Potato 2.6.2: una suite completa e open-source per la valutazione degli agenti
La linea 2.6.x trasforma Potato in una piattaforma completa e gratuita per la valutazione degli agenti: ingestione di trace da OpenTelemetry, LangGraph, CrewAI e AutoGen, annotazione di team multi-agente con un grafo di interazione cliccabile, schemi per agenti multimodali per GUI, voce e video, oltre a un'arena di modelli, gating in CI e curation.
Potato 2.6 ha portato la prima ondata di valutazione degli agenti: calibrazione dell'LLM-as-judge, editing delle traiettorie per i dati di training e il display eval_trace a tre riquadri. Le release puntuali 2.6.x successive completano il resto. A partire dalla 2.6.2, Potato è una piattaforma completa per la valutazione degli agenti: puoi catturare trace dai tuoi agenti, annotare singoli agenti, team multi-agente e agenti multimodali, valutarli con LLM di cui ti puoi fidare, classificare i modelli in un'arena e fare gating delle release in CI. Tutto si configura in YAML e resta sul tuo server.
 Valutazione multi-agente di Potato
Valutazione multi-agente di Potato
La maggior parte di queste sono funzionalità per cui oggi si paga una piattaforma in hosting. Potato le offre gratis e in self-hosting. Ecco cosa è stato rilasciato lungo la linea 2.6.x.
 La suite di valutazione degli agenti 2.6.x, dall'inizio alla fine
La suite di valutazione degli agenti 2.6.x, dall'inizio alla fine
Far entrare le trace: un SDK di cattura e standard aperti
La valutazione parte dalle esecuzioni reali. Il nuovo SDK potato_trace strumenta qualsiasi agente: decora una funzione con @traceable (sincrona o asincrona) e le chiamate annidate vengono catturate e inviate all'endpoint di ingestione di Potato, con un export OpenTelemetry opzionale. Potato ingerisce anche span OpenTelemetry / OpenInference e i formati di esecuzione di LangGraph, CrewAI e AutoGen, così le trace dal framework che già usi atterrano nella coda di annotazione senza codice di collegamento. Le nuove trace possono arrivare tramite un webhook, un poller o una directory monitorata e diventano assegnabili agli annotatori man mano che arrivano.
Riferimenti: SDK di tracing, Regole di automazione.
Vedere l'intero team: valutazione multi-agente
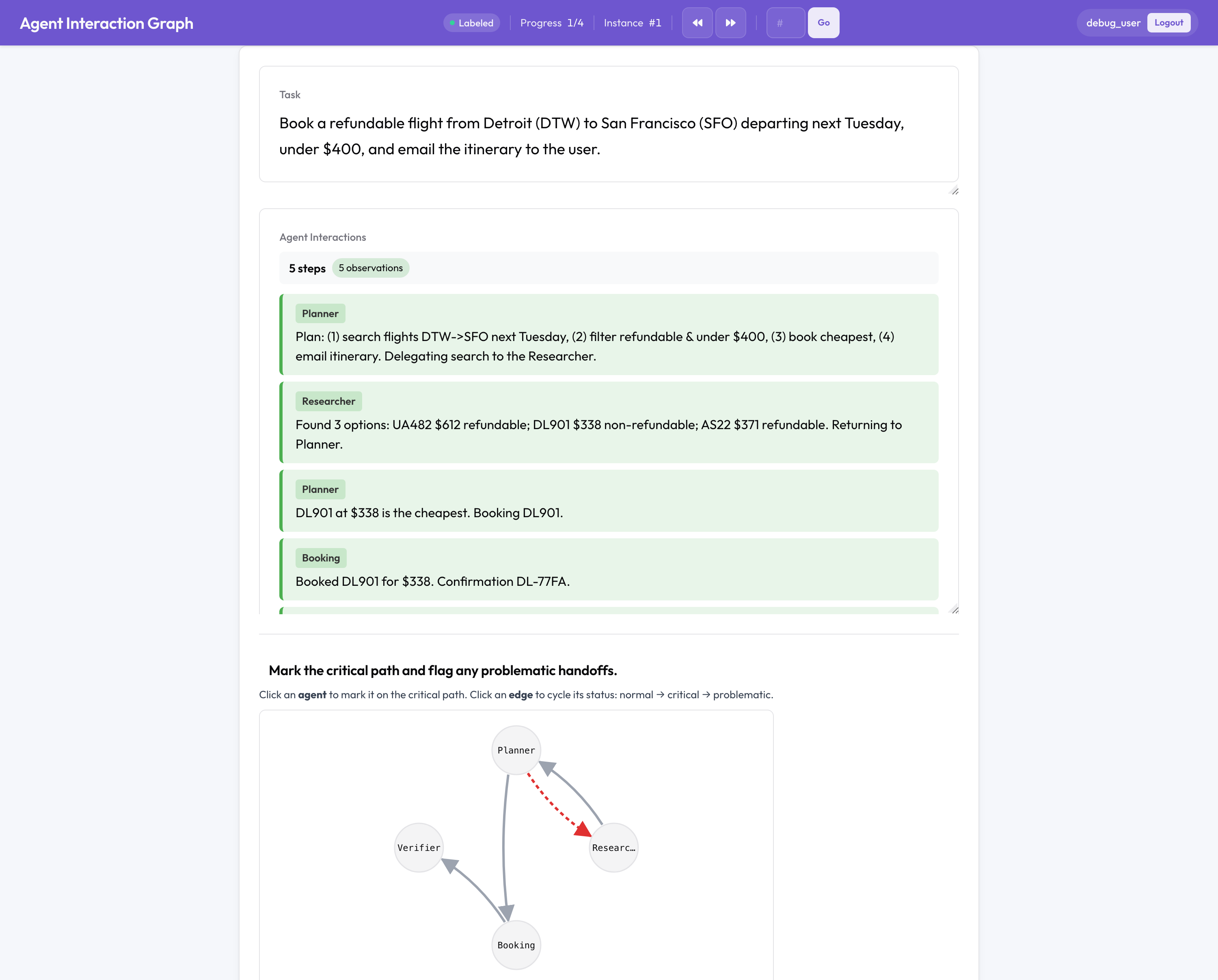
Questa è la parte senza equivalenti open-source. Un'esecuzione multi-agente fallisce in modo diverso da un singolo agente, tra gli agenti, durante un handoff, nel modo in cui il team è stato organizzato, quindi Potato annota la struttura del team anziché una trascrizione piatta:
- Un grafo di interazione cliccabile di agenti e handoff, dove segni il percorso critico e contrassegni gli archi problematici.
