Valutare agenti vocali e video
Una guida pratica alla valutazione umana per agenti parlati, video e documentali in Potato: valutare la gestione dei turni su una timeline a doppia traccia, fare grounding degli eventi video con IoU dal vivo, taggare gli errori del parlato e marcare la struttura delle tabelle.
Gli agenti che parlano, guardano video e leggono documenti falliscono in modi che una casella di testo non può mostrare. Gli errori di un agente vocale vivono nei punti di giunzione tra i turni; la risposta di un agente video è un intervallo di tempo, non una frase; l'errore di un agente documentale è una cella di tabella letta male. Ognuno di questi ha bisogno di una superficie di revisione modellata sulla modalità. Potato aggiunge quattro di queste superfici — voce, video, parlato e documento — accanto ai display esistenti per immagini e audio. Il riferimento completo è Valutazione di agenti multimodali.
 Un semplice widget di testo non può esprimere un barge-in, un intervallo di evento o una cella di tabella
Un semplice widget di testo non può esprimere un barge-in, un intervallo di evento o una cella di tabella
Come valuto la gestione dei turni di un agente vocale?
Gli agenti parlati si rompono ai confini: tagliando la parola all'utente, parlandogli sopra o facendo una pausa così lunga che l'utente rinuncia. Lo schema voice_interaction dispone la conversazione come una timeline a doppia traccia — una corsia utente e una corsia agente — ed evidenzia le regioni di sovrapposizione dove entrambi parlano contemporaneamente (Full-Duplex-Bench, 2025). Classifichi ogni sovrapposizione e valuti la gestione complessiva dei turni; l'audio viene riprodotto inline quando fornito.
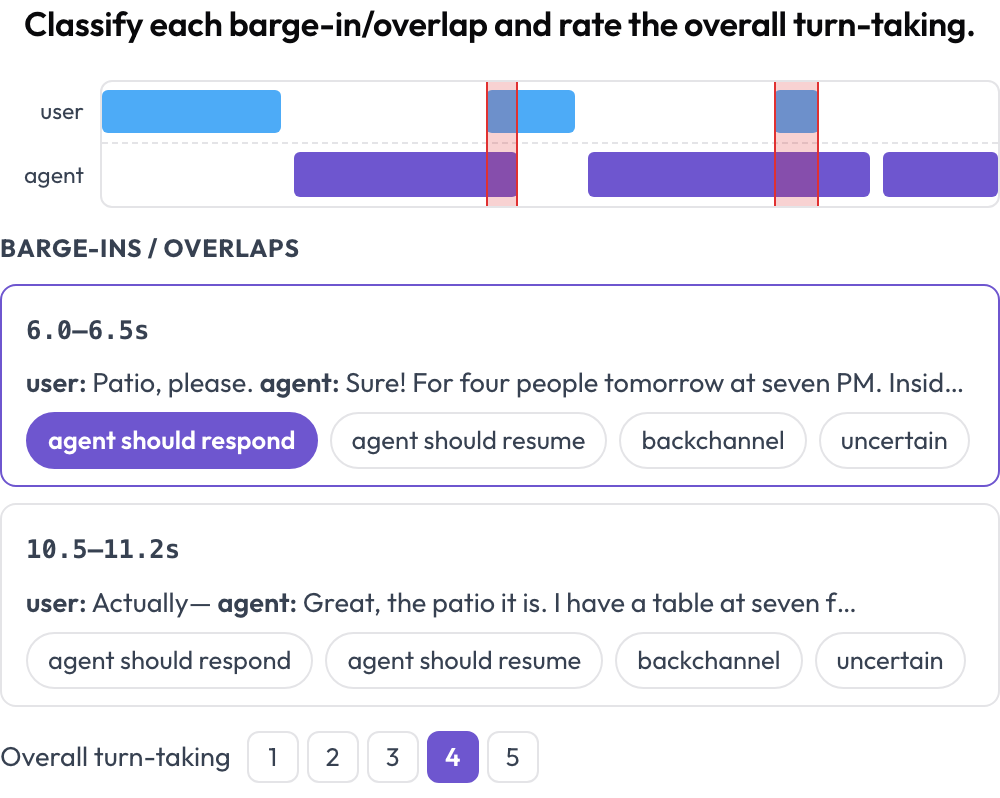 Timeline vocale a doppia traccia con rilevamento dei barge-in e valutazione della gestione dei turni
Timeline vocale a doppia traccia con rilevamento dei barge-in e valutazione della gestione dei turni
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5Le sovrapposizioni vengono calcolate dai tempi dei turni al momento del rendering, così una conversazione full-duplex che una trascrizione piatta appiattirebbe in "hanno detto entrambi delle cose" diventa un insieme di momenti concreti ed etichettabili.
