Allineamento giudice ↔ umano
Misura quanto un giudice LLM concorda con le tue etichette gold umane. Potato esegue il giudice sulle istanze annotate, calcola il kappa di Cohen, una matrice di confusione e un elenco dei disaccordi, e monitora l'accordo man mano che affini la rubrica.
L'allineamento del giudice misura e regola quanto un giudice LLM concorda con le tue etichette gold umane. Potato esegue un LLM-as-a-judge configurabile sulle istanze che i tuoi annotatori hanno già etichettato, calcola il κ di Cohen, una matrice di confusione e un elenco dei disaccordi, e monitora κ man mano che modifichi la rubrica del giudice. Con la modalità inline attiva, il verdetto del giudice compare accanto all'etichetta umana durante l'annotazione, insieme a un κ in tempo reale.
È il classico ciclo «allinea il giudice a circa 100–200 etichette gold» usato da strumenti come LangSmith Align Evals ed Evidently: raccogli le etichette umane, esegui il giudice, esamina i disaccordi, affina la rubrica e riesegui finché l'accordo non è elevato.
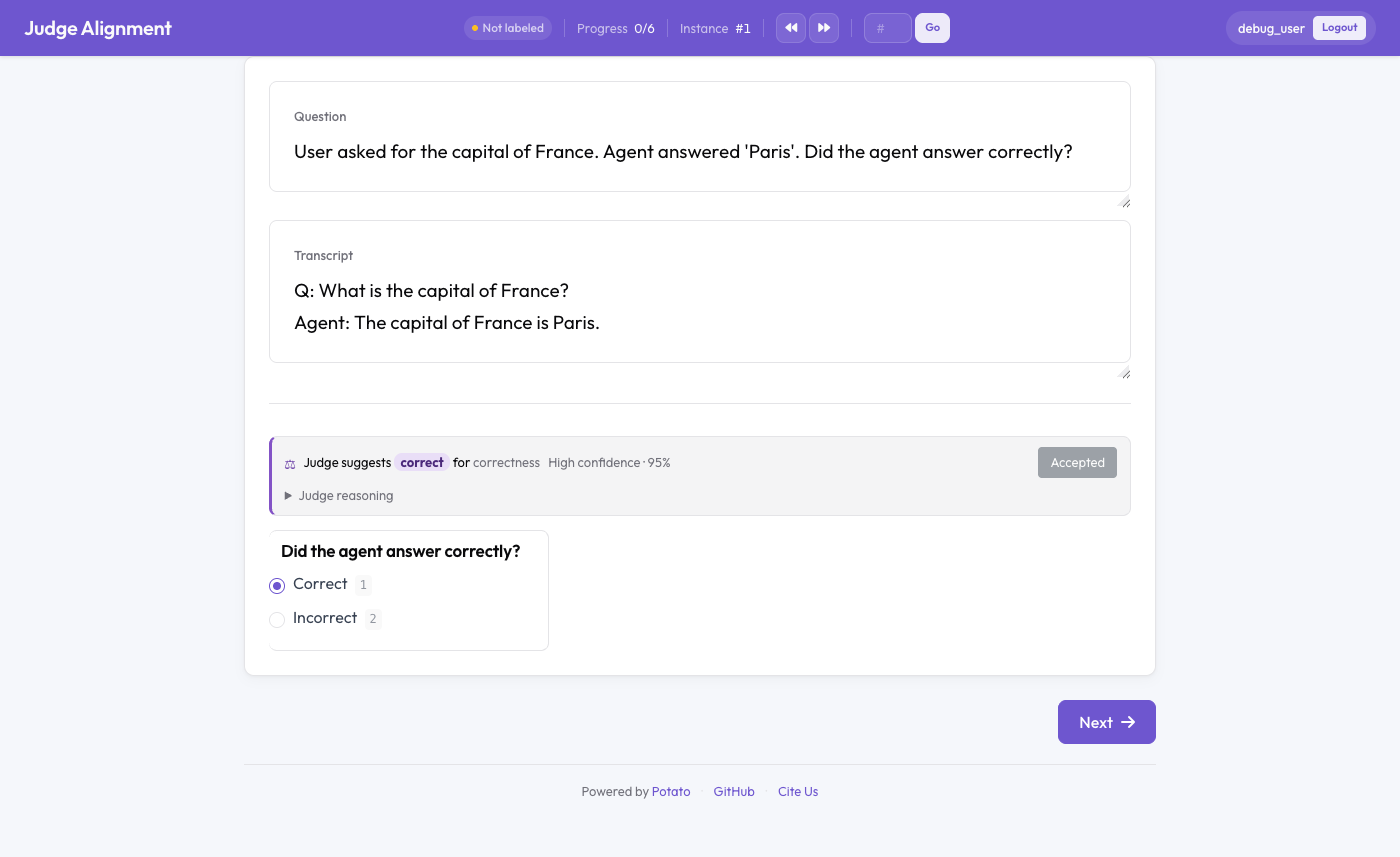 Verdetto di un giudice LLM mostrato accanto all'annotazione umana con un kappa in tempo reale
Verdetto di un giudice LLM mostrato accanto all'annotazione umana con un kappa in tempo reale
