior: {turns: [idx...], note}}, mantenendo solo i comportamenti non vuoti.
Revisione delle chiamate di strumenti (tool_call_review)
Giudica ogni chiamata di strumento o funzione singolarmente: è stato scelto lo strumento giusto, gli argomenti erano corretti, l'ordine era giusto (rispecchiando BFCL v4 / MCPMark)? Le chiamate di strumenti vengono estratte dai passi della traccia al momento del rendering; i tool_calls, tool_call o action di ogni passo diventano una scheda con il nome dello strumento e gli argomenti formattati in modo leggibile.
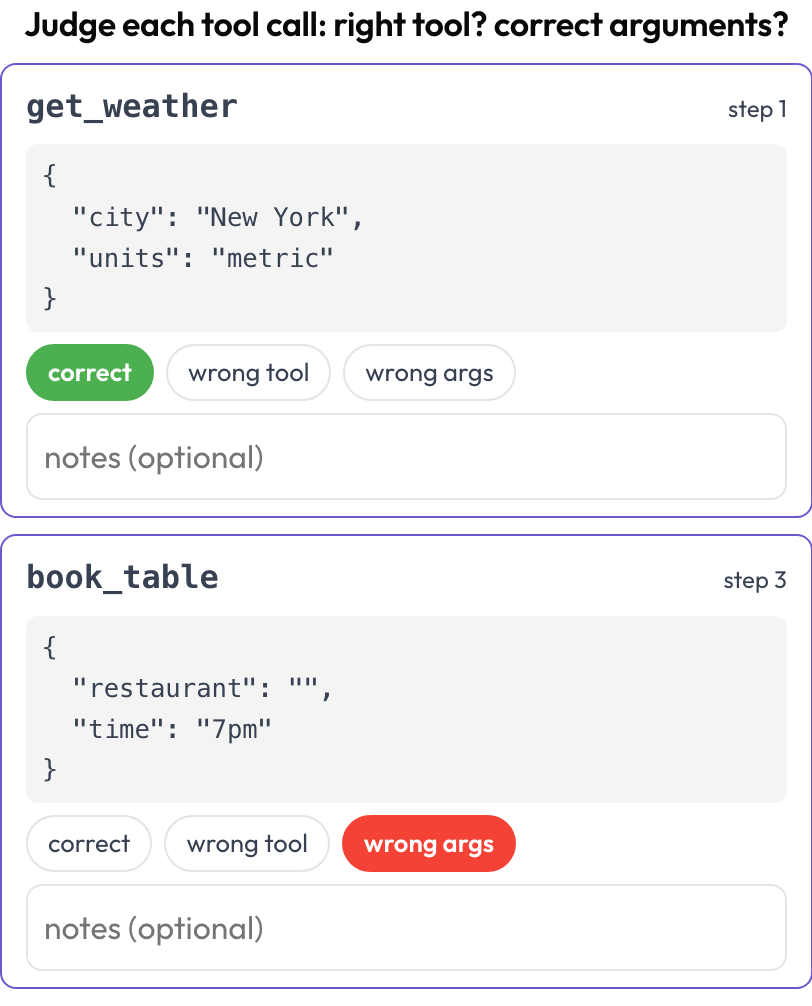 Giudica ogni chiamata di strumento: strumento giusto, argomenti corretti, ordine giusto
Giudica ogni chiamata di strumento: strumento giusto, argomenti corretti, ordine giusto
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order] # customizableMemorizzato come una lista di {index, step, tool, verdict, notes}.
Tagging MAST a granularità di passo
Non hai bisogno di un nuovo schema per legare la tassonomia delle failure MAST a 14 modalità (Cemri et al., Why Do Multi-Agent LLM Systems Fail?, 2025) al passo esatto (e quindi all'agente che agisce) in cui si è verificata una failure. Configura lo schema per passo esistente trajectory_eval con le modalità MAST come suoi error_types, raggruppate per le tre categorie MAST. Abbinalo a failure_attribution e handoff_review per una copertura completa.
annotation_schemes:
- annotation_type: trajectory_eval
name: mast_steps
description: "Tag each step with the MAST failure mode(s) it exhibits."
steps_key: steps
step_text_key: content
error_types:
- name: "Specification & System Design"
subtypes: ["Disobey task specification", "Disobey role specification", "Step repetition", "Loss of conversation history", "Unaware of termination conditions"]
- name: "Inter-Agent Misalignment"
subtypes: ["Conversation reset", "Fail to ask for clarification", "Task derailment", "Information withholding", "Ignored other agent's input", "Reasoning-action mismatch"]
- name: "Task Verification & Termination"
subtypes: ["Premature termination", "No or incomplete verification", "Incorrect verification"]Scegliere la lente di orchestrazione
L'architettura di orchestrazione spesso domina l'esito di un run, quindi vale la pena catturarla come etichetta di prima classe. Non serve alcun nuovo schema: un radio conferma o corregge il pattern del run, che poi guida sia la lente di valutazione sia il modo in cui la traccia viene disposta (sequenziale → corsie, gerarchico → albero, group-chat → board).
annotation_schemes:
- annotation_type: radio
name: orchestration_pattern
description: "Which orchestration pattern does this run actually follow?"
labels: [single_agent, sequential_pipeline, hierarchical_manager, group_chat, blackboard, debate, hub_and_spoke]
has_free_response: trueCorrelati
- Valutazione di agenti multimodali — schemi per agenti GUI, voce, video e documenti
- Annotare le traiettorie degli agenti — annotazione degli errori per passo
- Come valutare gli agenti IA — i livelli di valutazione degli agenti
- Annotazione agentica — configurazione e ingestione del display delle tracce
Per i dettagli implementativi, consulta la documentazione sorgente.