Debug dei fallimenti multi-agente: una guida pratica
Come trovare il motivo per cui un sistema LLM multi-agente è fallito usando Potato: il grafo di interazione, l'attribuzione del fallimento, la revisione degli handoff, le scorecard per agente, la timeline di contesa degli strumenti e il tagging dei comportamenti emergenti.
Quando un team di agenti fallisce, la parte difficile non è accorgersi del fallimento, ma trovare quale agente lo ha causato, in quale passo, e se il vero problema fosse un cattivo handoff tra due agenti che, presi singolarmente, andavano entrambi bene. Questa guida percorre le sei superfici di Potato create proprio per questo, nell'ordine in cui le useresti davvero su un'esecuzione difettosa. Tutto qui si configura in YAML e gira sul tuo server; il riferimento completo agli schemi è Valutazione di team multi-agente.
Un sistema multi-agente è composto da più agenti LLM con ruoli distinti — un planner, un coder, un reviewer — che si passano messaggi e trasferiscono il controllo. La ricerca sul perché questi sistemi si rompono, la tassonomia MAST (Why Do Multi-Agent LLM Systems Fail?), ha rilevato che la maggior parte dei fallimenti è inter-agente: un vincolo perso in un handoff, un team che non verifica mai il proprio lavoro, agenti che si parlano senza capirsi. Una trascrizione di chat piatta nasconde proprio questi casi, perché ciò che è andato storto vive nello spazio tra due messaggi, non dentro uno dei due.
 Il fallimento è tra gli agenti, in un handoff, non dentro una singola trascrizione
Il fallimento è tra gli agenti, in un handoff, non dentro una singola trascrizione
Come vedo la struttura di un'esecuzione multi-agente?
Parti dalla forma dell'esecuzione, non dal testo. Lo schema agent_interaction_graph rende l'intera esecuzione come un grafo orientato: i nodi sono gli agenti, gli archi sono gli handoff tra di loro, e archi più spessi indicano più traffico. Clicchi un nodo per segnarlo sul percorso critico e clicchi un arco per farlo ciclare da normale a critico a problematico.
