Valutazione di agenti multimodali
Valuta gli agenti che agiscono oltre il testo: agenti per uso del computer e GUI, assistenti vocali, video e agenti per documenti. Potato aggiunge schemi appositi per traiettorie GUI con grounding dei click, timeline vocali full-duplex, grounding temporale video con IoU dal vivo, tagging degli errori su trascrizioni vocali, ragionamento multimodale interlacciato e struttura a griglia delle tabelle.
Gli agenti agiscono sempre più in modalità oltre il testo: pilotano GUI, guardano video e tengono conversazioni parlate. Ogni modalità richiede una superficie di revisione che un semplice widget di testo non può offrire, uno screenshot con il click dell'agente, una timeline vocale a doppia traccia, uno scrubber video con intervalli gold. Potato aggiunge schemi di annotazione appositi per queste tracce, accanto ai suoi display esistenti per immagini, audio e video.
Ogni schema ricava i suoi passi, turni o segmenti dalla traccia al momento del rendering, e ciascuno è fornito con un esempio eseguibile sotto examples/agent-traces/.
Traiettoria GUI / uso del computer (gui_trajectory)
Valuta un agente per uso del computer, GUI o OS passo per passo (OSWorld, NeurIPS 2024; ScreenSpot-Pro; AndroidWorld). Ogni passo mostra lo screenshot che l'agente ha visto e l'azione che ha compiuto; l'annotatore giudica l'azione (corretta / elemento sbagliato / azione sbagliata / allucinata). Quando un passo porta le coordinate del click, un marcatore di grounding sullo screenshot mostra se il click è atterrato sull'elemento giusto.
 Rivedi ogni passo di uso del computer: correttezza dell'azione più grounding del click sullo screenshot
Rivedi ogni passo di uso del computer: correttezza dell'azione più grounding del click sullo screenshot
