Evaluando agentes de voz y vídeo
Un recorrido por la evaluación humana de agentes hablados, de vídeo y de documentos en Potato: puntuar el turno de palabra en una línea de tiempo de doble pista, anclar eventos de vídeo con IoU en vivo, etiquetar errores de habla y marcar la estructura de tablas.
Los agentes que hablan, ven vídeo y leen documentos fallan de maneras que una caja de texto no puede mostrar. Los errores de un agente de voz viven en las costuras entre turnos; la respuesta de un agente de vídeo es un intervalo de tiempo, no una frase; el error de un agente de documentos es una celda de tabla mal leída. Cada uno de ellos necesita una superficie de revisión moldeada a su modalidad. Potato añade cuatro de esas superficies — voz, vídeo, habla y documento — junto a sus vistas existentes de imagen y audio. La referencia completa es Evaluación de agentes multimodales.
 Un widget de texto plano no puede expresar una interrupción, un intervalo de evento o una celda de tabla
Un widget de texto plano no puede expresar una interrupción, un intervalo de evento o una celda de tabla
¿Cómo evalúo el turno de palabra de un agente de voz?
Los agentes hablados se rompen en los límites: cortando al usuario, hablando por encima de él o haciendo una pausa tan larga que el usuario se rinde. El esquema voice_interaction dispone la conversación como una línea de tiempo de doble pista — un carril de usuario y un carril de agente — y resalta las regiones de solapamiento donde ambos hablan a la vez (Full-Duplex-Bench, 2025). Clasificas cada solapamiento y valoras el turno de palabra en conjunto; el audio se reproduce en línea cuando se proporciona.
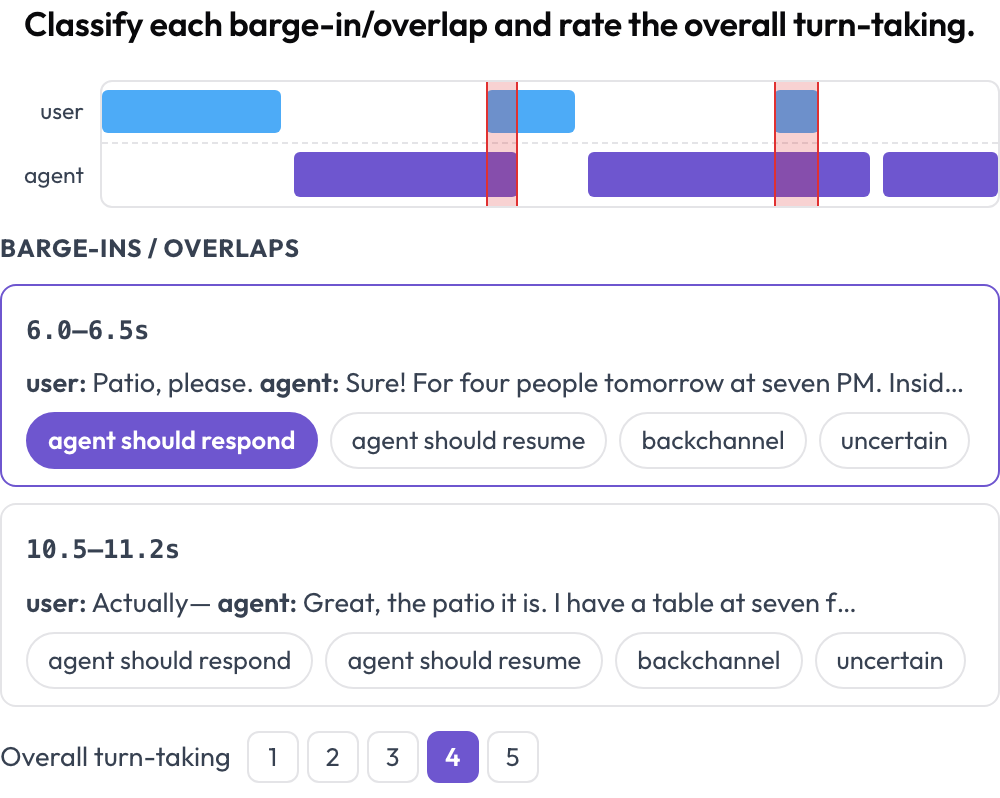 Línea de tiempo de voz de doble pista con detección de interrupciones y puntuación del turno de palabra
Línea de tiempo de voz de doble pista con detección de interrupciones y puntuación del turno de palabra
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5Los solapamientos se calculan a partir de los tiempos de los turnos en el momento de renderizar, así que una conversación full-duplex que una transcripción plana aplanaría en "ambos dijeron cosas" se convierte en un conjunto de momentos concretos y etiquetables.
