Potato 2.6.2: una suite completa de evaluación de agentes de código abierto
La línea 2.6.x convierte a Potato en una plataforma de evaluación de agentes completa y gratuita: ingesta de trazas desde OpenTelemetry, LangGraph, CrewAI y AutoGen, anotación de equipos multiagente con un grafo de interacción interactivo, esquemas para agentes multimodales de GUI, voz y vídeo, además de una arena de modelos, gating en CI y curación.
Potato 2.6 trajo la primera ola de evaluación de agentes: calibración de LLM como juez, edición de trayectorias para datos de entrenamiento y la vista eval_trace de tres paneles. Las versiones puntuales 2.6.x posteriores completan el resto. A partir de la 2.6.2, Potato es una plataforma de evaluación de agentes completa: puedes capturar trazas de tus propios agentes, anotar agentes individuales, equipos multiagente y agentes multimodales, evaluarlos con LLM en los que puedes confiar, clasificar modelos en una arena y aplicar gating a las publicaciones en CI. Todo se configura en YAML y permanece en tu propio servidor.
 Evaluación multiagente de Potato
Evaluación multiagente de Potato
La mayoría de estas son capacidades por las que la gente paga actualmente a una plataforma alojada. Potato las ofrece gratis y autoalojadas. Esto es lo que llegó a lo largo de la línea 2.6.x.
 La suite de evaluación de agentes 2.6.x, de principio a fin
La suite de evaluación de agentes 2.6.x, de principio a fin
Trae las trazas: un SDK de captura y estándares abiertos
La evaluación empieza con ejecuciones reales. El nuevo SDK potato_trace instrumenta cualquier agente: decora una función con @traceable (síncrona o asíncrona) y las llamadas anidadas se capturan y se envían al endpoint de ingesta de Potato, con una exportación opcional a OpenTelemetry. Potato también ingiere spans de OpenTelemetry / OpenInference y los formatos de ejecución de LangGraph, CrewAI y AutoGen, de modo que las trazas del framework que ya usas llegan a la cola de anotación sin código de pegamento. Las nuevas trazas pueden llegar a través de un webhook, un poller o un directorio vigilado, y quedan asignables a los anotadores a medida que aparecen.
Referencia: SDK de trazado, Reglas de automatización.
Mira a todo el equipo: evaluación multiagente
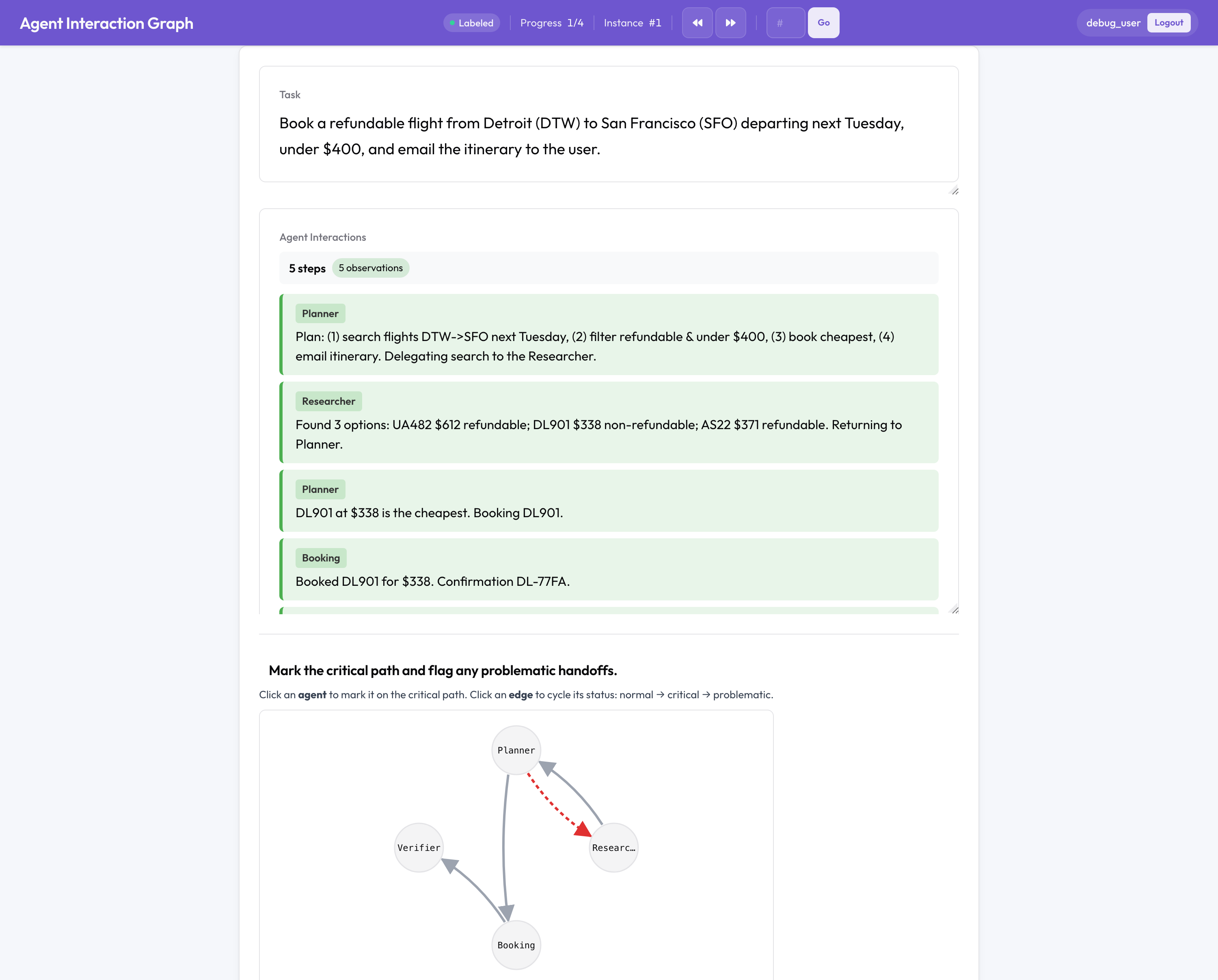
Esta es la parte sin equivalente de código abierto. Una ejecución multiagente falla de forma distinta a un agente individual: entre agentes, en un traspaso, en cómo se organizó el equipo, así que Potato anota la estructura del equipo en lugar de una transcripción plana:
- Un grafo de interacción interactivo de agentes y traspasos, donde marcas el camino crítico y señalas las aristas problemáticas.