- Attribuzione del fallimento: scegli l'agente responsabile, il passo decisivo e il motivo, la tripla (agente, passo, motivo) dal lavoro sull'attribuzione Who&When.
- Revisione degli handoff: ogni trasferimento di controllo diventa una scheda per segnalare il disallineamento tra agenti e valutarne la qualità.
- Scorecard per singolo agente e per team: fedeltà al ruolo, contributo e coordinamento per agente, oltre alle dimensioni condivise del team e alle milestone.
- Una timeline di contesa degli strumenti che fa emergere deadlock e race dove gli agenti toccano la stessa risorsa contemporaneamente.
- Tagging dei comportamenti emergenti per collusione, groupthink ed errori a cascata che si estendono su più agenti e turni.
 Attribuzione del fallimento: quale agente, quale passo e perché
Attribuzione del fallimento: quale agente, quale passo e perché
L'insieme completo, con lo YAML per ciascuno, è in Valutazione di team multi-agente, e l'approfondimento Debug dei fallimenti multi-agente percorre ogni superficie dall'inizio alla fine. La guida Come valutare i sistemi multi-agente illustra quando usare cosa.
Oltre il testo: valutazione di agenti multimodali
Gli agenti ora pilotano GUI, guardano video e tengono conversazioni parlate, e ciascuno ha bisogno di una superficie di revisione che un widget di testo non può offrire:
- Traiettorie GUI / di uso del computer: screenshot e azione per ogni passo, un verdetto sull'azione e un marcatore di grounding del click che mostra se il click è atterrato sull'elemento giusto.
- Timeline vocali full-duplex: una timeline a doppia traccia utente/agente con rilevamento dei barge-in e valutazione della gestione dei turni.
- Grounding temporale video: segna gli intervalli gold degli eventi con un IoU dal vivo rispetto all'intervallo previsto dal modello.
- Tagging degli errori su trascrizioni vocali, ragionamento multimodale interlacciato con flag di allucinazione visiva e struttura a griglia delle tabelle documentali.
 Revisione dell'uso del computer: correttezza dell'azione più grounding del click
Revisione dell'uso del computer: correttezza dell'azione più grounding del click
Due approfondimenti li percorrono: Valutazione degli agenti per uso del computer per agenti GUI e OS, e Valutazione di agenti vocali e video per agenti parlati, video e documentali. Il riferimento è Valutazione di agenti multimodali, e la guida è Valutare gli agenti per uso del computer e multimodali.
Giudici di cui ti puoi fidare, e un'arena
Usare un LLM per valutare gli output è ormai routine; il lavoro 2.6.x riguarda il sapere fino a che punto fidarsene. La calibrazione dei giudici esegue un passaggio umano cieco contro le etichette del modello e riporta accuratezza, kappa ed Expected Calibration Error. L'allineamento dei giudici regola un singolo giudice rispetto alle tue etichette gold. E i valutatori programmatici assegnano automaticamente un punteggio a traiettorie e testo (corrispondenza di traiettoria, correttezza dell'uso degli strumenti, LLM-as-judge senza riferimento ed euristiche) senza un server in esecuzione.
Per il confronto diretto, la Model Arena invia un singolo prompt a diversi modelli, raccoglie le preferenze e costruisce una classifica di win-rate su OpenAI, Anthropic, Gemini, Ollama e vLLM.
Trattare la valutazione come software
I pezzi operativi rendono la valutazione ripetibile:
- Dataset ed esperimenti: set di valutazione versionati, split e confronto di esperimenti affiancati con delta di regressione.
- Valutazione in CI: un plugin pytest che fa fallire la build quando una modifica al prompt o al modello fa regredire la qualità dell'agente oltre una soglia.
- Regole di automazione: instrada le trace di produzione in arrivo in dataset, valutatori o nella coda di annotazione per regola.
- Curation semantica: un indice di embedding per "trova trace come questo fallimento" e slice dinamiche salvate.
Come ottenerlo
pip install --upgrade potato-annotationOgni nuova superficie è fornita con un esempio eseguibile sotto examples/agent-traces/, inclusi interaction-graph/, failure-attribution/, gui-trajectory/ e temporal-grounding/. Punta Potato a uno di questi per vedere lo schema in esecuzione:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000Se stai valutando gli strumenti, il confronto in Potato vs LangSmith e Langfuse e la guida Strumenti di annotazione open-source a confronto illustrano dove si colloca ciascuno. Domande e formati di trace che dovremmo supportare sono benvenuti sul repository GitHub.