¿Cómo puntúo el anclaje temporal de un agente de vídeo?
La respuesta de un agente de vídeo a "¿cuándo ocurre el objetivo?" es un intervalo, así que lo puntúas como tal. El esquema temporal_grounding te da un control de desplazamiento donde marcas el [start, end] de referencia para cada prompt de evento, capturando la cabeza de reproducción o escribiendo segundos. Cuando los datos llevan el intervalo predicho por el modelo, un IoU en vivo y una mini línea de tiempo de dos barras se actualizan a medida que ajustas (TimeScope, 2025).
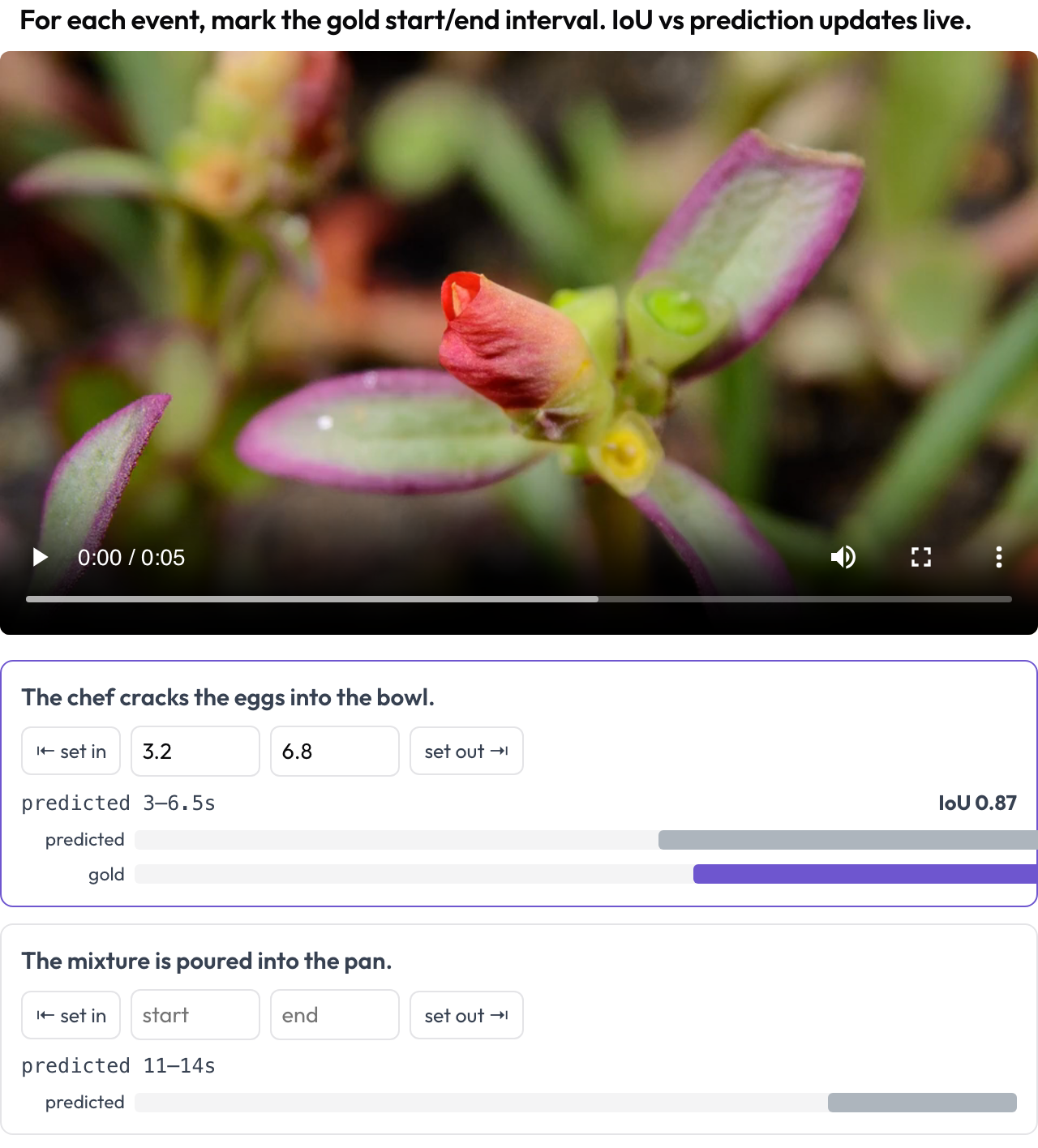 Marca intervalos de eventos de referencia sobre el vídeo con un IoU en vivo frente a la predicción del modelo
Marca intervalos de eventos de referencia sobre el vídeo con un IoU en vivo frente a la predicción del modelo
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsEsto está hecho para la localización predicha-frente-a-referencia, que es un trabajo distinto del etiquetado general de segmentos: estás puntuando cuán cerca está el tramo del modelo de la verdad, y ver el IoU moverse mientras arrastras el límite lo hace inmediato.