Come do un punteggio al grounding temporale di un agente video?
La risposta di un agente video a "quando accade l'obiettivo?" è un intervallo, quindi le dai un punteggio come tale. Lo schema temporal_grounding ti offre uno scrubber dove segni il [start, end] gold per ogni prompt di evento, catturando la posizione di riproduzione o digitando i secondi. Quando i dati portano con sé l'intervallo previsto dal modello, una IoU dal vivo e una mini-timeline a due barre si aggiornano man mano che regoli (TimeScope, 2025).
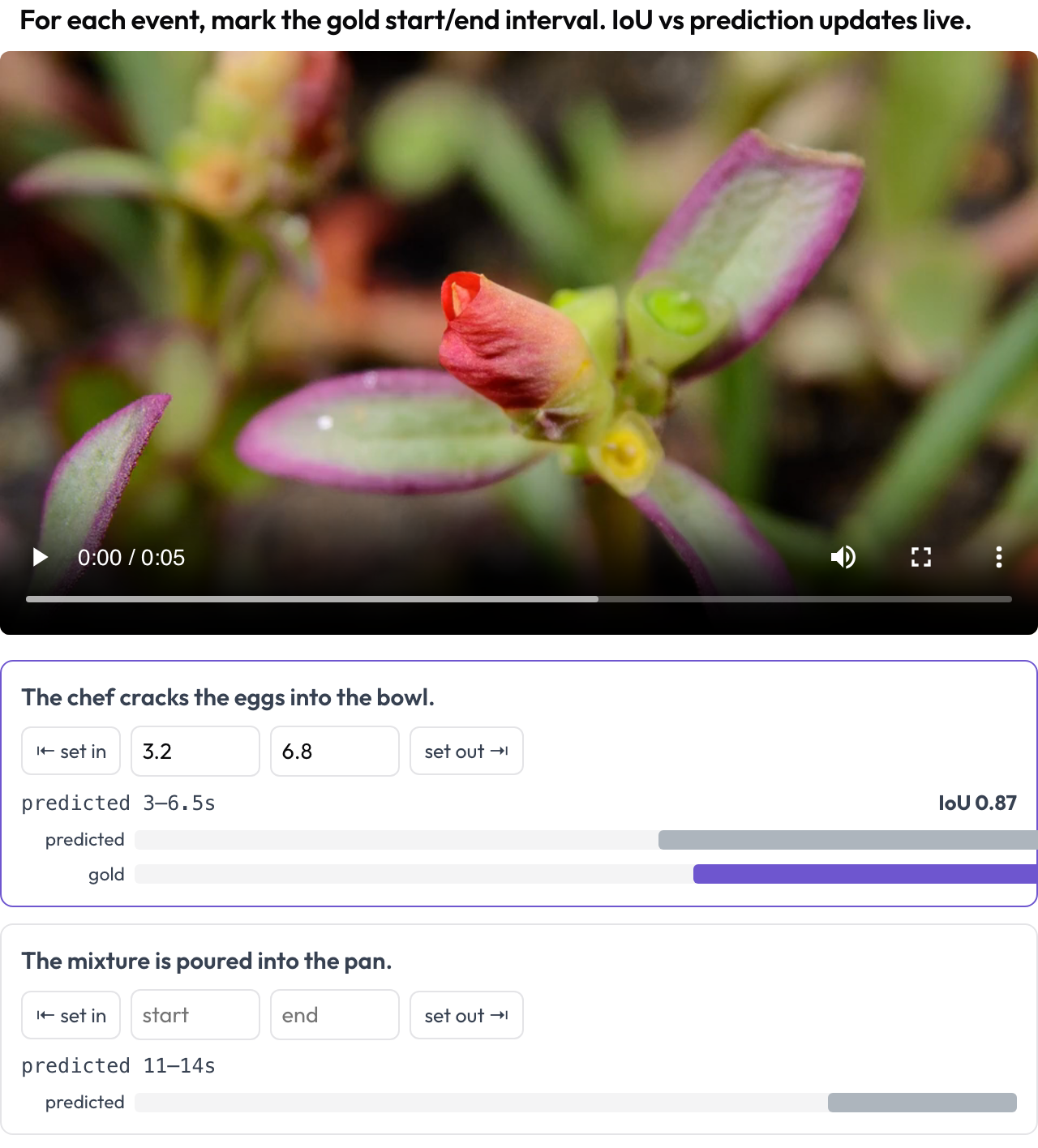 Segna gli intervalli gold degli eventi sul video con una IoU dal vivo rispetto alla previsione del modello
Segna gli intervalli gold degli eventi sul video con una IoU dal vivo rispetto alla previsione del modello
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsQuesto è costruito per la localizzazione previsto-contro-gold, che è un lavoro diverso dall'etichettatura generica di segmenti: stai valutando quanto è vicino lo span del modello alla verità, e vedere la IoU muoversi mentre trascini il confine rende tutto immediato.
