Valutare gli agenti per uso del computer, passo dopo passo
Una guida pratica alla valutazione umana per agenti per uso del computer e GUI in Potato: giudicare ogni azione, verificare il grounding del click sullo screenshot e rivedere le chiamate agli strumenti una alla volta.
Un agente per uso del computer legge uno screenshot, decide un'azione e clicca. Valutarne uno significa controllare ogni passo: l'azione era corretta, e il click è atterrato davvero sull'elemento che aveva nominato — non solo se il task alla fine è riuscito. Il successo del task nasconde il click che ha colpito il pulsante sbagliato ma è avanzato comunque, e l'azione che era giusta per fortuna. Potato rivede queste esecuzioni con una superficie di traiettoria GUI dedicata e una revisione delle chiamate agli strumenti, entrambe configurate in YAML.
Un agente per uso del computer — chiamato anche agente GUI o OS — vede lo schermo come pixel o DOM e agisce attraverso gli stessi controlli che ha una persona. Benchmark come OSWorld, ScreenSpot e AndroidWorld assegnano automaticamente un punteggio al completamento del task. Lo scoring automatico è economico e vale la pena eseguirlo, ma non può dirti perché un'esecuzione è fallita, né cogliere il successo fortunato. È questa la lacuna che colma la revisione umana dei passi.
 Giudica l'azione e se il click è atterrato sull'elemento che ha nominato
Giudica l'azione e se il click è atterrato sull'elemento che ha nominato
Cosa giudichi davvero in una traiettoria GUI?
Ogni passo abbina uno screenshot (ciò che l'agente ha visto) a un'azione (ciò che ha fatto). Giudichi l'azione, e quando il passo porta con sé le coordinate del click, controlli il marcatore di grounding che Potato disegna sullo screenshot:
- Correttezza dell'azione — corretta, elemento sbagliato, azione sbagliata o allucinata.
- Grounding del click — le coordinate sono atterrate sull'elemento nominato dall'azione?
- Esito — l'esecuzione ha completato il task, e a quale passo è andata storta per la prima volta?
 Rivedi ogni passo: correttezza dell'azione più grounding del click sullo screenshot
Rivedi ogni passo: correttezza dell'azione più grounding del click sullo screenshot
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot
action_key: action
coord_space: normalized
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Ogni passo fornisce screenshot, action e gli opzionali x/y (o un click: {x, y} annidato). Il marcatore di grounding è la parte che le metriche automatiche mancano più spesso: un modello può produrre l'etichetta di azione giusta cliccando però dieci pixel fuori dal bersaglio, e un pass/fail sulla schermata finale non lo farà mai emergere.
Perché il primo passo sbagliato conta più del risultato finale?
Perché quel passo è ciò che correggeresti o su cui faresti training. Un'esecuzione che fallisce al passo 9 perché al passo 3 ha letto male una finestra di dialogo è in realtà un problema del passo 3, ed etichettarla al passo 9 insegna la lezione sbagliata. Cogliere la prima divergenza è la stessa idea dietro i process reward model: un segnale a ogni passo localizza l'errore invece di collassare l'intera traiettoria in un solo numero.
Come rivedo le chiamate agli strumenti di un agente?
Gli agenti GUI chiamano anche strumenti e funzioni, e quelle falliscono a modo loro: intento giusto, strumento sbagliato; strumento giusto, argomenti malformati; chiamata giusta, ordine sbagliato. Lo schema tool_call_review estrae ogni chiamata dalla trace e le assegna una scheda con il nome dello strumento e gli argomenti formattati in modo leggibile, così le giudichi una alla volta (rispecchiando BFCL v4 / MCPMark).
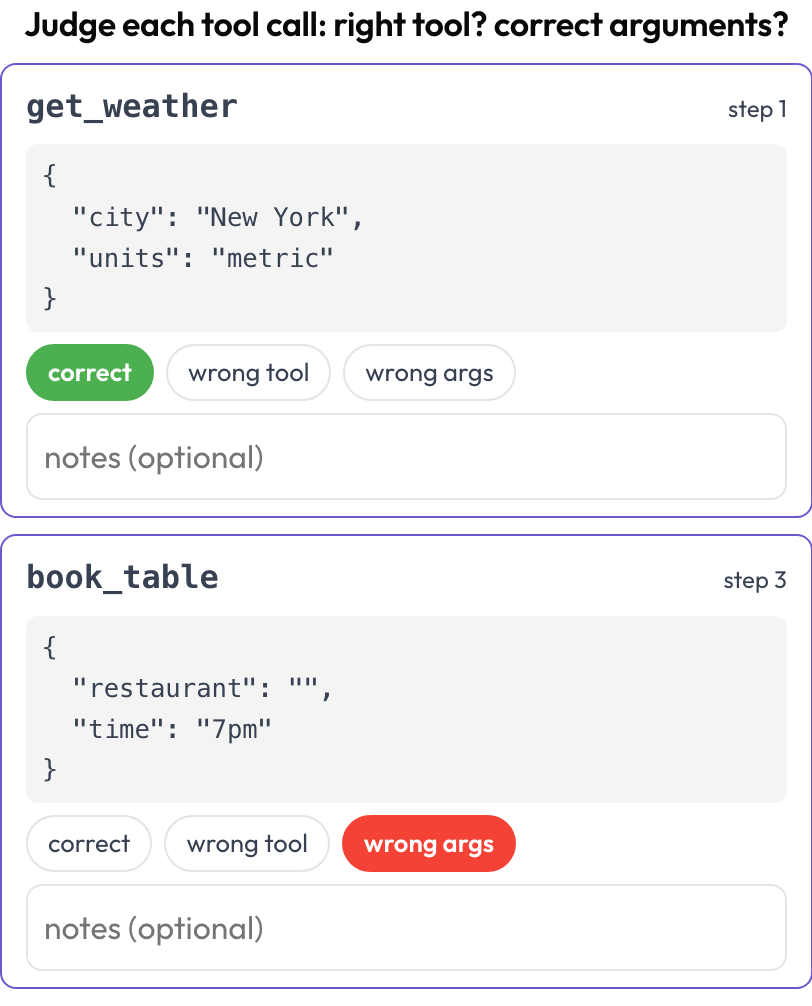 Giudica ogni chiamata agli strumenti: strumento giusto, argomenti corretti, ordine giusto
Giudica ogni chiamata agli strumenti: strumento giusto, argomenti corretti, ordine giusto
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order]Le chiamate agli strumenti vengono estratte al momento del rendering dal campo tool_calls, tool_call o action di ogni passo, così una traiettoria che mescola click nell'interfaccia e chiamate API può essere rivista su entrambi gli assi in un solo task.
Come imposto tutto questo?
Ogni superficie è fornita con un esempio eseguibile sotto examples/agent-traces/. Punta Potato a uno di questi per vedere lo schema con dati di esempio:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/gui-trajectory/config.yaml -p 8000I tuoi dati si inseriscono come una lista di passi, ciascuno con un URL di screenshot o un data-URI e una stringa di azione. Per agenti web più generici che lavorano da pagine renderizzate anziché da screenshot grezzi, vedi Valutazione degli agenti web.
Letture di approfondimento
- Valutazione di agenti multimodali — il riferimento completo agli schemi per agenti GUI, vocali, video e documentali
- Valutare gli agenti per uso del computer e multimodali — la guida, con una tabella di selezione degli schemi
- Valutazione di agenti vocali e video — l'altra metà delle superfici multimodali
- Potato 2.6.2: una suite completa e open-source per la valutazione degli agenti — l'intera linea 2.6.x