¿Y las transcripciones de habla, el razonamiento y las tablas?
Tres superficies más cubren el resto del abanico multimodal:
- Transcripciones de habla (
speech_transcript): cada segmento alineado en el tiempo es una tarjeta; etiquetas errores de ASR/TTS, malas pronunciaciones y disfluencias, y corriges el texto en línea (Speak & Improve, 2025). Este es el complemento a nivel de segmento de la vista del turno de palabra. - Razonamiento intercalado (
multimodal_reasoning): una traza texto-imagen-herramienta renderizada como bloques tipados; valoras la coherencia de cada paso y marcas las alucinaciones visuales donde el razonamiento no se desprende de la imagen (Multimodal RewardBench 2, 2025). - Tablas de documentos (
table_grid): fijas las dimensiones de la cuadrícula y haces clic en las celdas para marcar su rol — datos, encabezado de columna, encabezado de fila, vacía — capturando la estructura que los recuadros delimitadores no pueden.
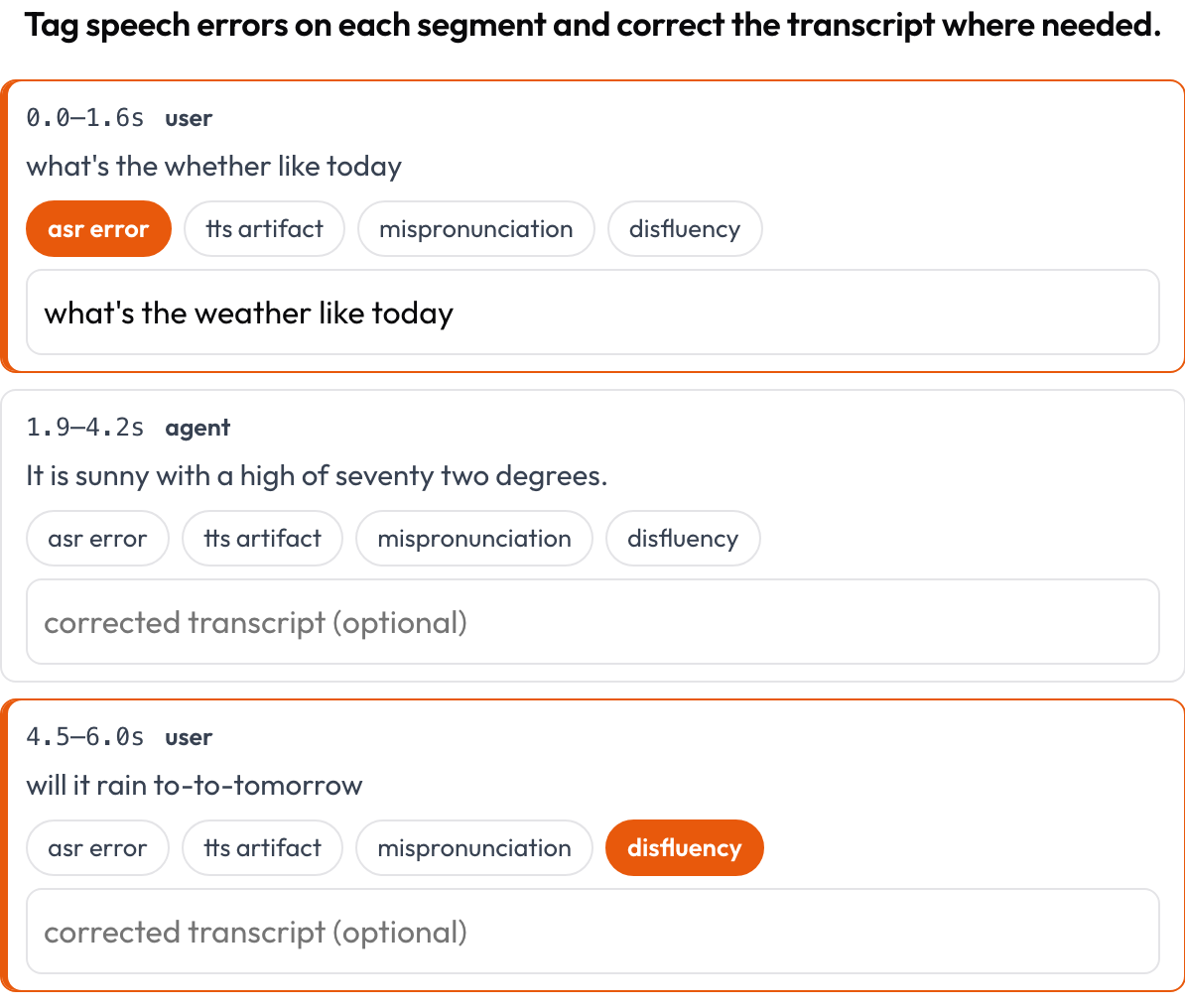 Etiqueta errores de ASR/TTS/pronunciación por segmento y corrige la transcripción en línea
Etiqueta errores de ASR/TTS/pronunciación por segmento y corrige la transcripción en línea
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true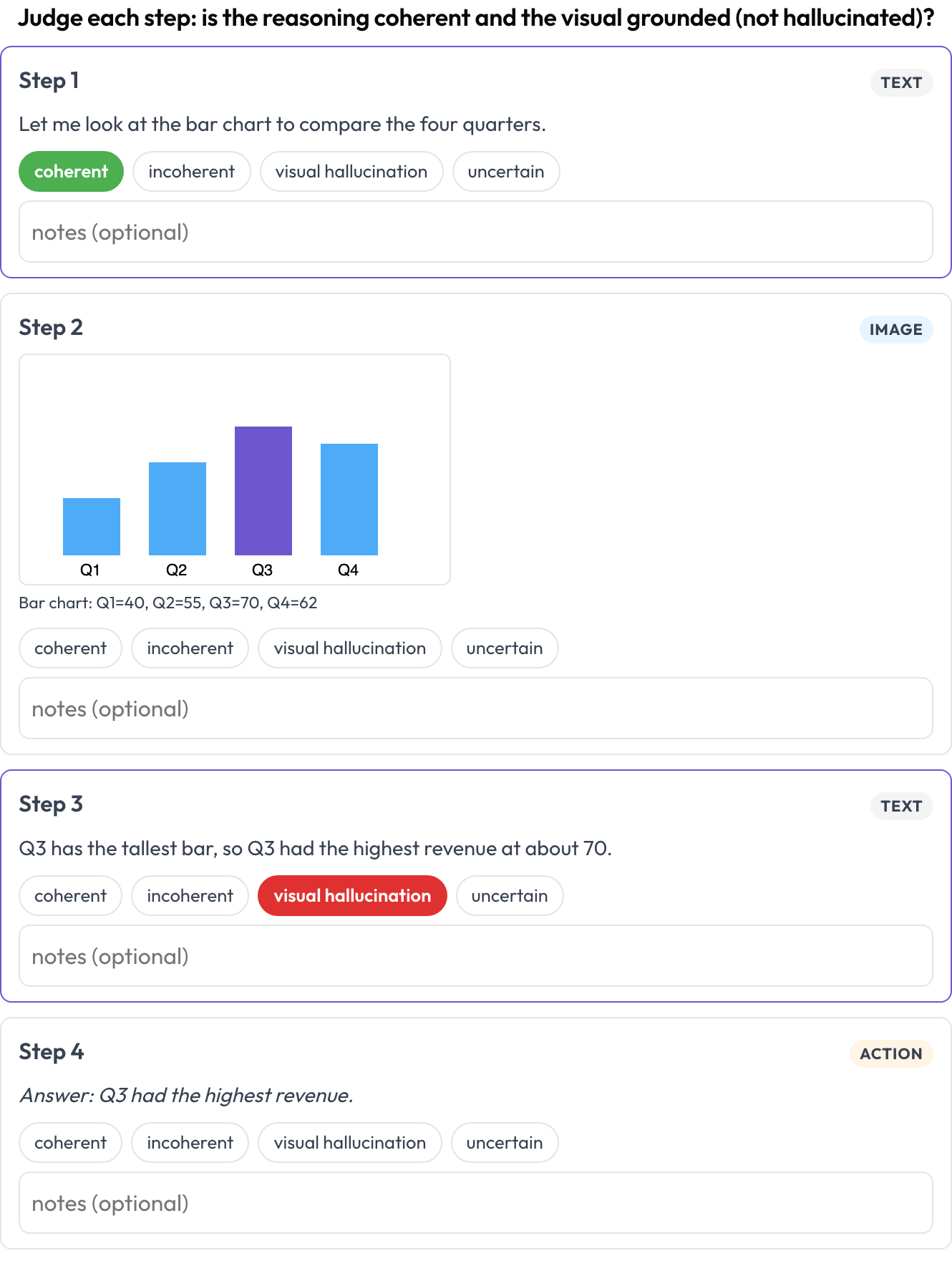 Valora cada paso de una traza de razonamiento texto-imagen-herramienta por coherencia y alucinación visual
Valora cada paso de una traza de razonamiento texto-imagen-herramienta por coherencia y alucinación visual
Varios de estos esquemas pueden ejecutarse en la misma tarea, así que una sola ejecución de un agente de documentos puede puntuarse por estructura de tabla y coherencia del razonamiento a la vez.