E le trascrizioni del parlato, il ragionamento e le tabelle?
Altre tre superfici coprono il resto dello spettro multimodale:
- Trascrizioni del parlato (
speech_transcript): ogni segmento allineato nel tempo è una scheda; tagghi errori ASR/TTS, errori di pronuncia e disfluenze e correggi il testo inline (Speak & Improve, 2025). Questo è il complemento a livello di segmento della vista sulla gestione dei turni. - Ragionamento interlacciato (
multimodal_reasoning): una trace testo-immagine-strumento resa come blocchi tipizzati; valuti la coerenza di ogni passo e contrassegni le allucinazioni visive dove il ragionamento non segue dall'immagine (Multimodal RewardBench 2, 2025). - Tabelle documentali (
table_grid): imposti le dimensioni della griglia e clicchi le celle per marcarne il ruolo — dato, intestazione di colonna, intestazione di riga, vuota — catturando la struttura che i bounding box non possono.
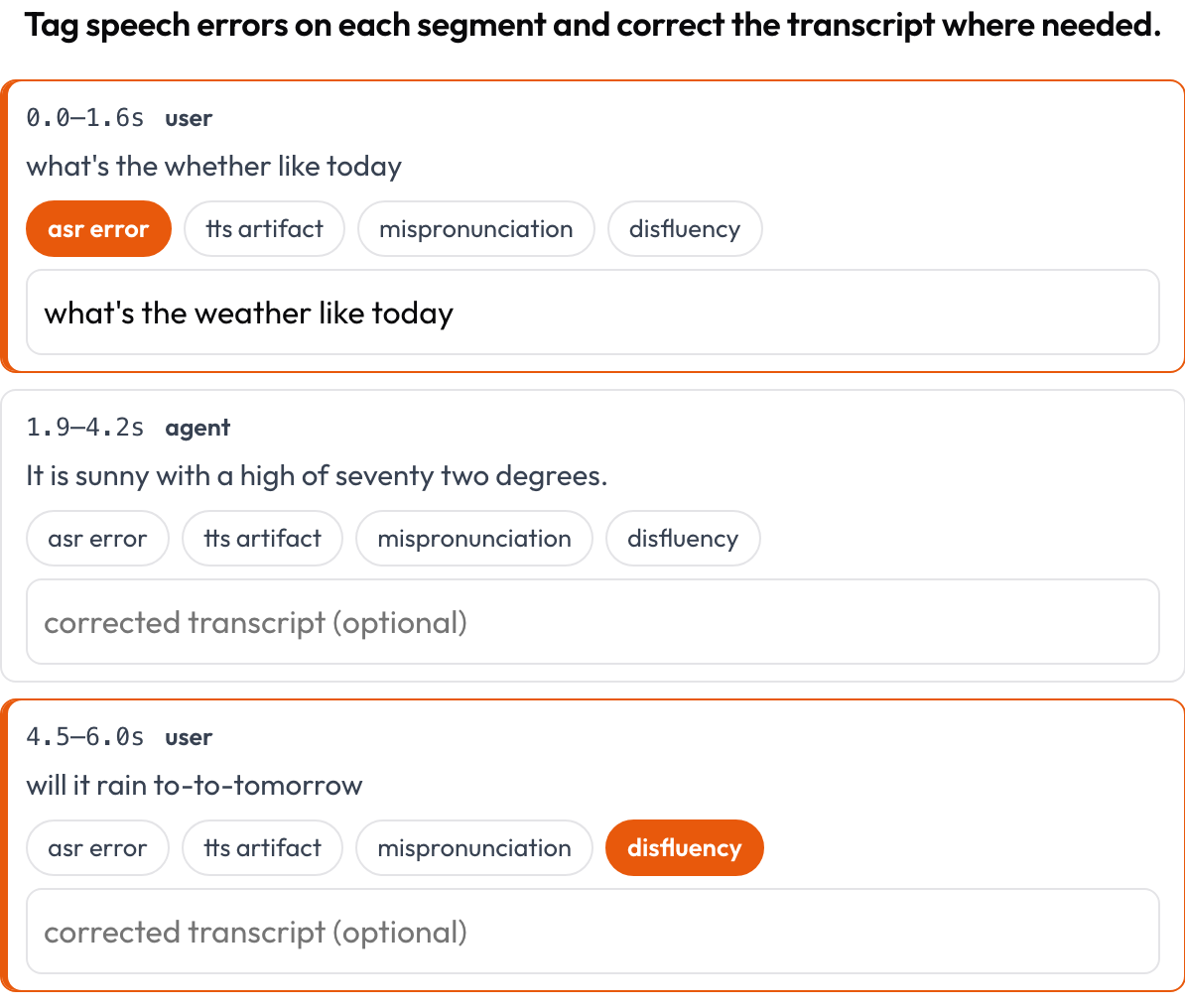 Tagga errori ASR/TTS/di pronuncia per segmento e correggi la trascrizione inline
Tagga errori ASR/TTS/di pronuncia per segmento e correggi la trascrizione inline
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true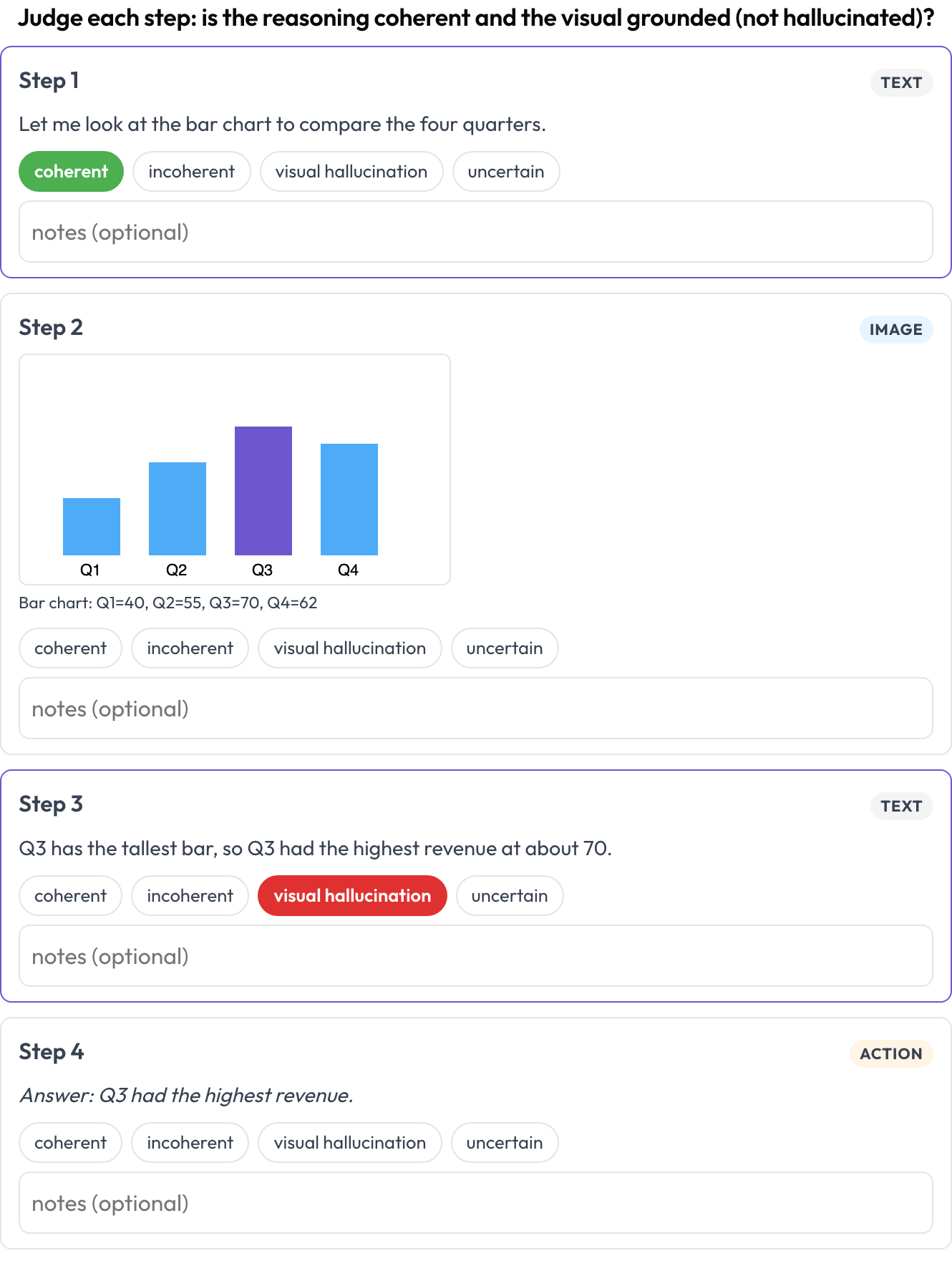 Valuta ogni passo di una trace di ragionamento testo-immagine-strumento per coerenza e allucinazione visiva
Valuta ogni passo di una trace di ragionamento testo-immagine-strumento per coerenza e allucinazione visiva
Diversi di questi schemi possono girare sullo stesso task, così una singola esecuzione di un agente documentale può essere valutata per struttura della tabella e coerenza del ragionamento contemporaneamente.