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot # field on each step holding an image URL / data-URI
action_key: action # field holding the action text
coord_space: normalized # normalized (0..1) | pixels — for the x/y grounding marker
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Ogni passo può fornire screenshot, action e opzionalmente x/y (o un click: {x, y} annidato). Memorizzato come una lista di {index, step, verdict, notes}.
Interazione vocale / full-duplex (voice_interaction)
Annota una conversazione parlata umano↔agente per la gestione dei turni e dei barge-in (Full-Duplex-Bench, 2025). Una timeline a doppia traccia (corsia utente più corsia agente) colloca ogni turno in base all'ora di inizio e di fine ed evidenzia le regioni di sovrapposizione dove entrambi gli interlocutori parlano contemporaneamente. L'annotatore classifica ogni sovrapposizione (l'agente dovrebbe rispondere / dovrebbe riprendere / backchannel / incerto) e valuta la gestione complessiva dei turni; l'audio sorgente viene riprodotto in linea quando fornito.
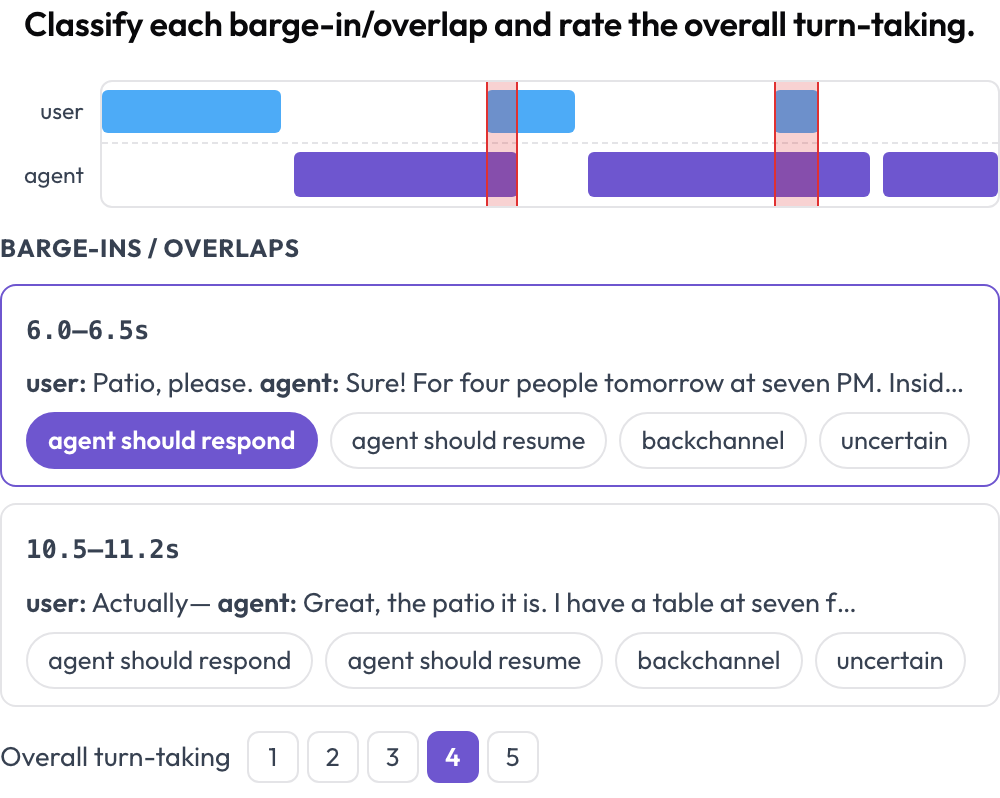 Una timeline vocale a doppia traccia con rilevamento dei barge-in e valutazione della gestione dei turni
Una timeline vocale a doppia traccia con rilevamento dei barge-in e valutazione della gestione dei turni
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns # list of {speaker, start, end, text} (seconds)
speaker_key: speaker
user_speakers: [user, human, caller] # everything else is treated as the agent
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5