- Atribución de fallos: elige el agente responsable, el paso decisivo y la razón, la tripleta (agente, paso, razón) procedente del trabajo de atribución Who&When.
- Revisión de traspasos: cada transferencia de control se convierte en una tarjeta para señalar desalineaciones entre agentes y valorar la calidad.
- Cuadros de mando por agente y por equipo: fidelidad al rol, contribución y coordinación por agente, además de dimensiones compartidas y hitos del equipo.
- Una línea de tiempo de contención de herramientas que saca a la luz interbloqueos y carreras donde varios agentes tocan el mismo recurso a la vez.
- Etiquetado de comportamiento emergente para colusión, pensamiento de grupo y errores en cascada que abarcan varios agentes y turnos.
 Atribución de fallos: qué agente, qué paso y por qué
Atribución de fallos: qué agente, qué paso y por qué
El conjunto completo, con su YAML para cada uno, está en Evaluación de equipos multiagente, y el análisis a fondo Depurando fallos multiagente recorre cada superficie de principio a fin. La guía Cómo evaluar sistemas multiagente cubre cuándo usar cada cual.
Más allá del texto: evaluación de agentes multimodales
Los agentes ahora manejan GUIs, ven vídeo y mantienen conversaciones habladas, y cada uno necesita una superficie de revisión que un widget de texto no puede ofrecer:
- Trayectorias de GUI / computer-use: captura de pantalla y acción por paso, un veredicto de la acción y un marcador de anclaje del clic que muestra si el clic cayó sobre el elemento correcto.
- Líneas de tiempo de voz full-duplex: una línea de tiempo de doble pista usuario/agente con detección de interrupciones (barge-in) y puntuación del turno de palabra.
- Anclaje temporal de vídeo: marca intervalos de eventos de referencia con un IoU en vivo frente al intervalo predicho por el modelo.
- Etiquetado de errores en transcripciones de habla, razonamiento multimodal intercalado con marcas de alucinación visual y estructura de cuadrícula de tablas de documentos.
 Revisión de computer-use: corrección de la acción más anclaje del clic
Revisión de computer-use: corrección de la acción más anclaje del clic
Dos análisis a fondo los recorren: Evaluando agentes de computer-use para agentes de GUI y de SO, y Evaluando agentes de voz y vídeo para agentes hablados, de vídeo y de documentos. La referencia es Evaluación de agentes multimodales, y la guía es Evaluando agentes de computer-use y multimodales.
Jueces en los que puedes confiar, y una arena
Usar un LLM para calificar salidas es algo rutinario; el trabajo de la 2.6.x consiste en saber hasta qué punto confiar en él. La calibración del juez ejecuta una pasada humana a ciegas contra las etiquetas del modelo e informa de la exactitud, la kappa y el Error de Calibración Esperado (ECE). La alineación del juez ajusta un único juez frente a tus etiquetas de referencia. Y los evaluadores programáticos puntúan trayectorias y texto automáticamente (coincidencia de trayectorias, corrección del uso de herramientas, LLM como juez sin referencia y heurísticas) sin necesidad de un servidor en ejecución.
Para la comparación cara a cara, la Arena de modelos envía un mismo prompt a varios modelos, recopila preferencias y construye una tabla de clasificación por tasa de victorias entre OpenAI, Anthropic, Gemini, Ollama y vLLM.
Trata la evaluación como software
Las piezas operativas hacen que la evaluación sea repetible:
- Conjuntos de datos y experimentos: conjuntos de evaluación versionados, splits y comparación de experimentos lado a lado con deltas de regresión.
- Evaluación en CI: un plugin de pytest que hace fallar la build cuando un cambio de prompt o de modelo provoca una regresión de la calidad del agente por debajo de un umbral.
- Reglas de automatización: encamina las trazas de producción entrantes hacia conjuntos de datos, evaluadores o la cola de anotación según reglas.
- Curación semántica: un índice de embeddings para "encuentra trazas como este fallo" y cortes dinámicos guardados.
Cómo obtenerlo
pip install --upgrade potato-annotationCada nueva superficie incluye un ejemplo ejecutable en examples/agent-traces/, incluidos interaction-graph/, failure-attribution/, gui-trajectory/ y temporal-grounding/. Apunta Potato a uno para ver el esquema en funcionamiento:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000Si estás sopesando herramientas, la comparación en Potato frente a LangSmith y Langfuse y la guía Herramientas de anotación de código abierto comparadas explican dónde encaja cada una. Las preguntas y los formatos de traza que deberíamos admitir son bienvenidos en el repositorio de GitHub.