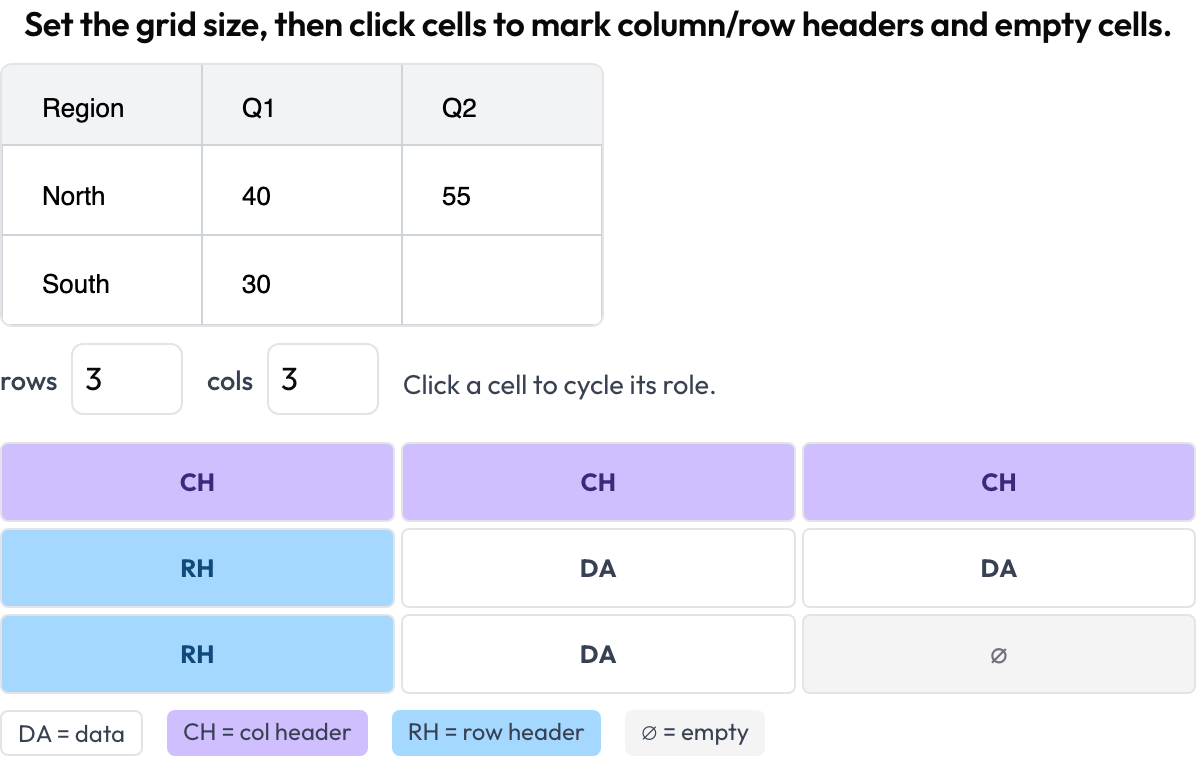 Annota la struttura delle celle delle tabelle documentali: intestazioni di colonna e riga, dati e celle vuote
Annota la struttura delle celle delle tabelle documentali: intestazioni di colonna e riga, dati e celle vuote
Come imposto tutto questo?
Ogni superficie è fornita con un esempio eseguibile sotto examples/agent-traces/:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000I tuoi dati si inseriscono come turni, segmenti o eventi con timestamp; la superficie deriva la sua timeline da essi al momento del rendering. Per agenti GUI e OS, il pezzo complementare è Valutare gli agenti per uso del computer.
Letture di approfondimento
- Valutazione di agenti multimodali — il riferimento completo agli schemi
- Valutare gli agenti per uso del computer e multimodali — la guida, con una tabella di selezione degli schemi
- Valutare gli agenti per uso del computer, passo dopo passo — la metà GUI e OS delle superfici multimodali
- Potato 2.6.2: una suite completa e open-source per la valutazione degli agenti — tutto ciò che è nella linea 2.6.x