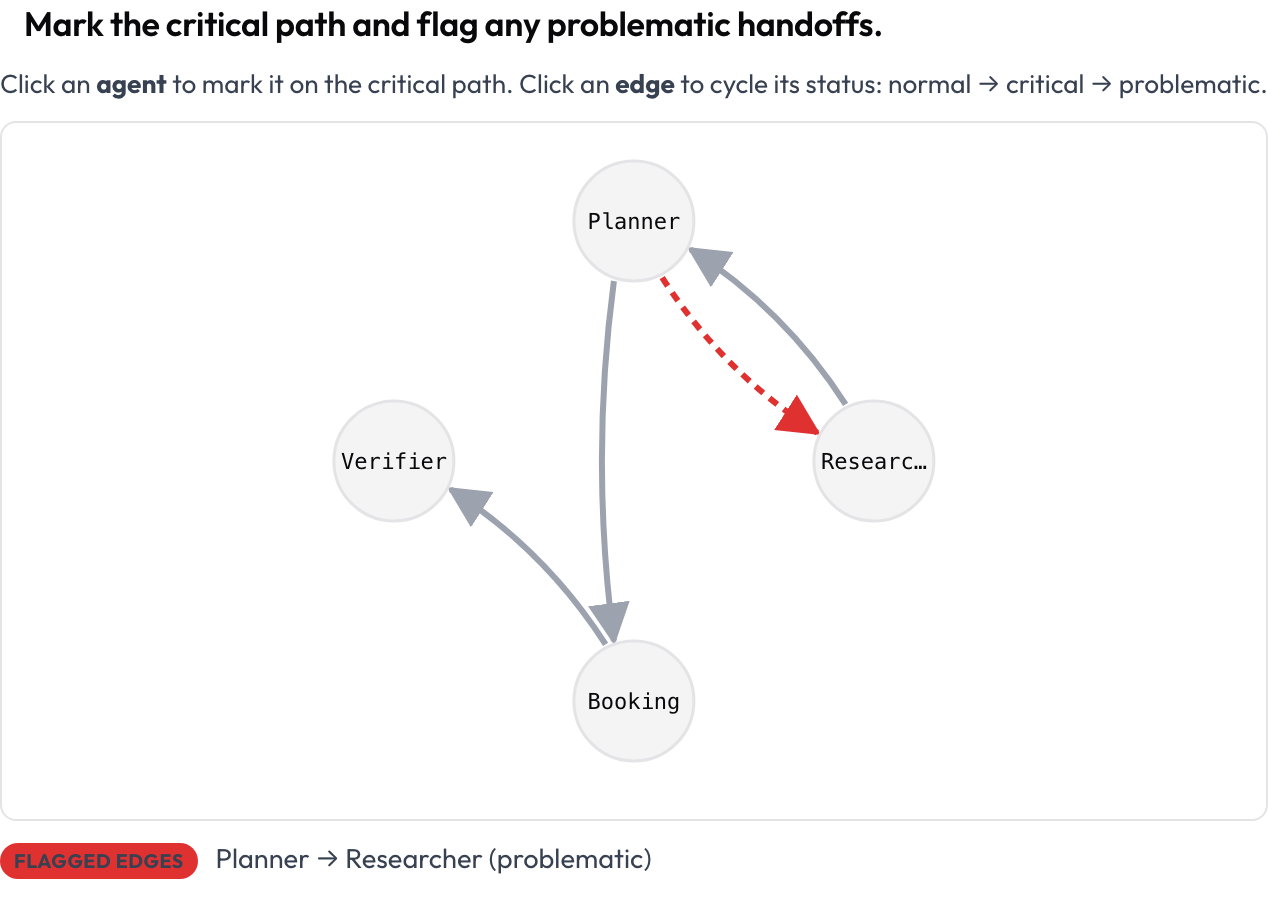 Segna il percorso critico e contrassegna gli handoff problematici
Segna il percorso critico e contrassegna gli handoff problematici
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentIl grafo è disposto automaticamente a partire dalla trace, quindi non disegni nulla. Ogni nodo e arco è raggiungibile da tastiera e un riepilogo testuale elenca i nodi critici e gli archi segnalati, così il significato non poggia mai solo sul colore. Questa vista è il modo più rapido per rispondere a "cosa ha parlato con cosa, e dove il percorso è andato storto".
Come attribuisco un fallimento multi-agente a un singolo agente?
Una volta che vedi l'esecuzione, individua con precisione il fallimento. Lo schema failure_attribution chiede la tripla dalla letteratura sull'attribuzione dei fallimenti (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, il dataset Who&When): l'agente responsabile, il passo decisivo e il motivo. Il menu a tendina degli agenti e il selettore dei passi sono popolati dai turni stessi della trace, così puoi attribuire il fallimento solo a un agente e a un passo che sono effettivamente accaduti.
 Attribuisci il fallimento all'agente responsabile, al passo decisivo e al perché
Attribuisci il fallimento all'agente responsabile, al passo decisivo e al perché
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agentAbbinare l'attribuzione a un radio successo/fallimento significa che la tripla viene raccolta solo sulle esecuzioni fallite, il che mantiene il tempo dell'annotatore sui casi che portano segnale.
E gli handoff in sé?
L'attribuzione nomina un solo passo decisivo. La revisione degli handoff guarda ogni trasferimento di controllo. Ovunque l'agente attivo cambi tra turni consecutivi, Potato emette una scheda di handoff A → B, e tu contrassegni cosa è andato storto nel passaggio — perdita di informazioni, un vincolo perso, distorsione, deriva dell'obiettivo — e ne valuti la qualità. Le modalità di fallimento provengono dalla categoria inter-agente di MAST e dal fenomeno dell'"echoing" (Zhang et al., 2025).