# audio_key: audio # optional per-instance audio URL to enable the playerLe sovrapposizioni tra turni di interlocutori diversi sono calcolate al momento del rendering. Memorizzato come {"overlaps": {idx: label}, "rating": int}.
Grounding temporale video (temporal_grounding)
Segna gli intervalli temporali degli eventi in un video per la valutazione del grounding temporale (TimeScope, 2025; ET-Bench). Per ogni prompt di evento l'annotatore imposta il [start, end] gold, catturando la testina di riproduzione o digitando i secondi. Quando i dati portano l'intervallo previsto da un modello, un IoU dal vivo e una mini-timeline a due barre (previsto vs. gold) si aggiornano mentre regoli. È pensato appositamente per il punteggio di localizzazione previsto-vs-gold, distinto dall'etichettatura generica dei segmenti.
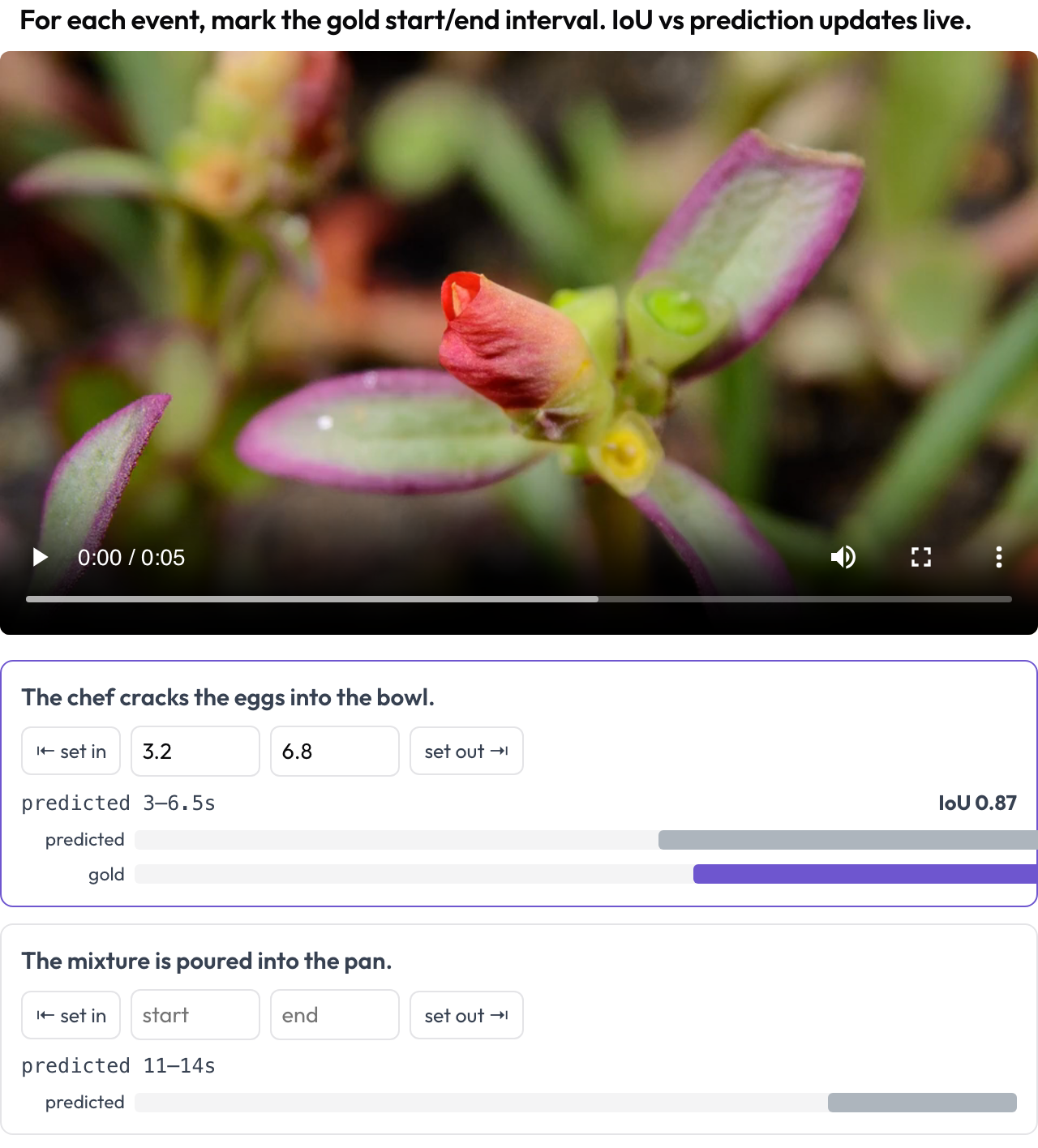 Segna gli intervalli gold degli eventi sul video con un IoU dal vivo rispetto alla previsione del modello
Segna gli intervalli gold degli eventi sul video con un IoU dal vivo rispetto alla previsione del modello
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video # per-instance video URL
events_key: events # list of {prompt, predicted: {start, end}} (predicted optional)
# duration: 120 # optional fixed timeline scale (else inferred from the video)Memorizzato come {"events": {idx: {start, end}}}.
Errori su trascrizioni allineate (speech_transcript)
Annota una trascrizione vocale allineata nel tempo segmento per segmento per errori ASR/TTS e di qualità vocale (Speak & Improve, 2025). Ogni segmento {start, end, text, speaker?} è una scheda che mostra il suo timestamp e il testo; l'annotatore tagga gli errori (errore ASR / artefatto TTS / pronuncia errata / disfluenza) e può digitare la trascrizione corretta. È il complemento a livello di segmento della vista di gestione dei turni in voice_interaction.