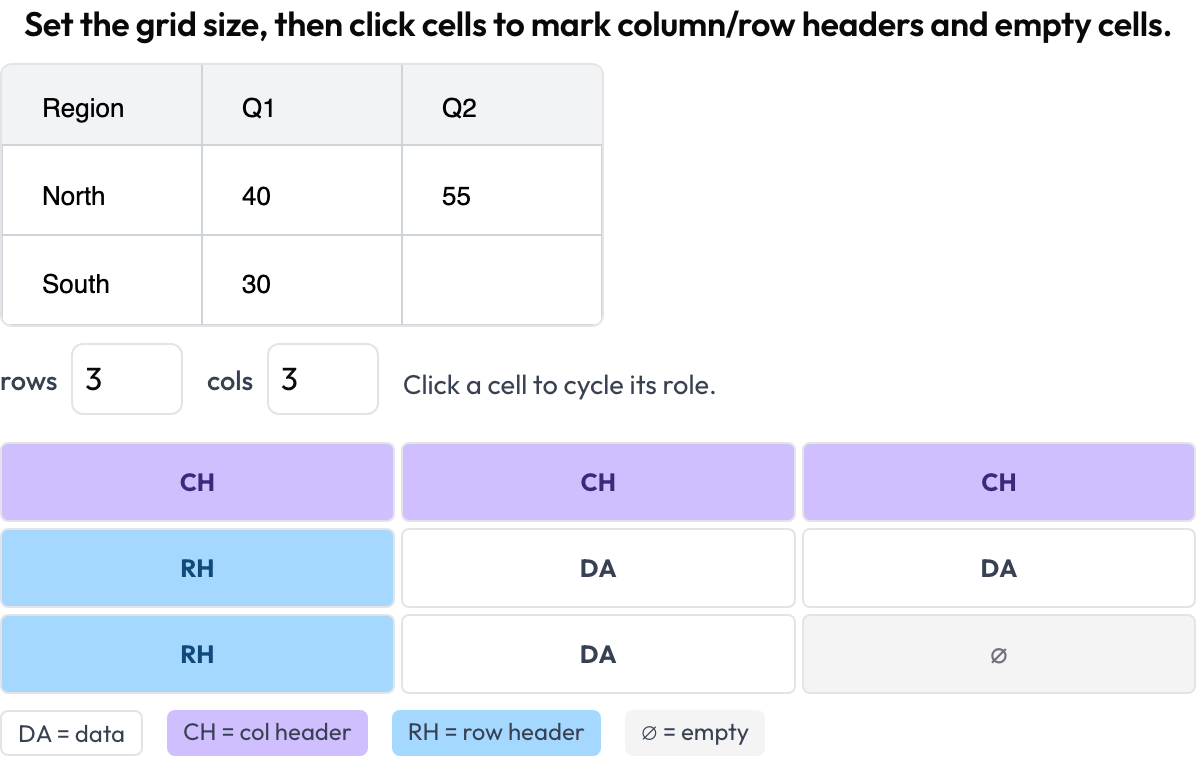 Anota la estructura de celdas de una tabla de documento: encabezados de columna y de fila, datos y celdas vacías
Anota la estructura de celdas de una tabla de documento: encabezados de columna y de fila, datos y celdas vacías
¿Cómo configuro esto?
Cada superficie incluye un ejemplo ejecutable en examples/agent-traces/:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000Tus datos se incorporan como turnos, segmentos o eventos con marcas de tiempo; la superficie deriva su línea de tiempo de ellos en el momento de renderizar. Para agentes de GUI y de SO, la pieza complementaria es Evaluando agentes de computer-use.
Lecturas adicionales
- Evaluación de agentes multimodales — la referencia completa del esquema
- Evaluando agentes de computer-use y multimodales — la guía, con una tabla de selección de esquemas
- Evaluando agentes de computer-use, paso a paso — la mitad de GUI y de SO de las superficies multimodales
- Potato 2.6.2: una suite completa de evaluación de agentes de código abierto — todo lo de la línea 2.6.x