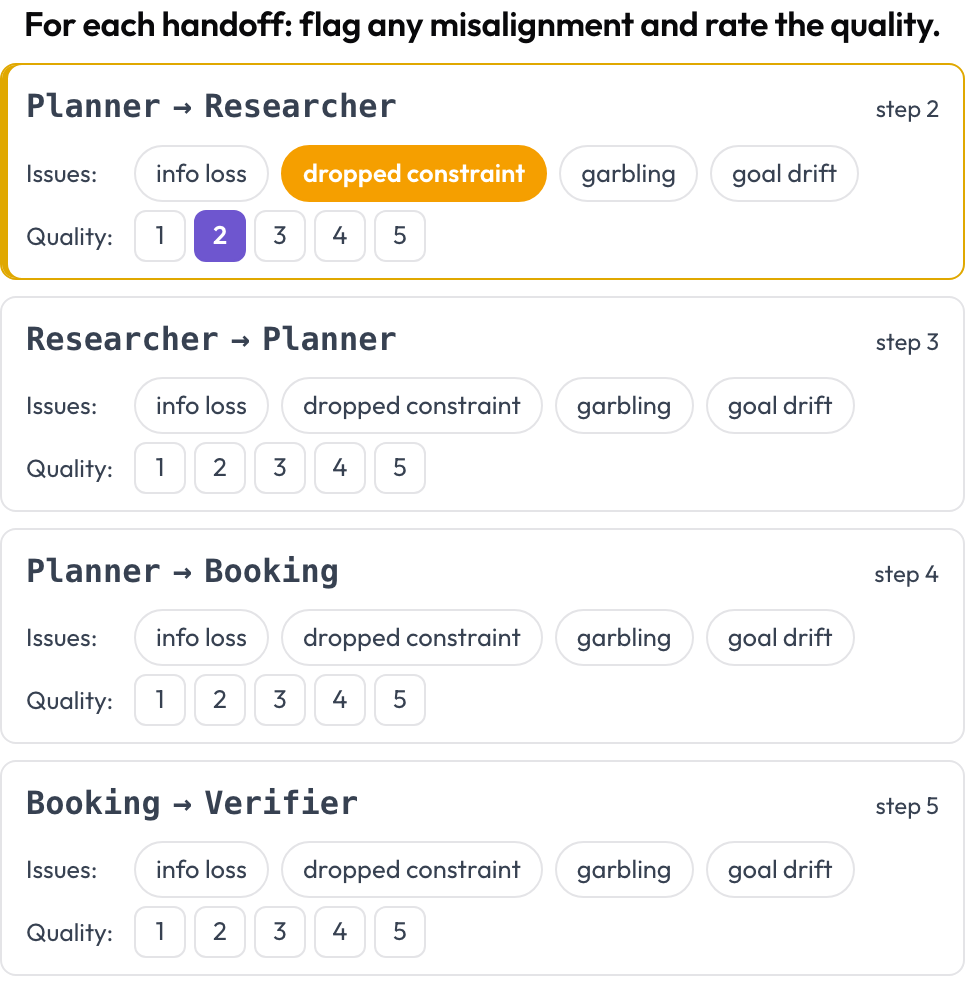 Contrassegna il disallineamento tra agenti su ogni handoff e valutane la qualità
Contrassegna il disallineamento tra agenti su ogni handoff e valutane la qualità
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Gli handoff sono derivati al momento del rendering, quindi non c'è alcuna configurazione manuale. Di solito è qui che si risolvono i casi "ogni agente sembrava a posto, il team è fallito comunque": il vincolo era vivo nell'agente A e svanito nell'agente B.
Come do un punteggio agli agenti e al team?
Un fallimento ti dice cosa si è rotto una volta. Una scorecard ti dice se un design è buono su molte esecuzioni. Lo schema agent_scorecard assegna un punteggio a due livelli contemporaneamente (MultiAgentBench, Zhou et al., ACL 2025): ciascun agente su fedeltà al ruolo, contributo e coordinamento, e il team sulle proprie dimensioni condivise, con milestone opzionali. Le righe degli agenti provengono dalla trace, così la matrice corrisponde a chi ha effettivamente partecipato.