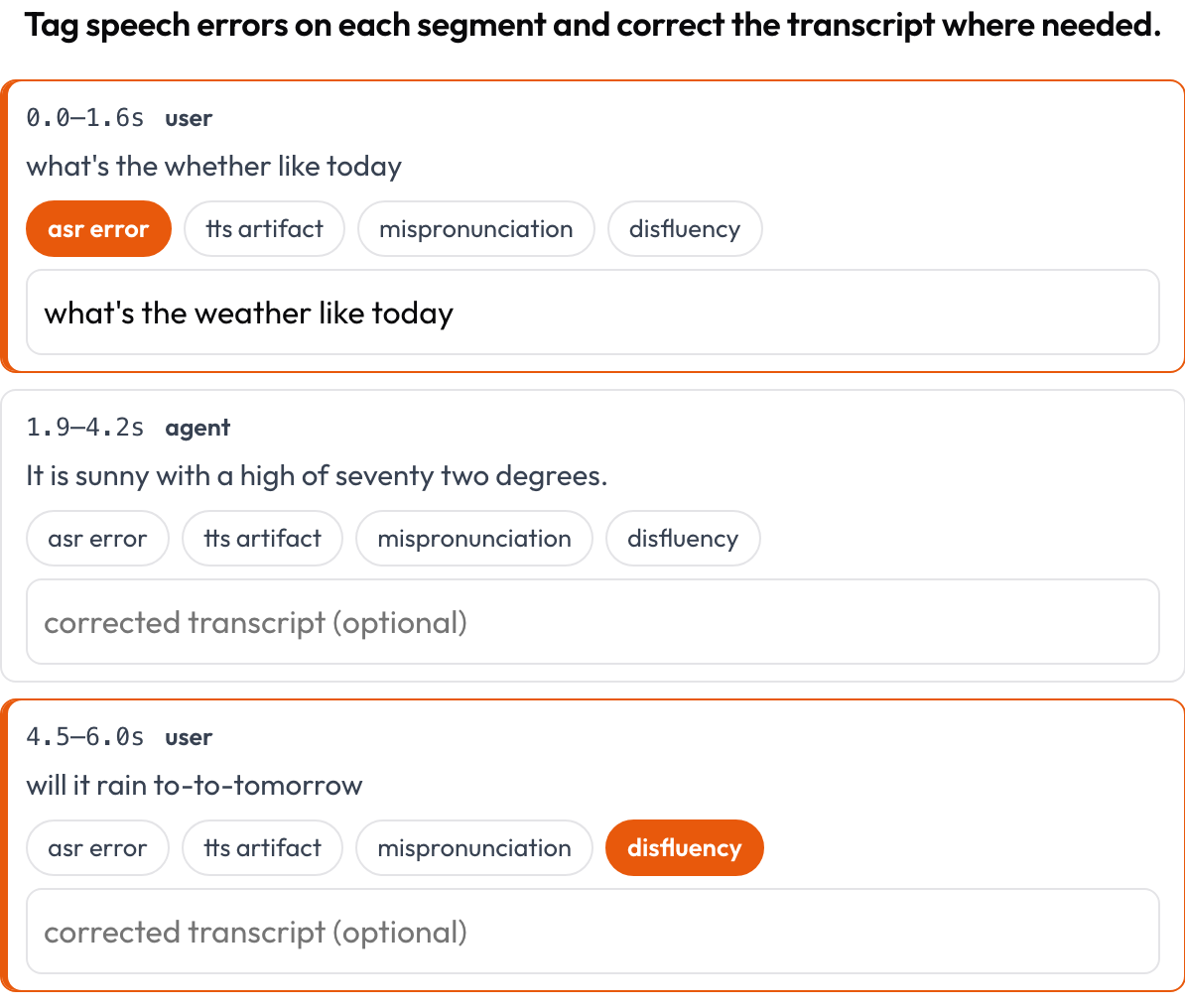 Tagga errori ASR/TTS/pronuncia per segmento e correggi la trascrizione in linea
Tagga errori ASR/TTS/pronuncia per segmento e correggi la trascrizione in linea
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments # list of {start, end, text, speaker?}
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true
# audio_key: audio # optional per-item audio URL to enable the playerMemorizzato come una lista di {index, start, end, errors, correction}.
Ragionamento multimodale interlacciato (multimodal_reasoning)
Valuta una traccia di ragionamento interlacciata testo ↔ immagine ↔ strumento ↔ azione passo per passo (Multimodal RewardBench 2, 2025; Zebra-CoT). Ogni passo è un blocco tipizzato, reso in linea in base al suo tipo; l'annotatore giudica la coerenza di ogni passo, il ragionamento segue dall'immagine e dai passi precedenti, oppure il visivo è allucinato?