Configurazione
# The judge uses Potato's standard AI endpoint machinery.
ai_support:
enabled: true
endpoint_type: "ollama" # ollama (local) | openai | anthropic | vllm | ...
ai_config:
model: "llama3.2"
temperature: 0.0
# openai/anthropic: add api_key: "<key>"
judge_alignment:
enabled: true
schemas:
correctness: # per annotation-scheme rubric (editable)
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
few_shot:
enabled: false # seed the judge prompt with gold examples
max_examples: 4 # drawn from high-agreement human labels
min_agreement: 0.8
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]
compute_on_demand: false # call the judge live when no cached verdict existsL'ambito riguarda gli schemi categoriali a scelta singola (radio, select, likert). Se judge_alignment.schemas è impostato, vengono giudicati solo quegli schemi; altrimenti tutti gli schemi categoriali.
Eseguire il giudice
Esegui il giudice dall'API di amministrazione. Le previsioni vengono memorizzate nella cache per versione del prompt, quindi le riesecuzioni sono economiche:
# Generate or refresh judge verdicts over human-annotated instances
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Per calibrare, passa una rubrica modificata. Questo crea una nuova versione del prompt, così puoi confrontare κ tra i vari giri:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'Il report di allineamento
GET /admin/judge-alignment # JSON
GET /admin/judge-alignment?format=html # rendered page
GET /admin/judge-alignment?prompt_version=v_abc123
Invia l'intestazione X-API-Key. Per ogni schema, il report mostra:
- Il κ di Cohen con un'interpretazione Landis–Koch, il tasso di accordo e il numero di istanze confrontate.
- Una matrice di confusione (le righe sono il gold umano, le colonne il giudice).
- Una tabella dei disaccordi con l'istanza, l'etichetta umana, l'etichetta del giudice, la confidenza e il ragionamento del giudice.
- La cronologia delle versioni del prompt con il κ medio per versione, così da rendere visibili i progressi della calibrazione.
Il gold umano è il voto a maggioranza tra gli annotatori per ciascuna istanza.
Modalità inline
Con inline.enabled, ogni pagina di annotazione mostra il verdetto del giudice memorizzato nella cache per l'istanza — la sua etichetta, la confidenza e il ragionamento espandibile — accanto a un κ in tempo reale per il compito. «Accetta» compila la scelta corrispondente. Ogni salvataggio umano registra un confronto umano↔giudice che alimenta l'accordo in tempo reale. Imposta compute_on_demand: true per chiamare il giudice dal vivo quando non esiste un verdetto in cache; altrimenti esegui il batch in anticipo, che è più veloce.
Note e limitazioni
- In questa versione la calibrazione è manuale: modifica la rubrica e riesegui. L'ottimizzazione automatica del prompt è fuori ambito.
- L'ambito riguarda gli schemi categoriali a scelta singola. Il giudizio su span e testo libero è lavoro futuro.
- Esegui il giudice su un insieme gold mirato di circa 100–200 istanze etichettate per ottenere un κ stabile.
Correlati
- Calibrazione del giudice LLM — calibrazione multi-giudice e in cieco sugli umani con errore di calibrazione
- Coda di triage — invia per primi agli umani gli elementi più informativi
- Guida all'accordo tra annotatori — le metriche kappa in dettaglio
Per i dettagli di implementazione, consulta la documentazione di origine.