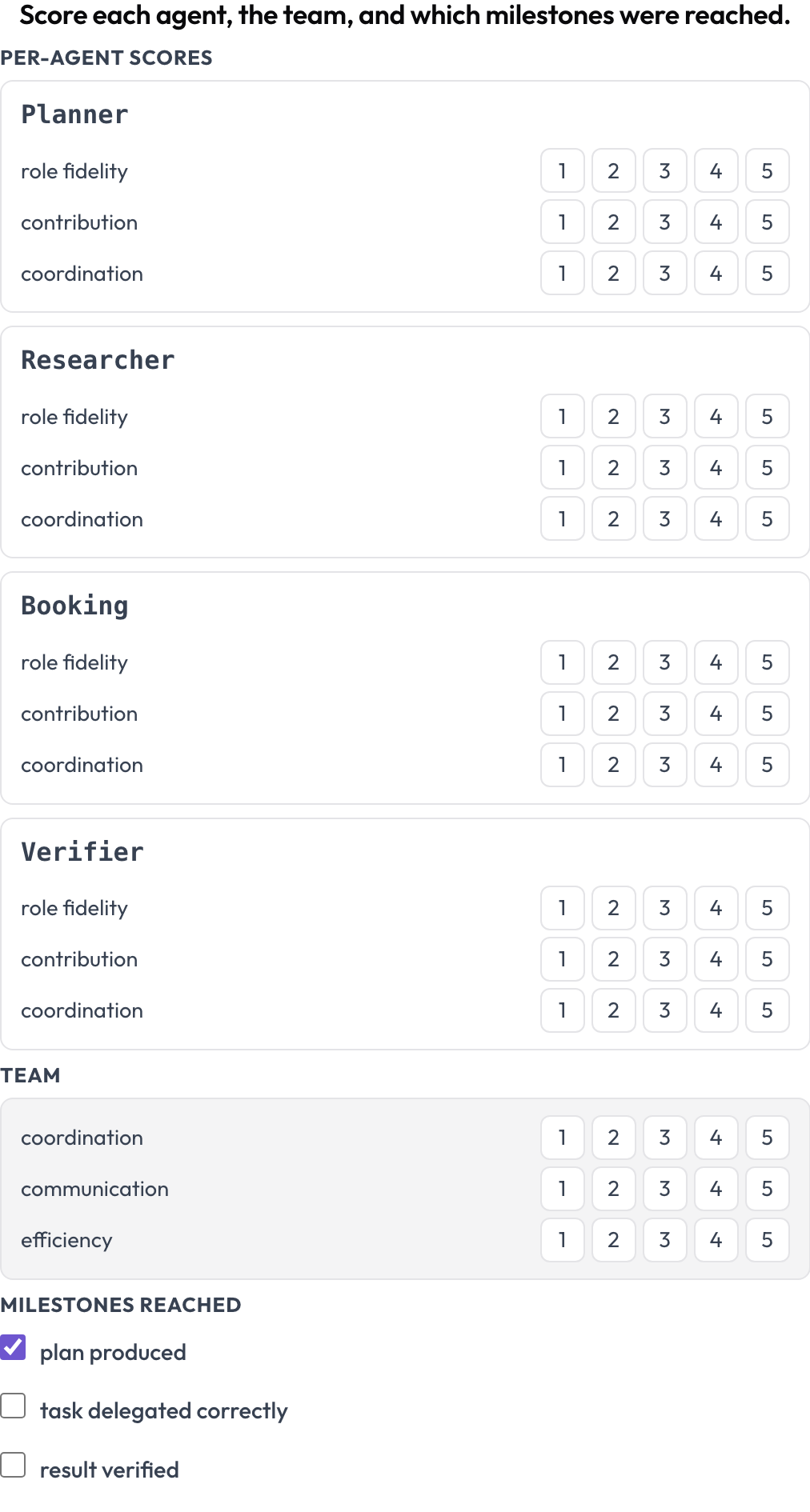 Dai un punteggio a ciascun agente su fedeltà al ruolo, contributo e coordinamento, oltre al team
Dai un punteggio a ciascun agente su fedeltà al ruolo, contributo e coordinamento, oltre al team
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]Un agente forte bloccato dentro un team mal coordinato appare qui come una riga di agente alta accanto a dimensioni di team basse, che è il pattern che vuoi quando confronti orchestrazione sequenziale, gerarchica e a chat di gruppo sugli stessi task.
E la concorrenza e i fallimenti collettivi?
Altre due superfici catturano fallimenti che una lettura turno per turno non può cogliere. La timeline tool_contention mette ogni agente nella sua corsia ed evidenzia le regioni dove due chiamate toccano la stessa risorsa in tempi sovrapposti, che classifichi come deadlock, attesa circolare, race condition o benigna (DPBench, 2026).