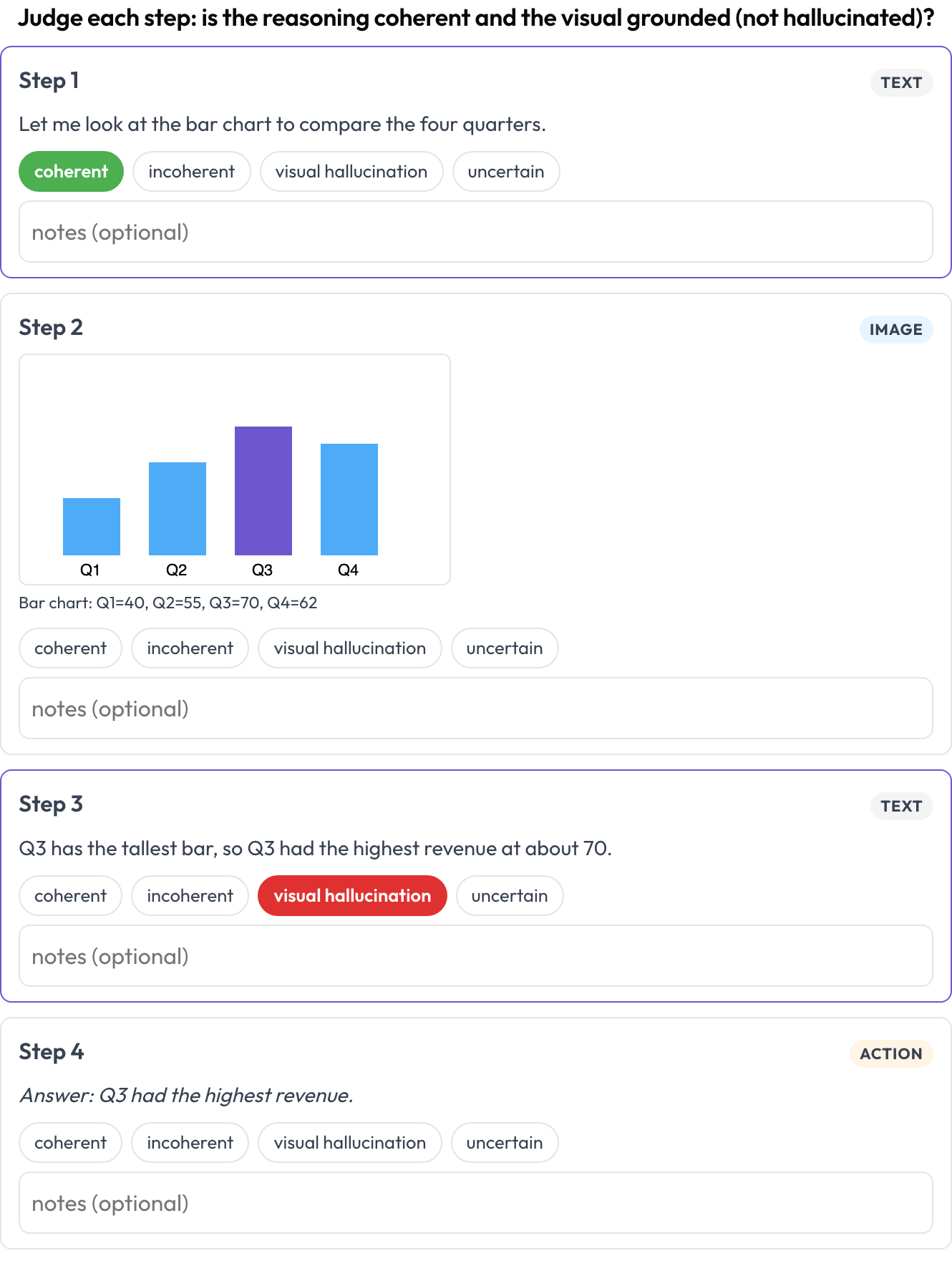 Valuta ogni passo di una traccia di ragionamento testo-immagine-strumento per coerenza e allucinazione visiva
Valuta ogni passo di una traccia di ragionamento testo-immagine-strumento per coerenza e allucinazione visiva
annotation_schemes:
- annotation_type: multimodal_reasoning
name: reasoning_review
description: "Judge each step: coherent reasoning and grounded visuals?"
steps_key: steps
type_key: type # each step's 'type': text | image | tool | action (inferred if absent)
verdict_options: [coherent, incoherent, visual_hallucination, uncertain]Ogni passo può portare text/content, image/image_url (+caption) oppure tool/args. Memorizzato come una lista di {index, step, type, verdict, notes}.
Struttura a griglia delle tabelle (table_grid)
Annota la struttura delle celle dell'immagine di una tabella, il pezzo specifico dei documenti che i semplici bounding box non possono catturare (OmniDocBench, CVPR 2025; RealHiTBench). L'annotatore imposta le dimensioni della griglia e clicca le celle per segnarne il ruolo (dato / intestazione di colonna / intestazione di riga / vuota). I box di regione per pagina sono già coperti eseguendo l'annotazione di immagini per pagina, quindi questo schema si concentra sulla struttura che quei box non possono esprimere.