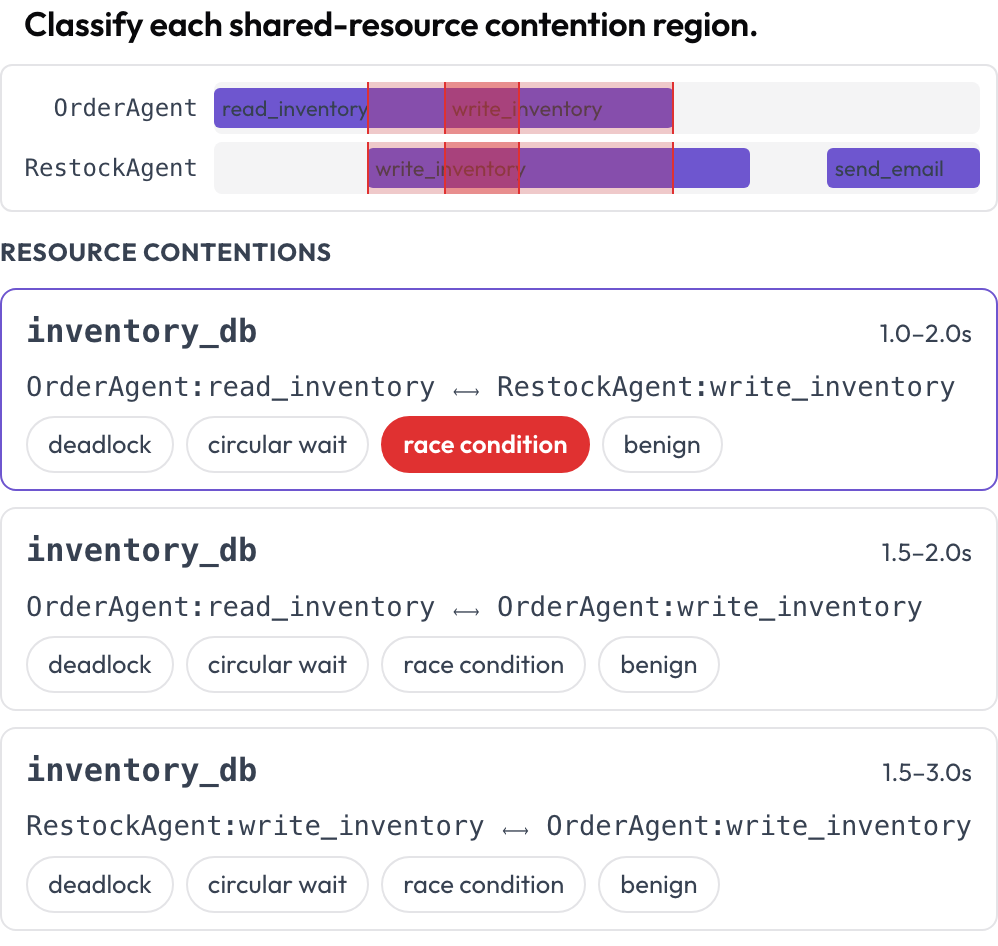 Individua deadlock e race condition su una timeline delle chiamate agli strumenti per agente
Individua deadlock e race condition su una timeline delle chiamate agli strumenti per agente
E emergent_behavior gestisce i fallimenti che sono collettivi anziché localizzati in un solo passo — collusione, groupthink, errori a cascata, deriva del ruolo. Un comportamento emergente non è uno span contiguo; è un insieme di turni partecipanti, possibilmente di agenti diversi, quindi spunti i turni che vi prendono parte e aggiungi una nota.