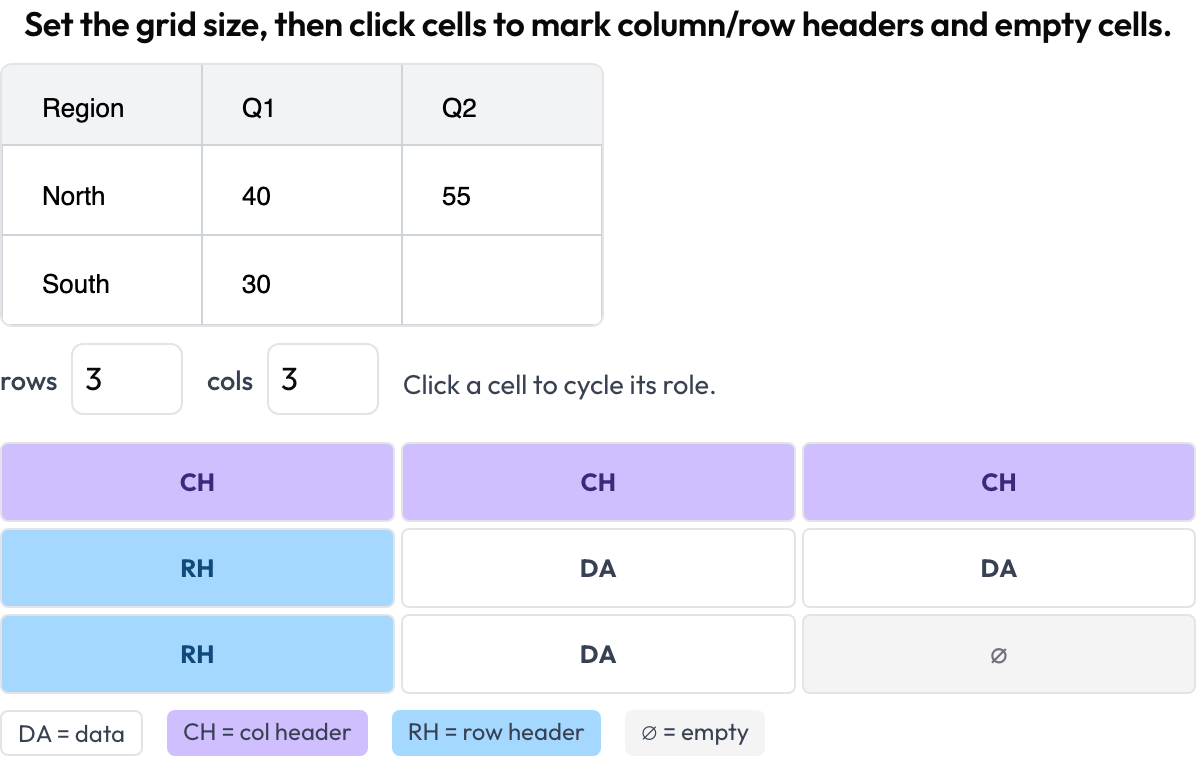 Annota la struttura delle celle di una tabella documentale: intestazioni di colonna e di riga, dati e celle vuote
Annota la struttura delle celle di una tabella documentale: intestazioni di colonna e di riga, dati e celle vuote
annotation_schemes:
- annotation_type: table_grid
name: structure
description: "Set the grid size, then click cells to mark headers and empty cells."
image_key: image # per-instance table image URL / data-URI
rows_key: rows # optional initial dims from the data
cols_key: cols
roles: [data, col_header, row_header, empty] # click cycles through theseMemorizzato come {rows, cols, cells: {"r,c": role}}, mantenendo solo le celle non data.
Correlati
- Valutazione di team multi-agente — grafo di interazione, handoff e scorecard del team
- Valutazione di agenti web — agenti web a screenshot-e-azione
- Come valutare gli agenti IA — i livelli di valutazione degli agenti
- Annotazione agentica — configurazione e ingestione del display delle tracce
Per i dettagli implementativi, consulta la documentazione sorgente.