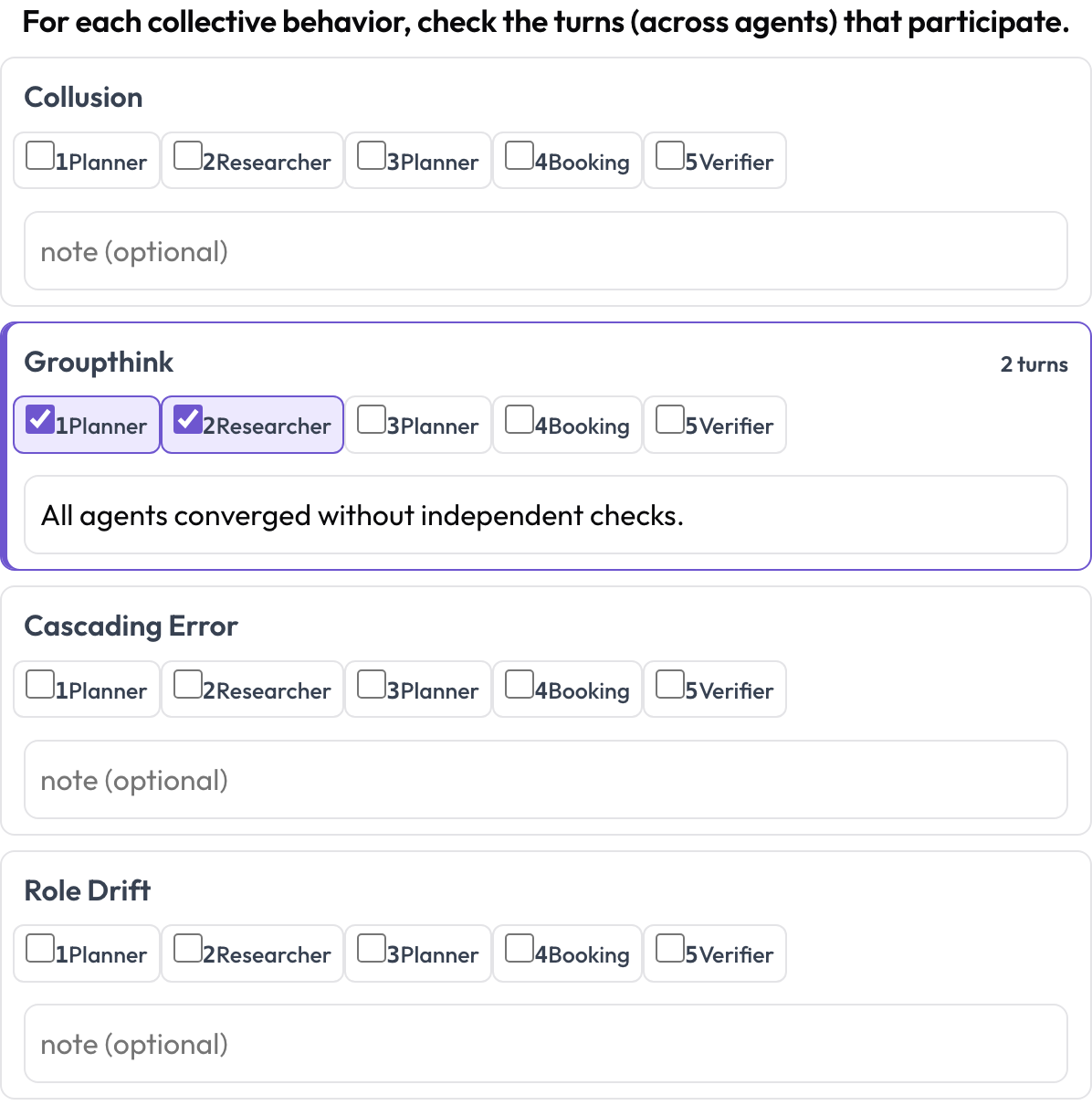 Tagga collusione, groupthink ed errori a cascata tra agenti e turni
Tagga collusione, groupthink ed errori a cascata tra agenti e turni
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueMettere tutto in ordine
Su un'esecuzione realmente difettosa la sequenza è di solito: leggi il grafo di interazione per vedere la forma, usa l'attribuzione del fallimento per nominare il passo decisivo, apri la revisione degli handoff se il passo decisivo era un trasferimento, e ricorri alla timeline di contesa o al tagging dei comportamenti emergenti quando il fallimento riguarda il timing o il gruppo anziché un singolo agente. Dai un punteggio con la scorecard una volta che stai confrontando design anziché fare debug di una singola esecuzione. Misura l'accordo sull'attribuzione come faresti con qualsiasi etichetta soggettiva; vedi Accordo tra annotatori.
Letture di approfondimento
- Valutazione di team multi-agente — il riferimento completo agli schemi con lo YAML per ciascuna superficie
- Come valutare i sistemi multi-agente — la guida decisionale su quale metodo usare e quando
- Potato 2.6.2: una suite completa e open-source per la valutazione degli agenti — tutto ciò che è stato rilasciato lungo la linea 2.6.x
- Annotare le traiettorie degli agenti — tassonomie di errore per passo, incluso il tagging MAST a granularità di passo